
Chatbot Arena - Eloを使用したLLMベンチマーク

以下の記事が面白かったので、軽くまとめました。
1. Chatbot Arena
「Chatbot Arena」は、大規模言語モデル (LLM) のベンチマークです。クラウドソーシングによる匿名のランダム化された戦闘を特徴としています。この記事では、「Chatbot Arena」の最初の結果と、チェスなどの対戦ゲームで広く使用されている評価システム「Elo」をもとにしたリーダーボードを公開しています。
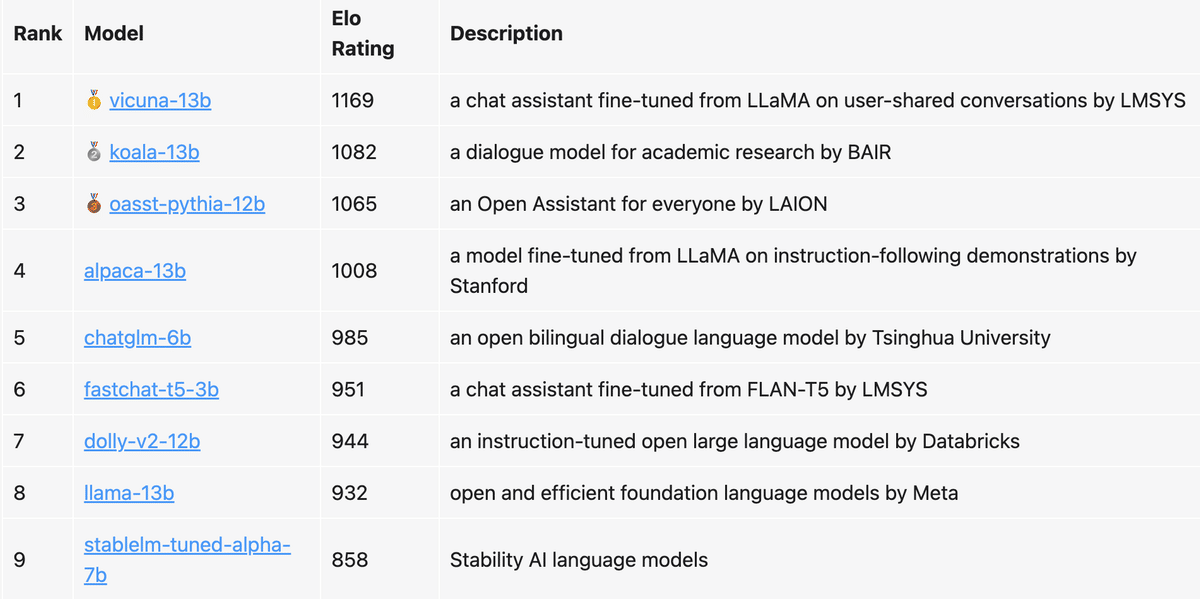
表1 は、このノートブックで共有されている 4.7Kの投票データをもとにした、、9つの人気モデルの「Elo」を示しています。
2. Chatbot Arenaの紹介
「ChatGPT」の大成功に続いて、Instructionファインチューニングされたオープンソースの大規模言語モデルが急増しています。LLaMAベースの「Alpaca」「Vicuna」や、Pythiaベースの「OpenAssistant」「Dolly」などがあります。
毎週新しいモデルが絶え間なくリリースされているにもかかわらず、コミュニティはこれらのモデルを効果的にベンチマークするという課題に直面しています。LLMのベンチマークは非常に困難です。これは問題が無限であり、応答品質を自動評価するプログラムを作成するのが非常に難しいためです。 この場合、通常、ペアワイズ比較に基づく人間評価に頼る必要があります。
ペアワイズ比較に基づく優れたベンチマークには、いくつかの望ましい特性があります。
・Scalability : 考えられる全てのモデルペアについて十分なデータを収集することが現実的でない場合、多数のモデルに拡張する必要があります。
・Incrementality : 比較的少ない試行回数で新しいモデルを評価できる必要があります。
・Unique order : 全てのモデルに対して一意の順序を提供する必要があります。任意の 2 つのモデルが与えられた場合、どちらのランクが高いか、またはそれらが同点かどうかを判断できるはずです。
既存のLLMベンチマークがこれらを全て満たすことは、ほぼありません。「HELM」や「lm-evaluation-harness」などの古典的なLLMベンチマークは、学術研究で一般的に使用されるタスクのマルチメトリック測定を提供します。ただし、それらはペアワイズ比較にもとづいていないため、自由回答式の質問の評価には適していません。OpenAI は、より良い質問を収集するために「Evals」も開始しましたが、これは参加している全てのモデルのランキングを提供するわけではありません。「Vicuna」を立ち上げたとき、GPT-4ベースの評価パイプラインを利用しましたが、それはスケーラブルで段階的な評価のためのソリューションを提供しません。
「Chatbot Arena」は、チェスなどの対戦ゲームで広く使用されている評価システム「Elo」を採用しています。 「Elo」は上記の特性を満たします。
データ収集するために、1週間前にいくつかの人気のあるオープンソースLLMでアリーナを立ち上げました。 アリーナでは、ユーザーは2人の匿名モデルと並んでチャットし、どちらが優れているかを投票できます。 このクラウドソーシングによるデータ収集の方法は、LLMの実際の使用例を表しています。

3. データコレクション
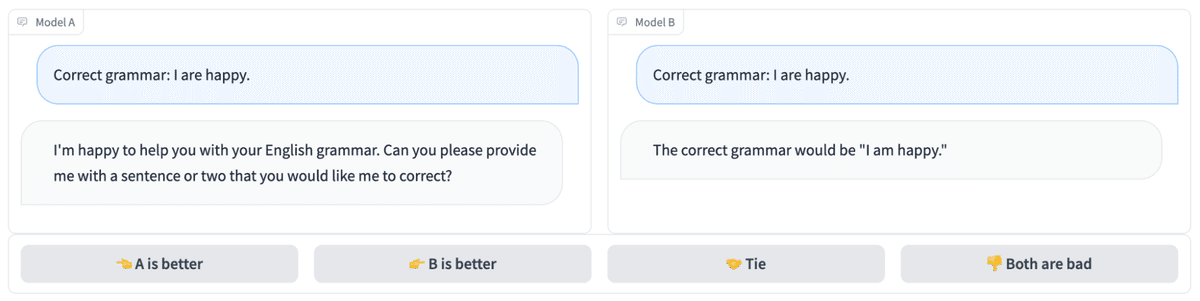
マルチモデルのサービス提供システム「FastChat」を使用して、アリーナを https://arena.lmsys.org でホストしています。 ユーザーがアリーナに入ると、図1 のように、2つの匿名モデルを並べてチャットできます。2つのモデルから応答を得た後、ユーザーはチャットを続けるか、より優れていると思われるモデルに投票できます。 投票が送信されると、モデル名が明らかになります。

図2 は、モデルの組み合わせごとの戦闘回数です。トーナメントを最初に立ち上げたとき、ベンチマークに基づいた可能性の高いランキングに関する事前情報があり、このランキングに従ってモデルをペアリングすることを選択しました。このランキングにもとづいて、強力なペアリングであると思われるものを優先しました。ただし、ランキングの全体的なカバレッジを向上させるために、後で均一なサンプリングに切り替えました。トーナメントの終わりに向けて、新しいモデル「fastchat-t5-3b」も追加しました。
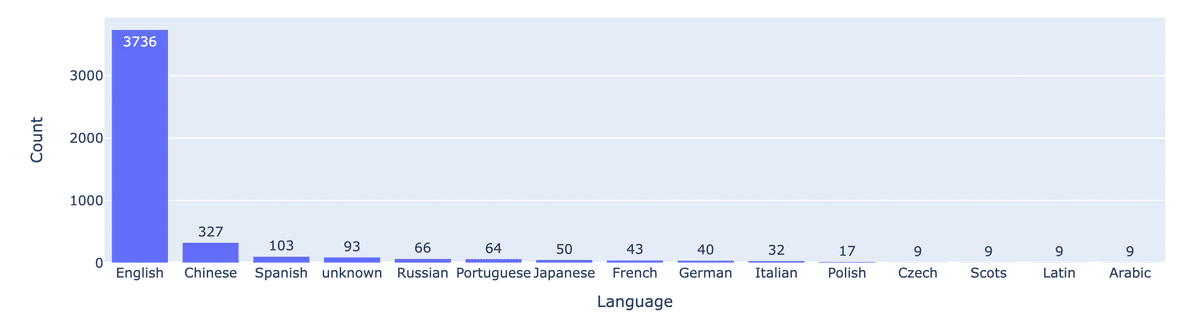
図3 は言語分布をプロットしたもので、ほとんどのユーザープロンプトが英語であることを示しています。
4. Elo
「Elo」は、競技ゲームやスポーツで広く採用されている、プレーヤーの相対的なスキルレベルを計算する方法です。2人のプレイヤー間の評価の差は、試合結果の予測因子として機能します。
プレーヤーAのーティングが Ra で、プレーヤーBのレーティングが Rb の場合、プレーヤー A が勝つ確率の正確な式 (基数10のロジスティック曲線を使用) は次のとおりです。

プレイヤーのレーティングは、各戦闘後に直線的に更新できます。プレーヤー A (レーティングRa) がEaポイントを獲得することが期待されていたが、実際にはSaポイントを獲得したとします。そのプレイヤーのレーティングを更新するための式は次のとおりです。

5. ペアワイズ勝率
キャリブレーションの基礎として、トーナメントの各モデルのペアワイズ勝率 (図4) と、「Elo」を使用したペアワイズ勝率の予測 (図5) も示します。 数値を比較すると、「Elo」が勝率を比較的よく予測できることがわかります。


6. 今後の計画
今後は以下の計画が予定されています。
・クローズモデルを追加 (ChatGPT-3.5が匿名アリーナで利用可能になりました)
・オープンソース モデルをさらに追加
・定期的に更新されるリーダーボードをリリースします (例: 毎月)
・より多くのモデルをサポートするために、より優れたサンプリングアルゴリズム、トーナメントメカニズム、サービス提供システムを実装
・様々なタスク種別できめ細かいランキングを提供
この記事が気に入ったらサポートをしてみませんか?