
LlamaIndex v0.7 のしくみとカスタマイズ

以下の記事が面白かったので、軽くまとめました。
1. はじめに
「LlamaIndex」は、カスタムデータを使用してLLMを利用したアプリケーション (Q&A、チャットボット、エージェントなど) を構築するためのパッケージです。
この記事では、次の事柄を紹介します。
・LLMとカスタムデータを組み合わせるための「RAG」(Retrieval Augmented Generation) パラダイム
・独自のRAGパイプラインを構成するためのLlamaIndexの主な概念とモジュール
2. RAG (Retrieval Augmented Generation)
「RAG」(Retrieval Augmented Generation : 検索拡張生成) は、カスタムデータでLLMを拡張するためのパラダイムです。 通常、次の2段階で構成されます。
・インデックス作成 : 知識ベースの準備
・クエリ : 知識ベースから関連するコンテキストを取得して、LLMの質問応答をサポート
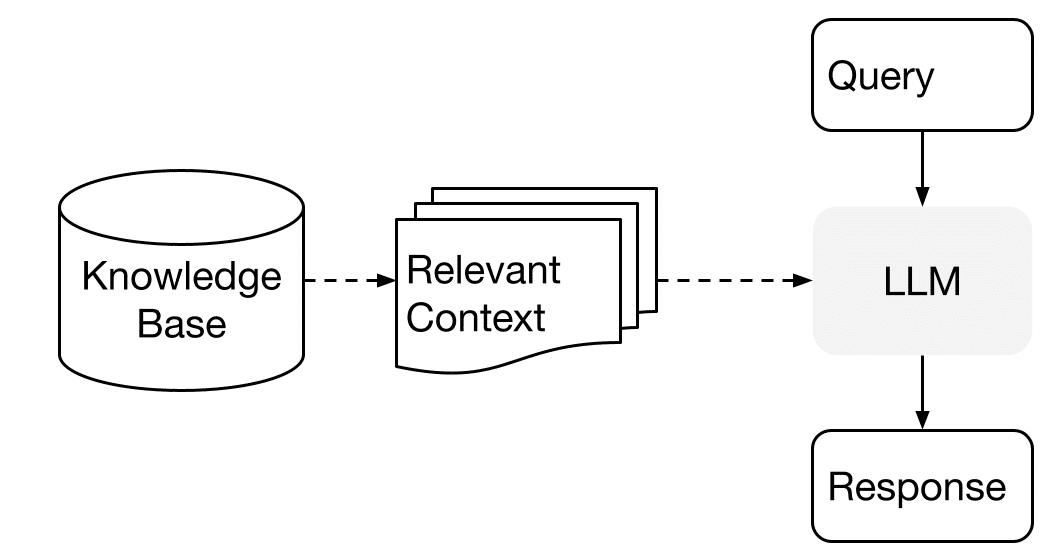
「LlamaIndex」は、両方の手順を非常に簡単にするための重要なツールキットを提供します。
3. インデックス作成
「LlamaIndex」は、「データコネクタ」と「インデックス」を使用して知識ベースを準備するのに役立ちます。

・データコネクタ : 「データコネクタ」 (リーダー) は、さまざまな「データソース」から「ドキュメント」 (テキストおよびメタデータ) に取り込みます。
・ドキュメント / ノード : 「ドキュメント」は、PDF、API 出力、データベースなど、あらゆる「データソース」の汎用コンテナです。「ノード」は 「LlamaIndex」内のデータの単位であり、ソースドキュメントの「チャンク」を表します。これは、メタデータと他のノードとの関係を含む豊富な表現であり、正確かつ表現力豊かな検索操作を可能にします。
・データインデックス : データを取り込んだら、「LlamaIndex」を使用して、データを簡単に取得できる形式にインデックス付けできます。 内部では、「LlamaIndex」は生のドキュメントを解析して中間表現にし、ベクトルの埋め込みを計算し、メタデータを推論します。最も一般的に使用されるインデックスは「VectorStoreIndex」です。
4. クエリ
「クエリ」では、RAGパイプラインはユーザークエリから最も関連性の高いコンテキストを取得し、それをクエリとともにLLM に渡して応答を作成します。 これにより、元の学習データにはない最新の知識がLLMに与えられます (ハルシネーションも軽減されます)。「クエリ」の主な課題は、知識ベースの検索、オーケストレーション (LLMが異なる要素を組み合わせて協調動作するプロセス)、推論です。
「LlamaIndex」は、Q&A (クエリエンジン)、チャットボット (チャットエンジン)、またはエージェントの一部としてRAGパイプラインを構築および統合するのに役立つ構成可能なモジュールを提供します。これらの構成要素は、ランキング設定を反映するようにカスタマイズしたり、構造化された方法で複数の知識ベースを推論するように構成したりできます。

4-1. ビルディングブロック
・リトリバー : 「リトリバー」は、クエリが与えられた時に知識ベース (インデックス) から関連するコンテキストを効率的に取得する方法を定義します。 具体的な検索ロジックはインデックスごとに異なり、最も一般的なのはベクトルインデックスに対する高密度検索です。
・ノードポストプロセッサ : 「ノードポストプロセッサ」はノードのセットを取り込み、それらに変換、フィルタリング、再ランク付けロジックを適用します。
・レスポンスシンセサイザー : 「レスポンスシンセサイザー」は、ユーザー クエリと取得されたテキストチャンクの指定されたセットを使用して、LLM からのレスポンスを生成します。
4-2. パイプライン
・クエリエンジン : 「クエリエンジン」は、データに対して質問できるようにするエンドツーエンドのパイプラインです。自然言語クエリを受け取り、取得してLLMに渡した参照コンテキストとともにレスポンスを返します。
・チャットエンジン : 「チャットエンジン」は、データと会話するためのエンドツーエンドのパイプラインです。単一の質問と回答ではなく、複数のやり取りになります。
・エージェント : 「エージェント」は、一連のツールを介して世界と対話する、自動化された意思決定者です。 エージェントは、クエリエンジンやチャット エンジンと同じ方法で使用できます。 主な違いは、エージェントが事前に決定されたロジックに従うのではなく、最適な行動のシーケンスを動的に決定することです。 これにより、より複雑なタスクに取り組むためのさらなる柔軟性が得られます。
5. カスタマイズチュートリアル
「starter example」をベースにカスタマイズ方法を紹介します。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)5-1. ドキュメントを小さなチャンクに分割して解析したい
「ServiceContext」の chunk_size でチャンクサイズを指定できます。
from llama_index import ServiceContext
service_context = ServiceContext.from_defaults(chunk_size=1000)from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context
)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)5-2. 別のベクトルストアを使用したい
「StorageContext」の vector_store でベクトルストアを指定できます。
import chromadb
from llama_index.vector_stores import ChromaVectorStore
from llama_index import StorageContext
chroma_client = chromadb.Client()
chroma_collection = chroma_client.create_collection("quickstart")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)5-3. クエリ時により多くのコンテキストを取得したい
index.as_query_engine() の similarity_top_k で、取得するコンテキストの個数 (デフォルトは2) を指定できます。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("What did the author do growing up?")
print(response)5-4. 別のLLMを使用したい
「ServiceContext」の llm でLLMを指定できます。
from llama_index import ServiceContext
from llama_index.llms import PaLM
service_context = ServiceContext.from_defaults(llm=PaLM())from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(service_context=service_context)
response = query_engine.query("What did the author do growing up?")
print(response)5-5. 別のレスポンスモードを使用したい
index.as_query_engine() の response_mode でレスポンスモードを指定できます。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(response_mode='tree_summarize')
response = query_engine.query("What did the author do growing up?")
print(response)response_mode は、次のとおり。
・default : 取得した各回答を順番に調べて回答を「create & refine」。ノード毎に別々のLLMコールを行う。より詳細な答えに適している。
・compact : LLM呼び出しのたびに、プロンプトの最大サイズに収まるだけのノードのテキストチャンクを詰め込んで、プロンプトを「compact」にする。1つのプロンプトに詰め込むにはチャンクが多すぎる場合は、複数のプロンプトを通して答えを「create & refine」。
・tree_summarize : ノードオブジェクトのセットとクエリが与えられた場合、再帰的にツリーを構築し、ルートノードをレスポンスとして返す。要約に適している。
・no_text : LLMに送信されたであろうノードをフェッチするためにretrieverのみを実行。その後、response.source_nodesをチェックすることで検査できる。
・accumulate : オードオブジェクトのセットとクエリが与えられた場合、各ノードテキスト・チャンクにクエリを適用し、レスポンスを配列に蓄積する。すべてのレスポンスを連結した文字列を返す。各テキスト・チャンクに対して同じクエリを個別に実行する必要がある場合に適している。
5-6. レスポンスをストリーミングして返したい
index.as_query_engine() の streaming でレスポンスをストリーミングで返すことができます。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(streaming=True)
response = query_engine.query("What did the author do growing up?")
response.print_response_stream()5-7. Q&A ではなくチャットボットが使いたい
index.as_chat_engine() でチャットボットとして利用できます。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_chat_engine()
response = query_engine.chat("What did the author do growing up?")
print(response)
response = query_engine.chat("Oh interesting, tell me more.")
print(response)この記事が気に入ったらサポートをしてみませんか?