
FalconMamba 7B の概要

以下の記事が面白かったので、簡単にまとめました。
・Welcome FalconMamba: The first strong attention-free 7B model
1. Falcon Mamba
「Falcon Mamba」は、「Abu Dhabi」の「TII」(Technology Innovation Institute) が 「TII Falcon License 2.0」に基づいてリリースした新しいモデルです。このモデルはオープンであり、HuggingFaceで誰でも研究やアプリ目的で使用できます。
2. 最初の大規模Mambaモデル
「Transformer」は、現在最も強力なLLMで使用されている主要なアーキテクチャです。しかし、シーケンス長に応じて計算コストとメモリコストが増加するため、アテンションメカニズムは大規模シーケンスの処理には限界があります。さまざまな代替アーキテクチャ、特に状態空間言語モデル (SSLM) は、シーケンスのスケーリング制限に対処しようとしましたが、SoTA Transformerに比べて性能が低下しました。
「Falcon Mamba」を使用すると、性能を低下させることなくシーケンスのスケーリング制限を克服できることが実証されます。「Mamba: Linear-Time Sequence Modeling with Selective State Spaces」で提案されたオリジナルの「Mamba」アーキテクチャに基づいており、大規模な学習を安定して実行できるようにRMS正規化レイヤーが追加されています。このアーキテクチャの選択により、「Falcon Mamba」は次のことを保証します。
・メモリ容量を増やすことなく、任意の長さのシーケンスを処理できる。
特に、単一の A10 24GB GPU に収まる
・コンテキストのサイズに関係なく、新しいトークンを生成するのに一定の時間がかかる
3. モデル学習
「Falcon Mamba」は、RefinedWebを中心に、高品質の技術データと公開ソースからのコードデータを加えた約 5500GT のデータで学習されました。学習の大部分では一定の学習率を使用し、その後比較的短い学習率減衰段階を使用しました。この最後の段階では、モデルの性能をさらに向上させるために、少量の高品質のキュレーションデータも追加しました。
4. 評価
「lm-evaluation-harness」を使用してモデルを評価しました。
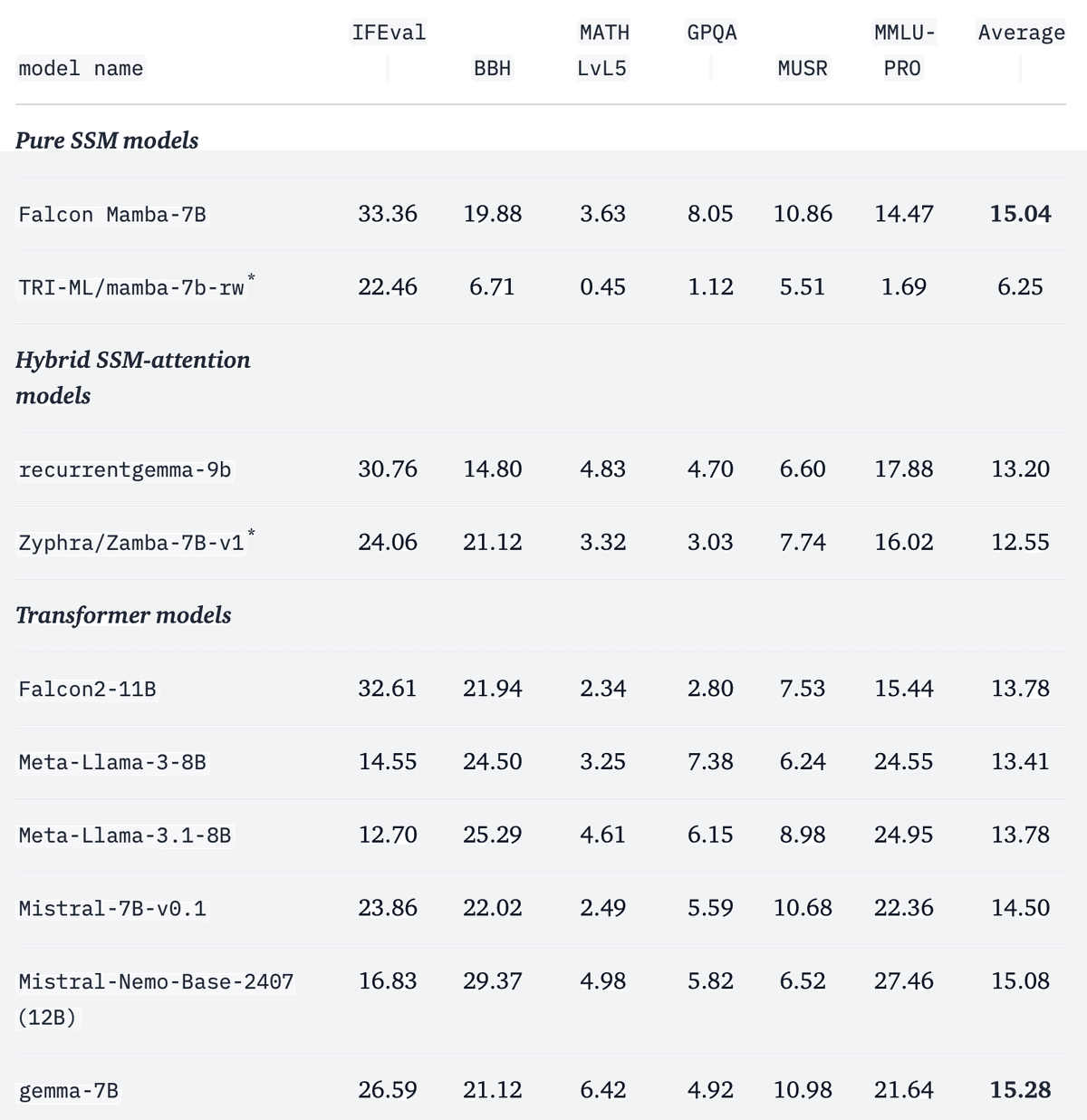
「lighteval」でも評価しました。

*が付いたモデルについては、タスクを社内で評価しましたが、**が付いたモデルについては、結果は論文またはモデルカードから取得されました。
5. 大規模シーケンスの処理
大規模シーケンスの処理におけるSSMモデルの理論的な効率に従い、「Falcon Mamba」と一般的なTransformerモデルとの間で、optimum-benchmarkを用いたメモリ使用量と生成スループットの比較を行います。公平な比較のために、すべてのTransformerモデルの語彙サイズを「Falcon Mamba」に合わせて変更しました。
結果に進む前に、まずシーケンスのプロンプト (事前入力) 部分と生成 (デコード) 部分の違いについて説明します。事前入力の詳細は、Transformerモデルよりも状態空間モデルの方が重要です。Transformerが次のトークンを生成するとき、コンテキスト内のすべての以前のトークンのキーと値に注意を払う必要があります。これは、メモリ要件と生成時間の両方がコンテキストの長さに応じて線形にスケーリングされることを意味します。状態空間モデルは、その反復状態のみに注意を払って保存するため、大規模シーケンスを生成するために追加のメモリや時間を必要としません。これは、デコードステージでSSMがTransformerよりも優れていると主張されている利点を説明していますが、prefillステージでは、SSMアーキテクチャを完全に活用するために追加の作業が必要です。
prefillの標準的なアプローチは、プロンプト全体を並列処理してGPUを完全に活用することです。このアプローチは、optimal-benchmarkで使用されており、並列prefillと呼びます。並列prefillでは、プロンプト内の各トークンの非表示状態をメモリに保存する必要があります。Transformerの場合、この追加メモリの大部分は、保存されたKVキャッシュのメモリによって占められます。SSMの場合、キャッシュは必要なく、非表示状態を保存するためのメモリがプロンプトの長さに比例する唯一のコンポーネントになります。その結果、メモリ要件はプロンプトの長さに応じて増加し、SSMはTransformerと同様に任意の長いシーケンスを処理する能力を失います。
並列prefillの代替手段は、プロンプトをトークンごとに処理することです。これをシーケンシャルprefillと呼びます。シーケンス並列処理と同様に、GPUの使用率を向上させるために、個々のトークンではなくプロンプトのより大きなチャンクで実行することもできます。シーケンシャルprefillはTransformerにはあまり意味がありませんが、SSMで任意の長いプロンプトを処理できる可能性が復活します。
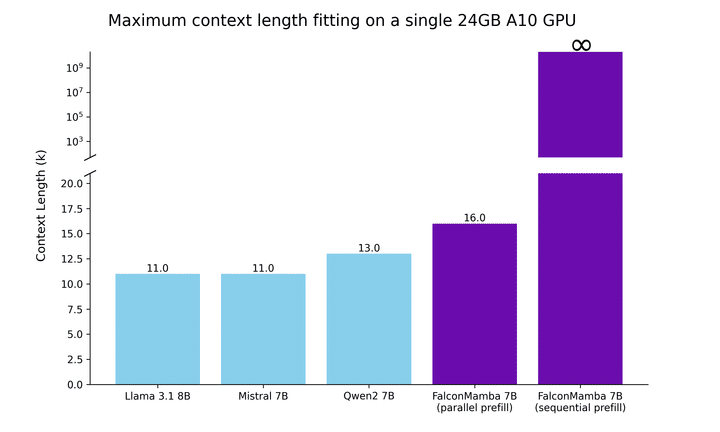
これらの点を念頭に置いて、まず単一の24GB A10 GPUに収まる最大のシーケンス長をテストし、その結果を下の図に示します。バッチサイズは1に固定され、float32精度を使用しています。並列prefillの場合でも、「Falcon Mamba」はTransformerよりも大きなシーケンスを適合させることができますが、シーケンシャルprefillではその潜在能力を最大限に発揮し、任意の長いプロンプトを処理できます。
次に、バッチサイズ1とH100 GPUを使用して、長さ1のプロンプトと最大130,000個のトークンを生成する設定で生成スループットを測定します。結果は下図に示されています。「Falcon Mamba」は、CUDAピークメモリの増加なしに、一定のスループットですべてのトークンを生成していることがわかります。Transformerモデルの場合、生成されるトークンの数が増えるにつれて、ピークメモリが増加し、生成速度が低下します。

6. Hugging Face Transformersでの使い方
「Falcon Mamba」は、「HuggingFace Transformers」の次のリリース (>4.45.0) で利用可能になります。モデルを使用するには、最新バージョンの 「HuggingFace Transformers」をインストールするか、ソースからライブラリをインストールしてください。
「Falcon Mamba」は、AutoModelForCausalLMやパイプラインなど、HuggingFaceが提供する使い慣れたAPIのほとんどと互換性があります。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map="auto")
inputs = tokenizer("Hello world, today", return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=100, do_sample=True)
print(tokenizer.decode(Output[0], skip_special_tokens=True))モデルが大きいため、より小さなGPUメモリでモデルを実行するために、bitおよびbyte量子化などの機能もサポートされています。
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config)
inputs = tokenizer("Hello world, today", return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=100, do_sample=True)
print(tokenizer.decode(output[0], skip_special_tokens=True))また、「Falcon Mamba」の指示チューニング版も紹介いたします。このバージョンは、追加の5Bの教師ありファインチューニング (SFT) データでファインチューニングされています。この拡張学習により、モデルの指示タスクをより正確かつ効果的に実行する能力が強化されます。こちらのデモで、指示モデルの機能を体験できます。チャットテンプレートでは、次の形式を使用します。
<|im_start|>user
prompt<|im_end|>
<|im_start|>assistantベース モデルと指示モデルの両方の 4 ビット変換バージョンを直接使用することもできます。量子化モデルを実行するには、bitsandbytesと互換性のあるGPUにアクセスできることを確認してください。
torch.compileを使用すると推論が高速化されるというメリットもあります。モデルをロードしたら、model = torch.compile(model) を呼び出すだけです。
この記事が気に入ったらサポートをしてみませんか?