
MuZero AIの構築方法

以下の記事を参考に書いてます。
・How To Build Your Own MuZero AI Using Python
1. Muzero以前
2019年11月19日、DeepMindは最新のモデルベースの強化学習アルゴリズム「MuZero」をリリースしました。これは、2016年の「AlphaGo」から始まった、可能性の壁を破り続けてきたDeepMindの強化学習論文の第4弾です。「AlphaGo」から「AlphaZero」までの歴史について詳しくは、過去のブログを参照してください。
「AlphaZero」は、人間のエキスパートの戦略に関する予備知識がなくても、すぐに何かを習得できる汎用的なアルゴリズムとして歓迎されました。
2. MuZero
・Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
「MuZero」は究極の次の一歩を踏み出します。「MuZero」は、人間の戦略に関する予備知識を必要としないだけではありません。ゲームのルールさえ必要としません。
チェスの場合、「AlphaZero」は次の課題を設定します。
このゲームを自分でプレイする方法を学びましょう。各ピースがどのように動き、どの動きが合法であるかを説明するルールブックがあります。また、現在の位置がチェックメイト(またはドロー)であるかどうかを確認する方法も説明します。
一方、「MuZero」は次の課題を設定します。
このゲームを自分でプレイする方法を学びましょう。現在の位置でどの動きが正当で、いつ一方が勝った(または引き分け)かを説明しますが、ゲームの全体的なルールについては説明しません。
したがって、「MuZero」は、勝利戦略を開発するとともに、環境の独自の動的モデルを開発して、選択の意味を理解し、前もって計画できるようにする必要があります。あなたがルールを知らされることのないゲームで、世界チャンピオンより良くなろうとすることを想像してください。「MuZero」はこれを実現します。
3. MuZero擬似コード
「MuZero」の論文といっしょに、「DeepMind」はアルゴリズムの各部分間の相互作用を詳述するPythonの擬似コードを公開しました。
このセクションでは、各関数とクラスを論理的な順序で分離し、各部分が何をしているのか、およびその理由を説明します。「MuZero」がチェスをプレイすることを学んでいると仮定しますが、プロセスはどのゲームでも同じであり、パラメータが異なるだけです。コードはすべて、「DeepMind」の擬似コードからのものになります。
エントリーポイント関数「muzero」から始めて、プロセス全体の概要を見てみましょう。

def muzero(config: MuZeroConfig):
storage = SharedStorage()
replay_buffer = ReplayBuffer(config)
for _ in range(config.num_actors):
launch_job(run_selfplay, config, storage, replay_buffer)
train_network(config, storage, replay_buffer)
return storage.latest_network()エントリポイント関数「muzero」には、「MuZeroConfig」オブジェクトが渡されます。このオブジェクトには、「action_space_size」(可能な行動数)や「num_actors」(並列起動するゲームシミュレーションの数)など、実行のパラメータ化に関する重要な情報が格納されます。これらのパラメータについては、他の関数で遭遇するときに詳しく説明します。
高レベルでは、「MuZero」には2つの独立した部分があります。「セルフプレイ」(ゲームデータの作成)と「トレーニング」(ニューラルネットワークの改良版の作成)です。「SharedStorage」および「ReplayBuffer」オブジェクトは、これらからアクセスでき、「ニューラルネットワーク」と「ゲームデータ」をそれぞれ保存できます。
4. SharedStorageとReplayBuffer
「SharedStorage」には、ニューラルネットワークを保存します。最新のニューラルネットワークを取得するためのメソッドも含まれています。
class SharedStorage(object):
def __init__(self):
self._networks = {}
def latest_network(self) -> Network:
if self._networks:
return self._networks[max(self._networks.keys())]
else:
# policy -> uniform, value -> 0, reward -> 0
return make_uniform_network()
def save_network(self, step: int, network: Network):
self._networks[step] = network「ReplayBuffer」には、過去のゲームのデータを保存します。
class ReplayBuffer(object):
def __init__(self, config: MuZeroConfig):
self.window_size = config.window_size
self.batch_size = config.batch_size
self.buffer = []
def save_game(self, game):
if len(self.buffer) > self.window_size:
self.buffer.pop(0)
self.buffer.append(game)
...「window_size」パラメータがバッファに保存されるゲームの最大数をどのように制限するかに注意してください。「MuZero」では、最新の1,000,000ゲームに設定されています。
5. セルフプレイ(run_selfplay)
「SharedStorage」と「ReplayBuffer」を作成した後、「MuZero」は独立して実行される「num_actors」個のゲーム環境を並列起動します。チェスの場合、「num_actors」は3000に設定されます。そして、それぞれが関数「run_selfplay」を実行します。
ここでは、「SharedStorage」からネットワークの最新バージョンを取得し、それを使用してゲームプレイ(play_game)し、ゲームデータを「ReplayBuffer」に保存します。
# Each self-play job is independent of all others; it takes the latest network
# snapshot, produces a game and makes it available to the training job by
# writing it to a shared replay buffer.
def run_selfplay(config: MuZeroConfig, storage: SharedStorage,
replay_buffer: ReplayBuffer):
while True:
network = storage.latest_network()
game = play_game(config, network)
replay_buffer.save_game(game)要約すると、「MuZero」は自分自身に対して数千ものゲームをプレイし、これらをバッファに保存してから、それらのゲームデータで訓練を行っています。ここまでのところ、これは「AlphaZero」と同じです。
次のセクションで、「AlphaZero」と「MuZero」の主な違いを1つ取り上げます。「MuZero」には3つのニューラルネットワークがあり、「AlphaZero」には1つしかありません。
6. MuZeroの3つのニューラルネットワーク
「AlphaZero」と「MuZero」は両方とも、モンテカルロツリー検索(MCTS)として知られる手法を利用して、次善の策を選択します。次の最適な動きを選択するには、現在の位置から将来のシナリオを「プレイアウト」し、ニューラルネットワークを使用してそれらの値を評価し、将来の期待値を最大化する行動を選択するのが理にかなっています。これは、人間がチェスをするときに頭の中でやっていることのようで、AIもこのテクニックを利用するように設計されています。
ただし、「MuZero」には問題があります。ゲームのルールがわからないため、特定の行動がゲームの状態にどのように影響するかはわからず、「MCTSの将来のシナリオ」を想像することはできません。与えられた位置からどのような行動が合法であるか、または一方が勝ったかどうかを判断する方法すら知らないのです。
「MuZero」の論文の驚くべき発展は、これらが重要でないことを示していることです。「MuZero」は、独自の想像力で環境の動的モデルを作成し、このモデル内で最適化することにより、ゲームプレイを学習します。
次図は、「AlphaZero」と「MuZero」のMCTSプロセスの比較を示しています。

「AlphaZero」には1つのニューラルネットワーク(予測)しかありませんが、「MuZero」には3つ(予測、ダイナミクス、表現)が必要です。
「AlphaZero」の予測ネットワーク「f」の仕事は、特定のゲーム状態のポリシー「p」と価値「v」を予測することです。ポリシーは、すべての動きにわたる確率分布であり、価値は将来の報酬を推定する数値です。この予測は、MCTSが未探索のリーフノードにヒットするたびに行われるため、推定値をすぐに新しい位置に割り当て、後続の各行動に確率を割り当てることができます。価値はツリーを埋め戻されてルートノードに戻されるため、多くのシミュレーションを行った後、ルートノードは現在の状態の将来の値を把握し、さまざまな可能性のある未来を探索します。
「MuZero」には予測ネットワーク「f」もありますが、「MuZero」が動作する「ゲーム状態」は、ダイナミクスネットワーク「g」を介して進化する方法を学習します。ダイナミクスネットワークは、現在の状態「s」と選択された行動「a」を取得し、報酬「r」と新しい状態を出力します。「AlphaZero」では、MCTSのツリーの状態間を移動することは、単に環境を尋ねる場合にすぎませんでした。「MuZero」にはこのような贅沢がないため、独自の動的モデルを構築する必要があるのです。
最後に、現在の状態から初期表現にマッピングするために、「MuZero」は表現ネットワーク「h」を使用します。したがって、「MuZero」で予測を行うMCTSのツリーを移動するには、次の2つの推論関数が必要になります。
・initial_inference : 現在の状態(h → f)
・recurrent_inference : MCTSツリー内の状態間を移動(g → f)
正確なモデルの擬似コードでは提供されていませんが、詳細な説明は論文に記載されています。
class NetworkOutput(typing.NamedTuple):
value: float
reward: float
policy_logits: Dict[Action, float]
hidden_state: List[float]
class Network(object):
def initial_inference(self, image) -> NetworkOutput:
# representation + prediction function
return NetworkOutput(0, 0, {}, [])
def recurrent_inference(self, hidden_state, action) -> NetworkOutput:
# dynamics + prediction function
return NetworkOutput(0, 0, {}, [])
def get_weights(self):
# Returns the weights of this network.
return []
def training_steps(self) -> int:
# How many steps / batches the network has been trained for.
return 0要約すると、チェスの実際のルールが存在しない場合、「MuZero」は心の中で新しいゲームを作成し、これを使用して将来の計画を立てます。
3つのネットワーク(予測、ダイナミクス、表現)は一緒に最適化されているため、想像された環境内でうまく機能する戦略は、実際の環境でもうまく機能します。
7. MuZeroでゲームをプレイする(play_game)
次に、関数「play_game」の処理の流れを説明します。
# Each game is produced by starting at the initial board position, then
# repeatedly executing a Monte Carlo Tree Search to generate moves until the end
# of the game is reached.
def play_game(config: MuZeroConfig, network: Network) -> Game:
game = config.new_game()
while not game.terminal() and len(game.history) < config.max_moves:
# At the root of the search tree we use the representation function to
# obtain a hidden state given the current observation.
root = Node(0)
current_observation = game.make_image(-1)
expand_node(root, game.to_play(), game.legal_actions(),
network.initial_inference(current_observation))
add_exploration_noise(config, root)
# We then run a Monte Carlo Tree Search using only action sequences and the
# model learned by the network.
run_mcts(config, root, game.action_history(), network)
action = select_action(config, len(game.history), root, network)
game.apply(action)
game.store_search_statistics(root)
return game最初に、「Game」オブジェクトを生成し、ゲームループを開始します。終了条件が満たされた場合、または移動数が最大許容数を超えた場合、「Game」は終了します。
ゲームループ内では、はじめに、MCTSを開始するためのルートノードを用意します。
root = Node(0)各ノードは、次のような情報を保持します。
・visit_count : アクセス回数
・to_play : (誰の)ターン
・prior : 優先順位
・node_sum : 埋め戻された値の合計
・children : 子ノード群
・hidden_state : 非表示状態
・reward : 報酬
class Node(object):
def __init__(self, prior: float):
self.visit_count = 0
self.to_play = -1
self.prior = prior
self.value_sum = 0
self.children = {}
self.hidden_state = None
self.reward = 0
def expanded(self) -> bool:
return len(self.children) > 0
def value(self) -> float:
if self.visit_count == 0:
return 0
return self.value_sum / self.visit_count次に、「Game」に現在の観察値を返すように要求します。
current_observation = game.make_image(-1)そして、「Game」によって提供される既知の合法手と、関数「initial_inference」によって提供される現在の観察に関する推論を使用して、ルートノードを展開します。
expand_node(root, game.to_play(), game.legal_actions(),
network.initial_inference(current_observation))# We expand a node using the value, reward and policy prediction obtained from
# the neural network.
def expand_node(node: Node, to_play: Player, actions: List[Action],
network_output: NetworkOutput):
node.to_play = to_play
node.hidden_state = network_output.hidden_state
node.reward = network_output.reward
policy = {a: math.exp(network_output.policy_logits[a]) for a in actions}
policy_sum = sum(policy.values())
for action, p in policy.items():
node.children[action] = Node(p / policy_sum)また、ルートノードの行動に「探索ノイズ」を追加する必要があります。
これは、MCTSが現在最適であると考えている行動だけを探索するのではなく、可能な行動の範囲を探索するために重要です。チェスの場合、「root_dirichlet_alpha = 0.3」を指定します。
add_exploration_noise(config, root)# At the start of each search, we add dirichlet noise to the prior of the root
# to encourage the search to explore new actions.
def add_exploration_noise(config: MuZeroConfig, node: Node):
actions = list(node.children.keys())
noise = numpy.random.dirichlet([config.root_dirichlet_alpha] * len(actions))
frac = config.root_exploration_fraction
for a, n in zip(actions, noise):
node.children[a].prior = node.children[a].prior * (1 - frac) + n * frac最後に、MCTSのメインプロセスを開始します。
run_mcts(config, root, game.action_history(), network)8. MuZeroのMCTS(run_mcts)
# Core Monte Carlo Tree Search algorithm.
# To decide on an action, we run N simulations, always starting at the root of
# the search tree and traversing the tree according to the UCB formula until we
# reach a leaf node.
def run_mcts(config: MuZeroConfig, root: Node, action_history: ActionHistory,
network: Network):
min_max_stats = MinMaxStats(config.known_bounds)
for _ in range(config.num_simulations):
history = action_history.clone()
node = root
search_path = [node]
while node.expanded():
action, node = select_child(config, node, min_max_stats)
history.add_action(action)
search_path.append(node)
# Inside the search tree we use the dynamics function to obtain the next
# hidden state given an action and the previous hidden state.
parent = search_path[-2]
network_output = network.recurrent_inference(parent.hidden_state,
history.last_action())
expand_node(node, history.to_play(), history.action_space(), network_output)
backpropagate(search_path, network_output.value, history.to_play(),
config.discount, min_max_stats)「MuZero」には環境ルールに関する知識がないため、学習プロセス全体で受ける報酬の限界についても知識もありません。
「MinMaxStats」は、「MuZero」がその値の出力をそれに応じて正規化できるように、現在の最小および最大報酬に関する情報を保持するために作成します。これは、チェスなどのゲームの既知の境界(-1、1)で初期化することもできます。
MCTSのメインループは「num_simulations」回繰り返します。1つのシミュレーションは、リーフノード(未探索のノード)に到達し、その後の逆方向に伝播します。
では、1つのシミュレーションを見ていきましょう。最初に、ゲーム開始から行われた行動のリストで「history」が初期化されます。現在の「node」は「root」であり、「search_path」には現在のノードのみが含まれます。
シミュレーションは次図に示すように進行します。
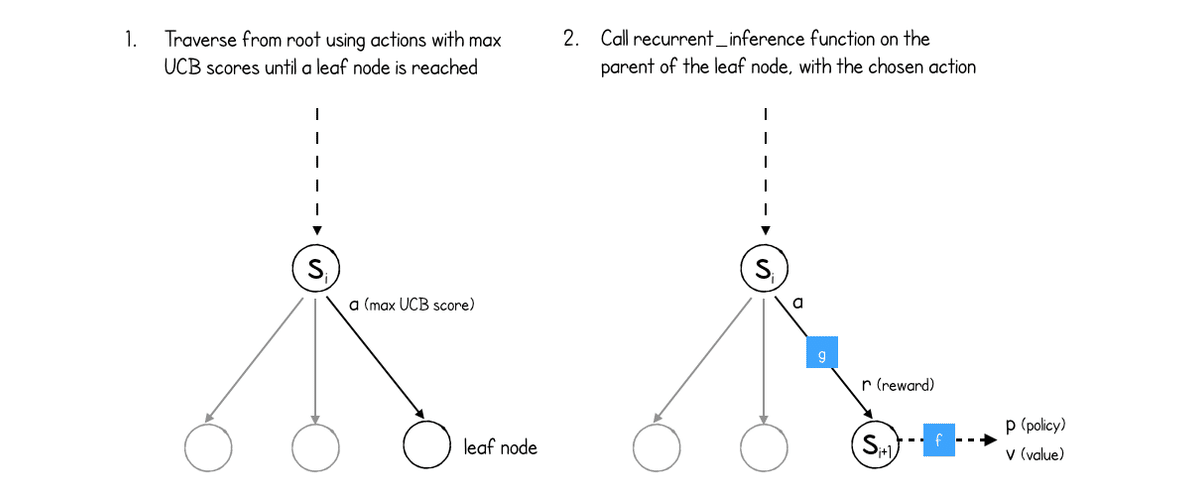
「MuZero」は最初に、「UCB(Upper Confidence Bound)スコア」が最も高い行動を選択しながら、ツリーを下に移動します。
# Select the child with the highest UCB score.
def select_child(config: MuZeroConfig, node: Node,
min_max_stats: MinMaxStats):
_, action, child = max(
(ucb_score(config, node, child, min_max_stats), action,
child) for action, child in node.children.items())
return action, child「UCBスコア」は、行動の推定値 Q(s, a) と、行動を選択する事前確率 P(s, a) および行動がすでに選択された回数 N(s, a) に基づいた探索ボーナスとのバランスをとる尺度です。

シミュレーションの初期段階では、探査ボーナスが優勢ですが、シミュレーション数が増えると、価値がより重要になります。最終的にはリーフノード(まだ展開されていないため子を持たないノード)に到達します。
この時点で、(ダイナミクスネットワークから)予測報酬と新しい隠れ状態、および(予測ネットワークから)ポリシーと新しい隠れ状態の価値を取得するため、リーフノードの親で関数「recurrent_inference」が呼び出されます。
上図に示すように、新しい子ノードを作成し(可能な行動ごとに1つ)、各ノードにそれぞれのポリシーを事前に割り当てることで、リーフノードを拡張します。
「MuZero」は、これら行動が合法手であるか、または行動の結果がゲームの終了になるかどうかをチェックしないため、合法手であるかどうかにかかわらず、行動ごとにノードを作成します。
最後に、ネットワークによって予測された価値は、検索パスに沿ってツリーを逆方向に伝播します。
# At the end of a simulation, we propagate the evaluation all the way up the
# tree to the root.
def backpropagate(search_path: List[Node], value: float, to_play: Player,
discount: float, min_max_stats: MinMaxStats):
for node in search_path:
node.value_sum += value if node.to_play == to_play else -value
node.visit_count += 1
min_max_stats.update(node.value())
value = node.reward + discount * value(誰の)ターンに応じて価値がどのように反転することに注意してください。リーフノードがプレイするプレイヤーに対して正の場合、他のプレイヤーに対しては負になります。また、予測ネットワークは将来の価値を予測するため、検索パスで収集された報酬は収集され、割引されたリーフノードの価値に追加されて、ツリーに反映されます。これらは環境からの実際の報酬ではなく、予測される報酬であるため、報酬の収集はチェスのようなゲームにも関連しており、真の報酬はゲームの最後にのみ与えられます。「MuZero」は独自の想像上のゲームをプレイしているため、モデル化されたゲームがそうでない場合でも、暫定的な報酬が含まれる場合があります。
これで、MCTSのプロセスの1つのシミュレーションが完了しました。「num_simulations」回ツリーを通過すると、プロセスが停止し、ルートの各子ノードのアクセス回数に基づいて行動が選択されます。
def select_action(config: MuZeroConfig, num_moves: int, node: Node,
network: Network):
visit_counts = [
(child.visit_count, action) for action, child in node.children.items()
]
t = config.visit_softmax_temperature_fn(
num_moves=num_moves, training_steps=network.training_steps())
_, action = softmax_sample(visit_counts, t)
return action
def visit_softmax_temperature(num_moves, training_steps):
if num_moves < 30:
return 1.0
else:
return 0.0 # Play according to the max.最初の30の動きについて、ソフトマックスの「temperature」は1に設定されます。これは、各行動の選択の確率が、アクセス回数に比例することを意味します。30番目の移動から、アクセス数が最大の行動が選択されます。

アクセス数が最終的な行動の選択基準になるのは、奇妙に感じるかもしれません。これは、MCTSのプロセス内のUCB選択基準が、最終的には真に価値の高い機会であると思われる行動の調査により多くの時間を費やすように設計されているため、選択基準として利用できるのです。
次に、選択した行動が真の環境に適用され、関連する値がGameオブジェクトの次のリストに追加されます。
・game.rewards : ゲームの各ターンで受け取った真の報酬のリスト
・game.history : ゲームの各ターンで実行される行動のリスト
・game.child_visits : ゲームの各ターンでのルートノードからの行動確率分布のリスト
・game.root_values : ゲームの各ターンでのルートノードの値のリスト
これらのリストは、最終的にニューラルネットワークの訓練データを構築するために使用されます。このプロセスは継続し、ターンごとにゼロから新しいMCTSツリーを作成し、それを使用して行動を選択します。これはゲームが終了するまで続きます。
すべてのゲームデータ(reward, history, child_visits, root_values)は「ReplayBuffer」に保存されます。
9. トレーニング(train_network)
エントリポイント関数の最後の行では、「ReplayBuffer」のデータを使用してニューラルネットワークを継続的に訓練する「train_network」プロセスを実行しています。
def train_network(config: MuZeroConfig, storage: SharedStorage,
replay_buffer: ReplayBuffer):
network = Network()
learning_rate = config.lr_init * config.lr_decay_rate**(
tf.train.get_global_step() / config.lr_decay_steps)
optimizer = tf.train.MomentumOptimizer(learning_rate, config.momentum)
for i in range(config.training_steps):
if i % config.checkpoint_interval == 0:
storage.save_network(i, network)
batch = replay_buffer.sample_batch(config.num_unroll_steps, config.td_steps)
update_weights(optimizer, network, batch, config.weight_decay)
storage.save_network(config.training_steps, network)最初に、新しい「Network」(MuZeroの3つのニューラルネットワークのランダムに初期化されたインスタンスを保持)を作成し、完了した訓練ステップの数に基づいて学習率を減衰に設定します。そして、各訓練ステップで重みの更新の大きさと方向を計算する勾配降下オプティマイザを作成します。
この関数の最後では、「training_steps」回(チェスの場合、論文では1,000,000)のループを行います。各ステップで、「ReplayBuffer」から位置のバッチをサンプリングし、それらを使用してネットワークを更新します。
ネットワークは、「checkpoint_interval」バッチ(= 1000)ごとにストレージに保存されます。
10. 訓練バッチの作成(replay_buffer.sample_batch)
「ReplayBuffer」には、バッファから観察値のバッチをサンプリングするための「sample_batch」メソッドが含まれています。
class ReplayBuffer(object):
def __init__(self, config: MuZeroConfig):
self.window_size = config.window_size
self.batch_size = config.batch_size
self.buffer = []
def sample_batch(self, num_unroll_steps: int, td_steps: int):
games = [self.sample_game() for _ in range(self.batch_size)]
game_pos = [(g, self.sample_position(g)) for g in games]
return [(g.make_image(i), g.history[i:i + num_unroll_steps],
g.make_target(i, num_unroll_steps, td_steps, g.to_play()))
for (g, i) in game_pos]
...チェスの「MuZero」のデフォルトの「batch_size」は2048です。この数のゲームはバッファから選択され、それぞれから1つの位置が選択されます。単一のバッチはタプルのリストであり、各タプルは3つの要素で構成されます。
・g.make_image(i) : 選択した位置での観測。
・g.history[i:i + num_unroll_steps] : 選択した位置の後に実行される次のnum_unroll_steps行動のリスト(存在する場合)。
・g.make_target(i, num_unroll_steps, td_steps, g.to_play() : ニューラルネットワークの訓練に使用されるターゲットのリスト。 具体的には、これはタプルのリスト(target_value, target_reward, target_policy)。
バッチの例の図を以下に示します。
num_unroll_steps= 5(MuZeroで使用されるデフォルト値):
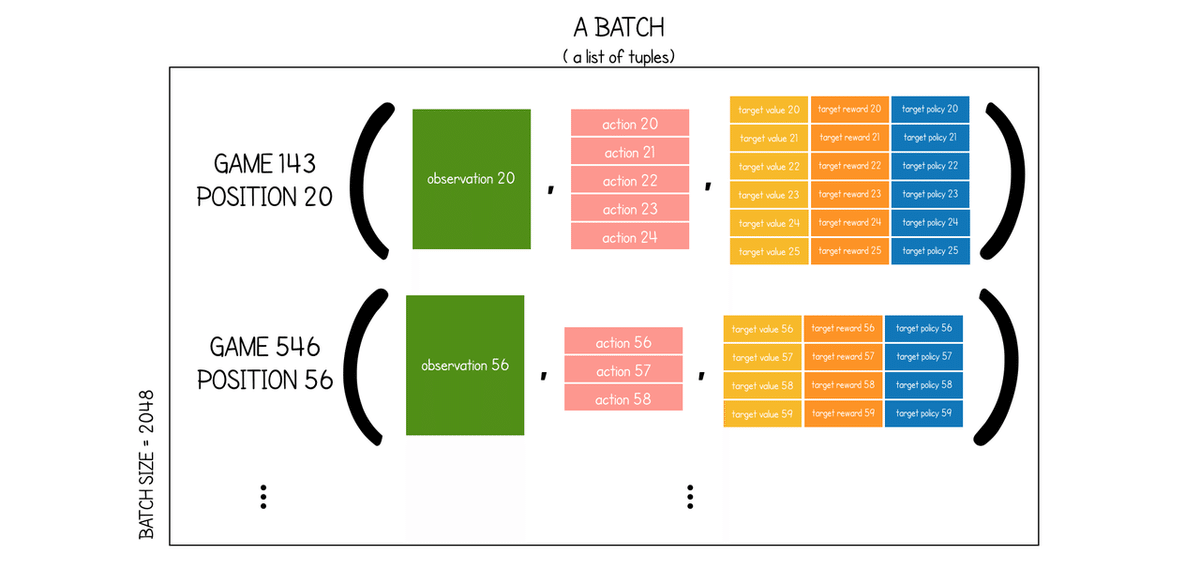
各観察に複数の将来の行動が必要な理由を疑問に思うかもしれません。その理由は、動的ネットワークを訓練する必要があり、これを行う唯一の方法が、シーケンシャルデータの小さなストリームでの訓練であるためです。バッチ内の各観察について、提供された行動を使用して、num_unroll_steps」の位置を将来的に「展開」します。
初期位置については、関数「initial_inference」を使用して値、報酬およびポリシーを予測し、これらを目標価値、目標報酬、および目標ポリシーと比較します。後続の行動では、関数「recurrent_inference」を使用して価値、報酬、ポリシーを予測し、目標価値、目標報酬、目標ポリシーと比較します。
この方法では、3つのネットワークすべてが予測プロセスで使用されるため、3つのネットワークすべての重みが更新されます。
次に、目標の計算方法を詳しく見てみましょう。
class Game(object):
"""A single episode of interaction with the environment."""
def __init__(self, action_space_size: int, discount: float):
self.environment = Environment() # Game specific environment.
self.history = []
self.rewards = []
self.child_visits = []
self.root_values = []
self.action_space_size = action_space_size
self.discount = discount
def make_target(self, state_index: int, num_unroll_steps: int, td_steps: int,
to_play: Player):
# The value target is the discounted root value of the search tree N steps
# into the future, plus the discounted sum of all rewards until then.
targets = []
for current_index in range(state_index, state_index + num_unroll_steps + 1):
bootstrap_index = current_index + td_steps
if bootstrap_index < len(self.root_values):
value = self.root_values[bootstrap_index] * self.discount**td_steps
else:
value = 0
for i, reward in enumerate(self.rewards[current_index:bootstrap_index]):
value += reward * self.discount**i # pytype: disable=unsupported-operands
if current_index < len(self.root_values):
targets.append((value, self.rewards[current_index],
self.child_visits[current_index]))
else:
# States past the end of games are treated as absorbing states.
targets.append((0, 0, []))
return targets
...関数「make_target」は、TD学習のアイデアを使用して、「state_index」から「state_index + num_unroll_steps」までの位置にある各状態の目標価値を計算します。
TD学習は強化学習で使用される一般的な手法です。エピソードの終わりまでに発生した割引報酬の合計を使用するのではなく、近い将来の位置td_stepsの推定割引価値とその時点までの割引報酬を使用して、状態の価値を更新します。
推定に基づいて推定を更新するとき、「ブートストラッピング」と言います。 bootstrap_indexは、真の将来の報酬を推定するために使用する、未来へのtd_stepsの位置のインデックスです。
この関数は、「bootstrap_index」がエピソードの終了後かどうかを最初にチェックします。 その場合、値は0に設定され、そうでない場合、値は「bootstrap_index」の位置の割引予測値に設定されます。
次に、「current_index」と「bootstrap_index」の間に発生した割引報酬が値に追加されます。
最後に、「current_index」がエピソードの終了後ではないことを確認するチェックがあります。 その場合、空の目標価値が追加されます。 それ以外の場合、計算されたTD目標価値、MCTSからの真の報酬およびポリシーが目標リストに追加されます。
チェスの場合、「td_steps」は実際には「max_moves」に設定されるため、「bootstrap_index」は常にエピソードの終了後に低下します。 このシナリオでは、目標価値(つまり、エピソード完了までのすべての将来の報酬の割引合計)のモンテカルロ推定を実際に使用しています。 これは、チェスの報酬がエピソードの最後にのみ与えられるためです。 TD学習とモンテカルロ推定の違いを次図に示します。

目標の構築方法がわかったので、目標がMuZero損失関数にどのように適合するかを確認し、最後にネットワークを訓練するために関数「update_weights」でどのように使用されるかを確認できます。
11. MuZeroの損失関数
Muzeroの損失関数は次のとおりです。

ここで、「K」は「num_unroll_steps」です。 つまり、最小化しようとしている損失は3つあります。
・ターンt(r)のkステップ先の予測報酬 と 実際の報酬(u) の差分
・ターンt(v)のkステップ先の予測価値 と TD目標価値(z) の差分
・ターンt(p)のkステップ先の予測ポリシー と MCTSポリシー(pi) の差分
これらの損失はロールアウトで合計され、バッチ内の特定の位置の損失が生成されます。
12. 3つのMuZeroネットワークの更新(update_weights)
def update_weights(optimizer: tf.train.Optimizer, network: Network, batch,
weight_decay: float):
loss = 0
for image, actions, targets in batch:
# Initial step, from the real observation.
value, reward, policy_logits, hidden_state = network.initial_inference(
image)
predictions = [(1.0, value, reward, policy_logits)]
# Recurrent steps, from action and previous hidden state.
for action in actions:
value, reward, policy_logits, hidden_state = network.recurrent_inference(
hidden_state, action)
predictions.append((1.0 / len(actions), value, reward, policy_logits))
hidden_state = tf.scale_gradient(hidden_state, 0.5)
for prediction, target in zip(predictions, targets):
gradient_scale, value, reward, policy_logits = prediction
target_value, target_reward, target_policy = target
l = (
scalar_loss(value, target_value) +
scalar_loss(reward, target_reward) +
tf.nn.softmax_cross_entropy_with_logits(
logits=policy_logits, labels=target_policy))
loss += tf.scale_gradient(l, gradient_scale)
for weights in network.get_weights():
loss += weight_decay * tf.nn.l2_loss(weights)
optimizer.minimize(loss)関数「update_weights」は、バッチ内の2048の位置のそれぞれについて、ピースごとに損失を構築します。最初に、初期観察が「initial_inference」ネットワークを通過して、現在の位置から価値、報酬、およびポリシーを予測します。これらは、指定された1.0の重みとともに、予測リストを作成するために使用されます。
次に、各行動が順番にループされ、関数「recurrent_inference」が現在の「hidden_state」から次の価値、報酬、ポリシーを予測するように求められます。これらは、「1 / num_rollout_steps」の重みで予測リストに追加されます。したがって、関数「recurrent_inference」の全体的な重みは関数「initial_inference」の重みと等しくなります。
次に、予測を対応する目標価値と比較する損失を計算します。これは、「報酬」と「価値のscalar_loss」と「ポリシーのsoftmax_crossentropy_loss_with_logits」の組み合わせです。最適化は、この損失関数を使用して、MuZeroネットワークの3つすべてを同時に訓練します。
13. 要約
要約すると、「AlphaZero」には次の3つのことが知らされています。
◎ 所定の動きをしたときにボードに何が起こるか。
たとえば、「ポーンをe2からe4に移動」という行動をとる場合、ポーンが移動することを除いて、次のボードの位置は同じであることがわかります。
◎ 所定の位置での合法手は何か。
たとえば、「AlphaZero」は、クイーンがボードから外れている、ピースが動きをブロックしている、またはすでにc3にピースがある場合、「クイーンをc3に移動できない」ことを知っています。
◎ ゲームが終了し、誰が勝ったか。
たとえば、相手のキングがチェックイン状態で、チェックアウトできない場合は勝ったことを知っています。
言い換えれば、「AlphaZero」はゲームのルールを知っているので、可能な未来を想像することができます。「MuZero」は、訓練プロセス全体を通じてこれらの基本的なゲームメカニズムへのアクセスを拒否されています。 注目すべきは、追加のニューラルネットワークをいくつか追加することで、ルールを知らなくても対処できることです。実際、それはうまくいっています。
「MuZero」は囲碁での「AlphaZero」のパフォーマンスを実際に改善します。 これは、実際のボードの位置を使用する場合にAlphaZeroが見つけることができるよりも、非表示で位置を表すより効率的な方法を見つけていることを示している場合があります。「MuZero」がゲームを自分の頭の中に埋め込む不思議な方法は、近い将来、DeepMindの研究の活発な分野になるでしょう。

14. MuZeroはなぜ重要なのか
「AlphaZero」は、人間の専門知識を必要とせずに、様々なゲームで超人的な能力を達成した、AIのこれまでの最大の成果の1つと見なされています。表面的には、ルールへのアクセスを拒否しても、アルゴリズムが妨げられないことを示すことに多大な努力を払うのは奇妙に思えます。チェスの世界チャンピオンになり、目を閉じて将来のすべての競争試合に臨むようなものです。これは単なる隠し芸なのでしょうか?
答えは、実際に囲碁、チェス、またはDeepMindの他のボードゲームに関するものではなかったということです。これは知性そのものなのです。
泳ぐことを学んだとき、最初に流体力学のルールブックが与えられていませんでした。ブロックでタワーを構築することを学んだとき、あなたはニュートンの重力の法則の準備ができていませんでした。あなたが話すことを学んだとき、あなたは文法を全く知らずに覚えました。そして、今日でも非言語話者に言語のすべての規則と癖を説明するのにまだ苦労するでしょう。
重要なのは、ルールブックなしで人生が学べることです。これがどのように機能するかは、宇宙の最大の秘密の1つです。そのため、今後の計画のために環境力学の直接的な知識を必要としない強化学習の方法を引き続き検討することが非常に重要です。
「MuZero」の論文と同様に印象的な論文「World Models」(Ha、Schmidhuber)には類似点があります。どちらも、エージェント内にのみ存在する環境の内部表現を作成し、目標を達成するためにモデルを訓練するために可能な未来を想像するために使用されます。2つの論文がこの目標を達成する方法は異なりますが、描かれるべき類似点がいくつかあります。
・「MuZero」は表現ネットワークを使用して現在の観察を埋め込み、「World Models」は変分オートエンコーダを使用します。
・「MuZero」はダイナミクスネットワークを使用して想定される環境をモデル化し、「World Models」はリカレントニューラルネットワークを使用します。
・「MuZero」はMCTSと予測ネットワークを使用して行動を選択し、「World Models」は進化プロセスを使用して最適なアクションコントローラを進化させます。
両方とも独自の方法で画期的な2つのアイデアが同様の目標を達成する場合、通常は良い兆候です。それは通常、両方が明らかになった、より深い根底にある真実があることを意味します。おそらく、2つのシャベルが宝箱のさまざまな部分にちょうど当たったのでしょう。
この記事が気に入ったらサポートをしてみませんか?