
Alpaca まとめ

「Alpaca」の学習方法について軽くまとめました。
1. Alpaca
「Alpaca」は、「LLaMA 7B」(Meta)をファインチューニングした言語モデルです。「text-davinci-003」による「self-instruct」で生成された52Kの命令追従型の学習データを使って学習しています。「Alpaca」はOpenAIの「text-davinci-003」に似た挙動を示しますが、驚くほど小さく再現が容易で安価であることが特徴です。
また、「Alpaca」は学術研究のみを目的としており、商用利用は禁止しています。
2. 学習済み言語モデル と 学習データ
アカデミックな予算で高品質な言語モデルを学習させるためには、「強力な学習済み言語モデル」と「高品質な学習データ」が必要です。
1つ目は、最近リリースされたMetaの「LLaMA」で解決されます。2つ目は、「self-instruct」の手法で、既存の強力な言語モデルを使用して、命令データを自動生成することを提案します。
「Alpaca」は、OpenAIの「text-davinci-003」で生成した52Kの命令追従型の学習データを使って、「LLaMA 7B」をファインチューニングしたモデルになります。
3. 学習の流れ
下図は、「Alpaca」の学習の流れを示しています。データについては、「self-instruct」の手法をベースに、命令追従型の学習データを作成しました。まず、「self-instruct」のシードセットから、人間が書いた175の命令と出力のペアを用意しました。その後、「text-davinci-003」に、シードセットを文脈上の例として、さらに命令を生成するように促しました。生成パイプラインを簡略化することで、「self-instruct」を改良し(詳細はGitHubを参照)、コストを大幅に削減しました。その結果、OpenAI APIを使用して500ドル未満のコストで、52Kのユニークな命令とそれに対応する出力が生成できました。
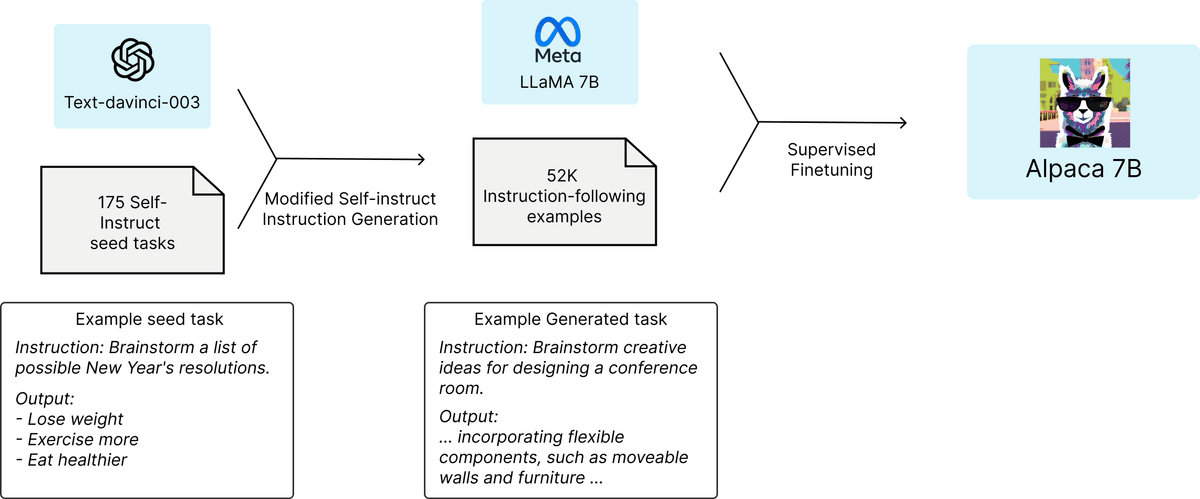
この命令追従型データセットを用いて、HuggingFaceの学習フレームワークを使用して、「LLaMA」をファインチューニングしました。7Bの「LLaMA」のファインチューニングには、80GBのA100を8台使用して3時間かかりました。これは、ほとんどのクラウドコンピューティングプロバイダーで100ドル以下のコストになります。
4. 公開アセット
以下のアセットが公開されてます。
・デモ : 「Alpaca」を体験できるインタラクティブなデモ
・学習データ : 「Alpaca」のファインチューニングに使用したデータ (52K)
・学習データ生成コード : 学習データを生成するためのコード。
・学習コード : 「Alpaca」をファインチューニングするためのコード。
以下のアセットも今後公開予定になっています。
・モデルの重み : モデルの重みを公開するためのガイダンスを得るためMetaに連絡を取ってます。
5. 学習データ
「alpaca_data.json」には、「Alpaca」のファインチューニングに使用した 52K の命令追従型の学習データが含まれています。 このJSONは辞書のリストで、各辞書には次のフィールドが含まれています。
・instruction: str - モデルが実行すべきタスクを記述。52Kの指示はユニーク。
・input: str - タスクのオプションのコンテキストまたは入力。たとえば、指示が「次の記事を要約」の場合、入力は記事。例の約40%には入力がある。
・output: str - 「text-davinci-003」によって生成された指示に対する回答。
「Alpaca」のファインチューニングには、次のプロンプトを使用しています。
・空でない入力フィールドの例
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:以下は、タスクを説明する命令と、さらなるコンテキストを提供する入力の組み合わせです。要求を適切に満たすような応答を書きなさい。
・空の入力フィールドの例
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:以下は、タスクを説明する命令です。 要求を適切に完了する応答を作成します。
6. 学習データ生成
6-1. 実行手順
(1) 環境変数「OPENAI_API_KEY」に「OpenAI APIキー」を設定。
(2) 依存関係のインストール。
$ pip install -r requirements.txt(3) 学習データ生成コードを実行。
学習データが生成されます。
$ python -m generate_instruction generate_instruction_following_data6-2. 詳細
「self-instruct」のデータ生成パイプラインをベースに、次のような修正を加えています。
・学習データ生成にdavinciの代わりにtext-davinci-003を使用。
・学習データ生成の要件をtext-davinci-003に明示的に与える新しいプロンプト(prompt.txt)を書いた。(注意 : 使用したプロンプトには若干の誤りがあったため、今後使用する方は#24の編集を取り入れること)
・20個の学習データを一度に生成するという、より積極的なバッチデコードを採用し、学習データ生成のコストを大幅に削減。
・分類指示と非分類指示の違いを捨てて、データ生成パイプラインを簡略化。
2〜3個のインスタンスを生成するのではなく、各学習データに対して1個のインスタンスしか生成しない。
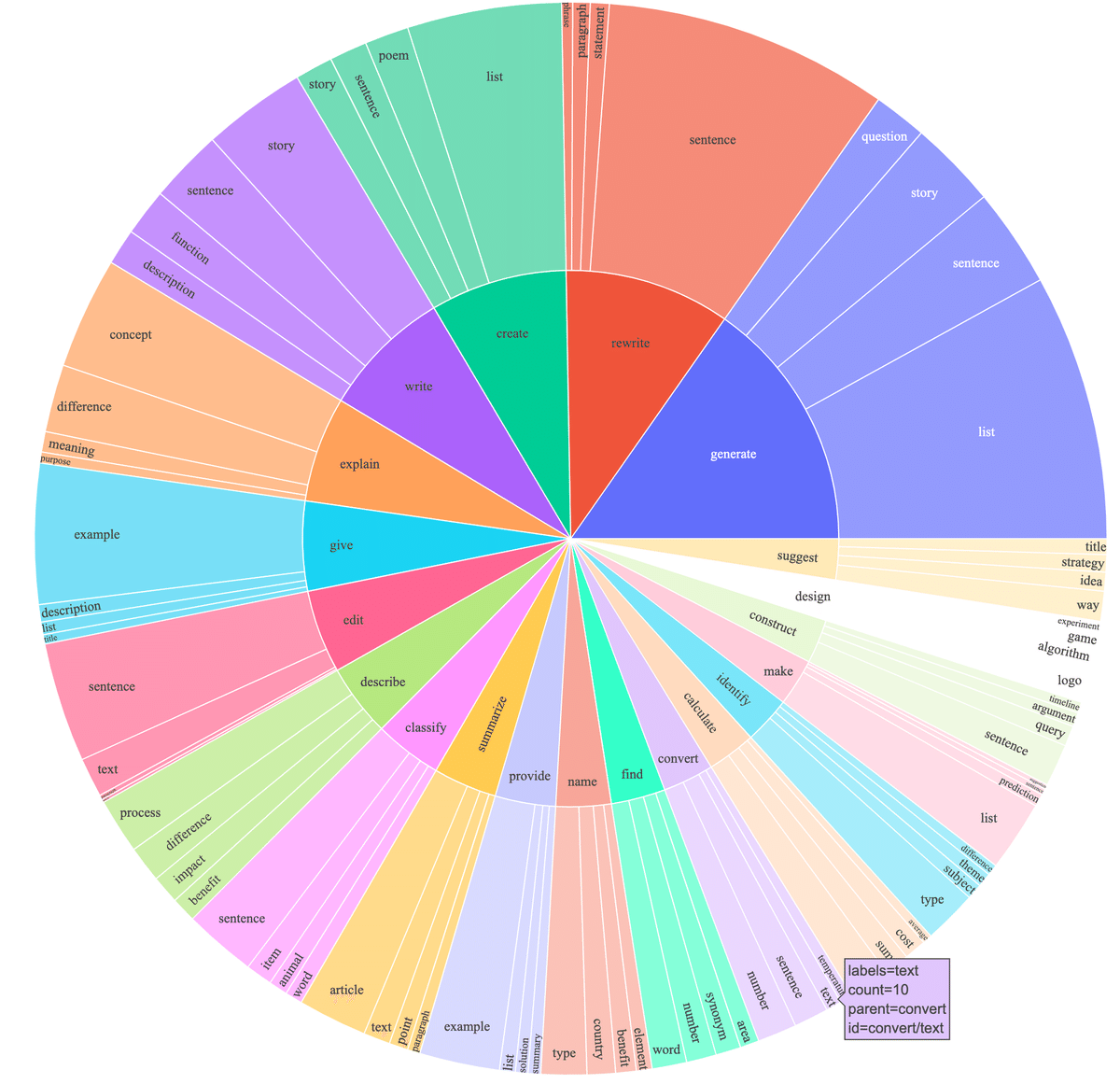
これにより、500ドル以下の低コストで、52K個の学習データが得られました。予備的な調査として、52K個の命令データがself-instructが公開したデータよりもはるかに多様であることを発見しました。下図は、self-instructの論文にある図2のスタイルで、データの多様性を示すためにプロットしたものです。図中の内側の円は指示の根本動詞、外側の円は直接の目的語を表しています。
7. ファインチューニング
7-1. ハイパーパラメータ
標準的なHugging Faceの学習コードを用いて、以下のハイパーパラメータでモデルのファインチューニングを行いました。
◎ ハイパーパラメータ
・Batch size : 128
・Learning rate : 2e-5
・Epochs : 3
・Max length : 512
・Weight decay : 0
7-2. 実行手順
Hugging FaceがLLaMAモデルを公式にサポートしていないため、特定のフォーク(つまりマージされるこのPR)からインストールすることで、Hugging Face TransformersでLLaMAをファインチューニングしました。インストールした特定のコミットのハッシュは以下です。
68d640f7c368bcaaaecfc678f11908ebbd3d6176LLaMAのファインチューニングを再現するために、依存関係をインストールします。
$ pip install -r requirements.txt「Hugging Face Transformers」の特定のフォークをインストールします。
以下は、FSDP full_shardモードで4つのA100 80G GPUを搭載したマシンで、我々のデータセットを使ってLLaMA-7Bをファインチューニングするコマンドです。Python 3.10を使用した以下のコマンドで、デモでホストしたモデルと同様の品質のモデルを再現することができました。<your_random_port>を自分のポート、<your_path_to_hf_converted_llama_ckpt_and_tokenizer>を変換したチェックポイントとトークナイザへのパス、<your_output_dir>を出力を保存したい場所に置き換えます。
$ torchrun --nproc_per_node=4 --master_port=<your_random_port> train.py \
--model_name_or_path <your_path_to_hf_converted_llama_ckpt_and_tokenizer> \
--data_path ./alpaca_data.json \
--bf16 True \
--output_dir <your_output_dir> \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LLaMADecoderLayer' \
--tf32 True7-3. 注意点
fsdp_transformer_layer_cls_to_wrap は、特定のデコーダ層の名前に設定する必要があります。LLaMA HuggingFace PR は安定しません。以前のコミットでは、デコーダーレイヤーにLLaMADecoderLayer という名前が使用されていました (コードのコミットハッシュはこれに基づいています)。 最近のコミットでは LlamaDecoderLayerが使用されています (大文字と小文字の違いに注意してください)。 fsdp_transformer_layer_cls_to_wrap を正しい名前に設定しないと、トレーニングが大幅に遅くなります。
7-4. 補足事項
同じスクリプトがOPTのファインチューニングにも機能します。以下は、OPT-6.7Bのファインチューニングの例です。
$ torchrun --nproc_per_node=4 --master_port=<your_random_port> train.py \
--model_name_or_path "facebook/opt-6.7b" \
--data_path ./alpaca_data.json \
--bf16 True \
--output_dir <your_output_dir> \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'OPTDecoderLayer' \
--tf32 True与えられた学習スクリプトは、シンプルで使いやすいように意図されており、特に最適化されていないことに注意してください。より多くのGPUで実行するには、gradient_accumulation_steps を下げて、Global Batch Sizeを128に保つことをお勧めします。Global Batch Sizeは、最適性についてテストされていません。
関連
この記事が気に入ったらサポートをしてみませんか?