
SimPLe : Atariゲームのモデルベースの強化学習

以下の記事が面白かったので、ざっくり訳してみました。
・Simulated Policy Learning in Video Models
1. はじめに
「深層強化学習」は、視覚的な入力から複雑なタスクのポリシーを学習するために使用でき、Atariゲームで大きな成功を収めています。しかし、多くの最先端のアプローチには、『環境との非常に多くの対話が必要』という制限があります。人間が学習するために必要な対話よりもはるかに多くの対話が必要になります。
人々がこれらのタスクを効率的に学習する理由を説明する仮説は、『自分の行動の効果を予測できるため、行動シーケンスが望ましい結果につながるモデルを暗黙的に学習できる』ことです。このようにゲームのモデルを構築し、それを使用して行動を選択するための適切なポリシーを学習することを、「モデルベースの強化学習」(MBRL)と呼びます。
論文「Atariゲームのモデルベースの強化学習」では、現在の最先端の技術よりも効率的にAtariゲームを攻略するモデルベースの強化学習フレームワーク「SimPLe」(Simulated Policy Learning)を紹介しています。
ゲーム環境との最大10万回の対話(人による約2時間のリアルタイムプレイに相当)のみを使用してAtariゲームを学習することを示します。さらに、オープンソースライブラリ「tensor2tensor」の一部としてコードを公開しました。このリリースには、シンプルなコマンドラインで実行でき、Atariゲームのようなインターフェイスを使用して再生できる、事前訓練済みの「世界モデル」が含まれています。
2. SimPLeの世界モデルの学習
「SimPLe」の主要なアイディアは、ゲームの振る舞いの「世界モデル」を学習することと、「世界モデル」(学習シミュレータ)内でポリシーを学習すること(モデルフリーの強化学習)を交互に行うことです。このアルゴリズムの基本原則は十分に確立されており、最近の多くのモデルベースの強化学習方法で採用されています。

SimPLeのメインループ。
(1)エージェントは実際の環境との対話を開始。
(2)収集された観察は、現在の「世界モデル」を更新するために使用。
(3)エージェントは、「世界モデル」内で学習することでポリシーを更新。
Atariゲームを訓練するには、まずピクセル空間でもっともらしい未来を生成する必要があります。言い換えれば、既に観察されたフレームのシーケンスと「左」「右」などのコマンドを入力として、次のフレームがどのように見えるかを予測しようとします。観察空間で「世界モデル」を訓練する理由は、密で豊富な観察シグナルを生成するためです。
そのようなモデル(ビデオ予測)の訓練に成功した場合、それは優れたポリシーを訓練するための軌跡を生成できる「学習シミュレータ」になります。これによって、エージェントの長期報酬が最大化されます。言い換えれば、時間と計算の両方で非常に集中する実際のゲームのシーケンスでポリシーを訓練する代わりに、「学習シミュレータ」(世界モデル)から来るシーケンスでポリシーを訓練します。
私たちの「世界モデル」は、4つのフレームを取り込んで、次のフレームと報酬を予測するフィードフォワード畳み込みネットワークです。ただし、Atariゲームの場合、前の4つのフレームの水平線のみを考えると、未来は非決定的です。たとえば、「Pong」でボールがフレームから外れた場合など、ゲームで4フレームより長いポーズをすると、モデルが後続のフレームを正常に予測できなくなる可能性があります。このような確率的問題は、以前の研究に触発された、新しいビデオモデルアーキテクチャで処理します。
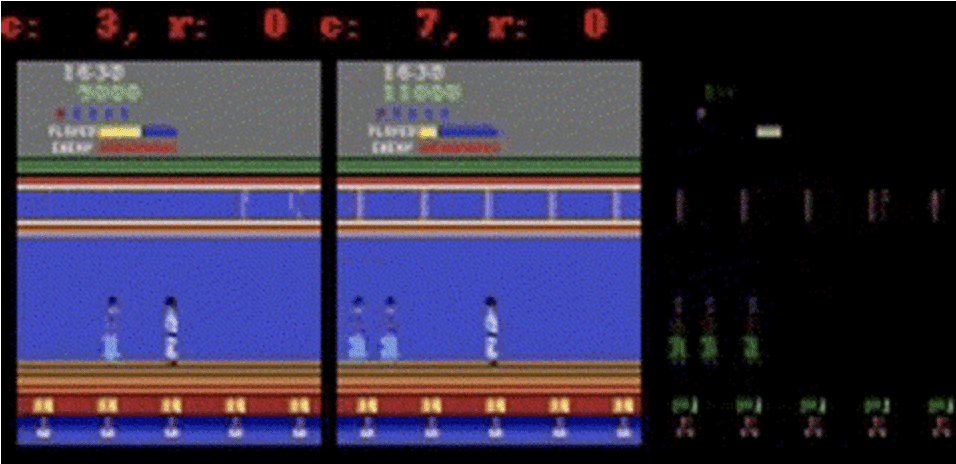
「SimPLe」をスパルタンXに適用すると、確率論から生じる問題の一例が見られる。アニメーションでは、左がモデルの出力、中央がグラウンドトゥルース、右が2つの間のピクセル単位の差。ここで、モデルの予測は、異なる数の敵を生成することにより、実際のゲームから逸脱している。
「世界モデル」を訓練した後、この「学習シミュレータ」を使用してロールアウト(行動、観察、および結果のサンプルシーケンス)を生成し、これを使用して「PPO」でポリシーを学習します。
「SimPLe」を機能させるための重要なポイントの1つは、ロールアウトのサンプリングを実際のデータセットフレームから開始することです。通常、予測エラーは時間とともに悪化し、長期予測が非常に困難になるため、「SimPLe」は中程度のロールアウトのみを使用します。幸いなことに、「PPO」は内部価値関数から行動と報酬の間の長期的な効果も学習できるため、「Freeway」のような報酬がまばらなゲームでも、限られた長さのロールアウトで十分になります。
3. SimPLeの効率
成功の尺度の1つは、モデルが『効率』的であることを示すことです。このため、環境との10万回の対話後のポリシーの出力を評価しました。これは、人による約2時間のリアルタイムゲームプレイに相当します。「SimPLe」と「SimPLe」を利用しない「Rainbow」と「PPO」で比較します。ほとんどの場合、「SimPLe」のサンプル効率は、他の2倍以上になりました。

「SimPLe」を使用して達成されたスコアと一致するために、それぞれのモデルなしアルゴリズムで必要な対話の数。
4. SimPLeの成功
「SimPLe」のエキサイティングな結果は、「Pong」と「Freeway」の2つのゲームで、シミュレートされた環境で訓練されたエージェントが最大スコアを達成できることです。
「Pong」で学んだゲームモデルを使用して、エージェントがゲームをプレイしているビデオ(動画は本家サイトへ)を次に示します。

以下に示すように、「Freeway」「Pong」「Breakout」の場合、「SimPLe」は、最大50ステップ先までのピクセルに近い予測を生成できます。

「SimPLe」により、「Breakout」(上)と「Freeway」(下)でほぼピクセル完璧な予測を行うことができる。各アニメーションで、左はモデルの出力、中央はグラウンドトゥルース、右は2つの間のピクセル単位の差。
ただし、「SimPLe」は常に正しい予測を行うとは限りません。最も一般的な障害は、小さいが関連性の高いオブジェクトを「世界モデル」が正確に予測しないことになります。
(1)「Atlantis」と「Battlezone」の弾丸は非常に小さく、消える傾向があります。
(2)「Private Eye」は、エージェントが異なるシーンを横断し、一方から他方へテレポートします。
私たちのモデルは、このような大きなグローバルな変化を捉えるのに苦労していることがわかりました。
5. おわりに
「モデルベースの強化学習方法」の主な約束は、多くのロボット工学タスクのように、相互作用にコストがかかる、時間がかかる、または人間のラベル付けが必要な環境です。そのような環境では、「学習シミュレータ」によって環境をよりよく理解でき、マルチタスク強化学習を行うため、より良く、より速い方法につながる可能性があります。「SimPLe」は標準の「モデルフリー」のパフォーマンスとはまだ一致していませんが、大幅に効率的であり、「モデルベース」のパフォーマンスをさらに向上させるために今後期待されます。
独自のモデルと実験を開発する場合は、リポジトリとColabにアクセスしてください。事前に訓練された「世界モデル」とともに作業を再現する方法についての説明があります。
この記事が気に入ったらサポートをしてみませんか?