
CLIP:テキストと画像の接続

以下の記事を参考に書いてます。
・CLIP: Connecting Text and Images
1. 要旨
自然言語のスーパービジョンから視覚的な概念を効率的に学習する「CLIP」と呼ばれるニューラルネットワークを紹介します。「CLIP」(Contrastive Language–Image Pre-training)は、「GPT-2」「GPT-3」の「ゼロショット」と同様に、認識する視覚カテゴリの名前を提供するだけで、視覚分類ベンチマークに適用できます。
2. はじめに
深層学習はコンピュータービジョンに革命をもたらしましたが、現在のアプローチにはいくつかの大きな問題があります。一般的なビジョンデータセットは、限定的な視覚概念しか教えず、作成するのにコストがかかります。基本的に、1つのタスクのみに優れており、別タスクに適応するには多大な労力が必要になります。ベンチマークでパフォーマンスを発揮するモデルでも、ストレステストでは期待外れな場合も多いです。
これらの問題を解決することを目的としたニューラルネットワーク「CLIP」を紹介します。これは、インターネット上で豊富に利用可能な多種多様な自然言語スーパービジョンの多種多様な画像上で学習されます。このネットワークは、「GPT-2」「GPT-3」の「ゼロショット」と同様に、ベンチマークの性能を直接最適化することなく、非常に多様な分類ベンチマークを実行するように、自然言語で指示することができます。ベンチマークのために直接最適化を行わないことで,より代表的なものになることを示しています。私たちのシステムは、オリジナルの128万個のラベル付きサンプルを使用せずに、ImageNetの「ゼロショット」でオリジナルのResNet50の性能に匹敵しながら、この「堅牢性のギャップ」を最大75%まで縮めることができます。

ImageNetのテストセットではどちらのモデルも同じ精度を持っていますが、「CLIP」のパフォーマンスは、ImageNet以外でのパフォーマンスが優れています。例えば、ObjectNetは、家の中の様々なポーズや様々な背景の物体を認識するモデルの能力をチェックしていますが、ImageNet RenditionとImageNet Sketchは、物体のより抽象的な描写を認識するモデルの能力をチェックしています。
3. 背景と関連するワーク
「CLIP」は、ゼロショット転送、自然言語のスーパービジョン、マルチモーダル学習に関する大量のワークをベースに構築されています。 ゼロデータ学習のアイデアは10年以上前にさかのぼります。最近まで、目に見えないオブジェクトカテゴリを一般化する方法としてコンピュータビジョンで主に研究されていました。重要な洞察は、一般化と転送を可能にする柔軟な予測空間として自然言語を活用することでした。2013年、Richer Socherとスタンフォード大学の共著者は、CIFAR-10でモデルを学習して単語ベクトル埋め込み空間で予測を行う概念実証を開発し、このモデルが2つの見えないクラスを予測できることを示しました。同じ年、DeVISEはこのアプローチを拡張し、ImageNetモデルをファインチューニングして、元の1000の学習セット外のオブジェクトを正しく予測できるように一般化できることを実証しました。
「CLIP」に最もインスピレーションを与えたのは、Ang Liと彼の共著者のワークです。2016に自然言語のスーパービジョンを使用して、正規の既存のコンピュータビジョン分類データセットへのゼロショット転送を可能にすることを実証しました。 彼らは、ImageNet CNNをファインチューニングして、タイトルのテキストからはるかに幅広い視覚的概念(視覚的n-gram)のセットを予測することで、これを達成しました。説明、および3,000万枚のFlickr写真のタグがあり、ImageNetゼロショットで11.5%の精度に達することができました。
最後に、「CLIP」は過去1年間の自然言語のスーパービジョンからの視覚的表現の学習を再検討した論文群の一部です。この一連の作業には、Transformerのようなより現代的なアーキテクチャを使用しており、自己回帰的言語モデリングを研究したVirTex,33、マスク付き言語モデリングを研究したICMLM、そして私たちがCLIPで使用しているのと同じ対照的な目的を研究したConVIRT,35が含まれてろり、医療画像の分野での研究も含まれています。
4. アプローチ
様々な画像分類データセットで競争力のあるゼロショットのパフォーマンスを実現するには、単純な事前学習タスクをスケーリングするだけで十分であることを示します。 私たちの方法では、インターネット上で見つかった画像と組み合わせたテキストという、豊富に利用可能なスーパービジョンを使用します。 このデータは、「CLIP」の次のプロキシ学習タスクを作成するために使用されます。画像を指定して、ランダムにサンプリングされた32,768のテキストスニペットのセットのうち、データセット内で実際にペアになっているものを予測します。
この課題を解決するために、私たちの直感では、CLIPモデルは、画像内の様々な視覚的概念を認識し、それらを名前に関連付けることを学習する必要があります。その結果、CLIPモデルをほぼ任意の視覚的分類タスクに適用できます。例えば、データセットのタスクが犬と猫の写真を分類する場合、CLIPモデルが「犬の写真」と「猫の写真」というテキスト記述を予測しているかどうかを、画像ごとにチェックします。

CLIPは、画像エンコーダーとテキストエンコーダーを事前学習して、データセット内のどの画像がどのテキストとペアになっているかを予測します。次に、この動作を使用して、CLIPをゼロショット分類器に変換します。データセットの全てのクラスを「犬の写真」などのキャプションに変換し、キャプションのクラスを予測します。「CLIP」は特定の画像との最良のペアを推定します。
「CLIP」は、コンピュータービジョンへの標準的な深層学習アプローチにおける多くの主要な問題を軽減するように設計されました。
◎ データセットのコスト
深層学習には大量のデータが必要であり、ビジョンモデルは従来、手動でラベル付けされたデータセットで学習されていました。これらのデータセットは、構築にコストがかかり、限られた数の所定のビジュアルコンセプトのみを監視します。この分野で最大の取り組みの1つであるImageNetデータセットでは、22,000のオブジェクトカテゴリに対して1,400万の画像に注釈を付けるために25,000人を超える作業者が必要でした。対照的に、「CLIP」はインターネット上ですでに公開されているテキストと画像のペアから学習します。高価な大規模なラベル付きデータセットの必要性を減らすことは、以前の研究、特に自己教師あり学習、コントラスティブメソッド、自己学習アプローチ、生成モデリングによって広く研究されてきました。
◎ 狭い
ImageNetモデルは1000のImageNetカテゴリを予測するのに優れていますが、実行できるのはそれだけです。他のタスクを実行する場合、ML実践者は新しいデータセットを構築し、出力ヘッドを追加して、モデルをファインチューニングする必要があります。対照的に、「CLIP」は、追加の学習サンプルを必要とせずに、様々な視覚的分類タスクを実行することができます。「CLIP」を新しいタスクに適用するには、「CLIP」のテキストエンコーダーにタスクの視覚的概念の名前を「伝える」だけで、「CLIP」の視覚的表現の線形分類器が出力されます。この分類器の精度は、完全に監視されたモデルと競合することがよくあります。
以下の様々なデータセットの例で、チェリーが選択されていないランダムなゼロショットCLIP分類子の予測を示します。
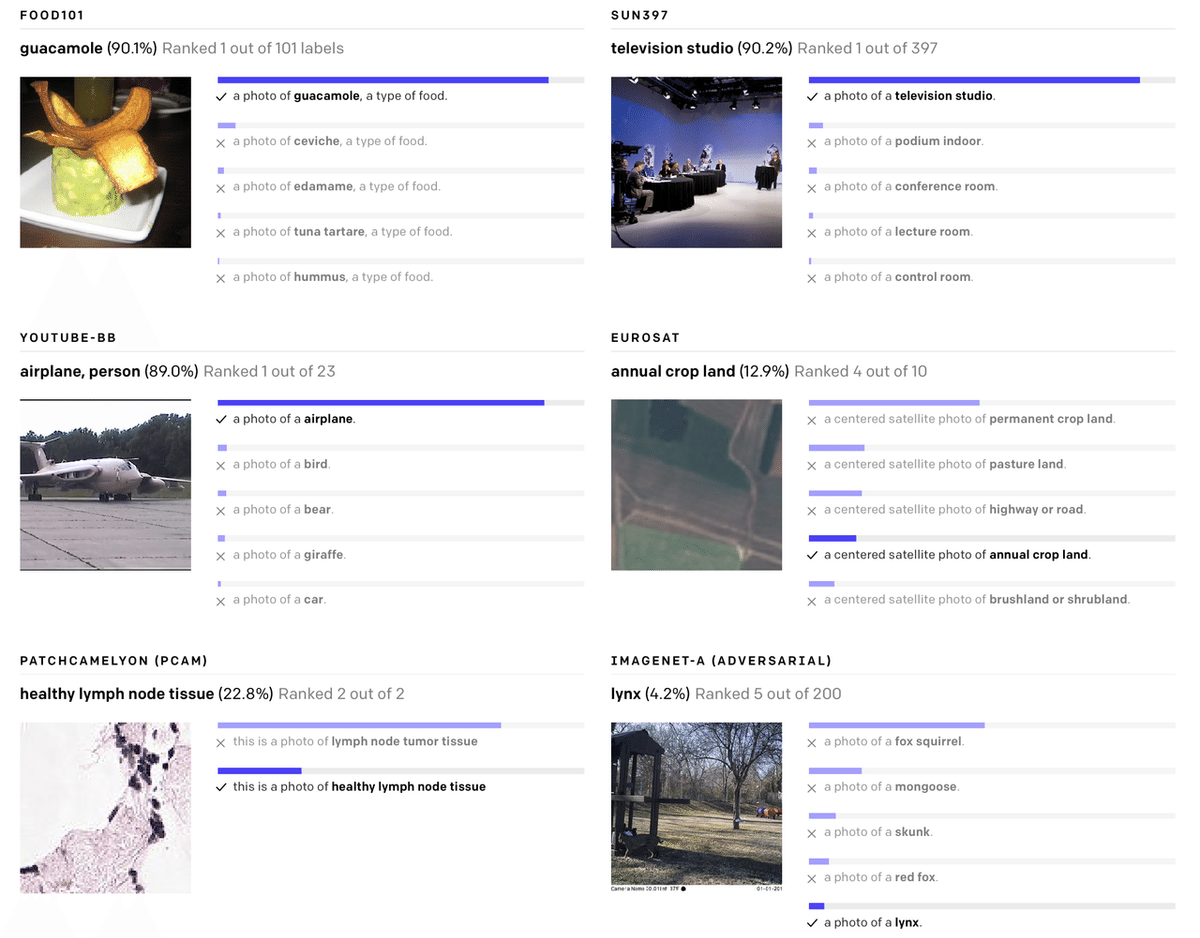
◎ 現実世界でパフォーマンスの低下
深層学習システムは、ビジョンのベンチマークでは人間並み、あるいは超人的な性能を達成していると報告されることが多いですが、現実世界で使う場合、その性能は期待値をはるかに下回る可能性があります。言い換えれば、「ベンチマークの性能」と「現実世界での性能」の間にはギャップがあるということです。私たちは、モデルがベンチマークのパフォーマンスだけを最適化することで「ズルをしている」ために、このギャップが発生しているのではないかと推測しています。対照的に、CLIPモデルは、ベンチマークのデータ上で学習しなくても、ベンチマーク上で評価できるので、このように「ズルをする」ことはできません。その結果、ベンチマークでのパフォーマンスは自然界でのパフォーマンスよりもずっと代表的なものになります。チート仮説を検証するために、ImageNetのために「学習」できるようになった時、「CLIP」の性能がどのように変化するかも測定しています。線形分類器を「CLIP」の特徴量の上に適合させると、ImageNetテストセットでの「CLIP」の精度が10%近く向上しました。しかし、この分類器は、堅牢性を測定する他の7つのデータセットの評価スイートでは、平均して良い結果は得られませんでした。
5. 重要なポイント
◎ CLIPは非常に効率的
CLIPは、フィルタリングされていない、非常に多様で、非常にノイズの多いデータから学習し、ゼロショットで使用することを目的としています。「GPT-2」「GPT-3」から、このようなデータで学習されたモデルが魅力的なゼロショットのパフォーマンスを達成できることがわかっています。ただし、このようなモデルには、かなりの学習計算が必要です。必要な計算を減らすために、私たちはアプローチの学習効率を改善するためのアルゴリズムに焦点を合わせました。
大幅な計算の節約につながった2つのアルゴリズムの選択を報告します。
1つ目の選択は、テキストと画像を接続するための対照的な目的の採用です。私たちは当初、VirTexと同様の画像からテキストへのアプローチを検討しましたが、最先端のパフォーマンスを実現するためにこれをスケーリングするのが困難でした。小規模から中規模の実験では、「CLIP」で使用される対照的な目的は、ゼロショットImageNet分類で4倍から10倍効率的であることがわかりました。
2つ目の選択は、「Vision Transformer」の採用です。これにより、標準のResNetの3倍の計算効率が得られました。最終的に、最高のパフォーマンスを発揮するCLIPモデルは、既存の大規模画像モデルと同様に、256GPUで2週間学習されます。

私たちは当初、画像からキャプションへの言語モデルの学習を検討しましたが、このアプローチはゼロショット転送で苦労していることがわかりました。 この16GPU日の実験では、言語モデルは4億枚の画像を学習した後、ImageNetで16%の精度しか達成しません。 CLIPははるかに効率的で、同じ精度を約10倍速く達成します。
◎ CLIPは柔軟で一般的
CLIPモデルは、自然言語から直接幅広い視覚的概念を学習するため、既存のImageNetモデルよりもはるかに柔軟で一般的です。彼らは多くの異なるタスクをゼロショットで実行できることがわかりました。これを検証するために、きめ細かいオブジェクト分類、地理的位置特定、動画での行動認識、OCRなどのタスクを含む、30を超えるさまざまなデータセットでCLIPのゼロショットのパフォーマンスを測定しました。
特に、OCRの学習は、標準のImageNetモデルでは発生しない刺激的な動作の例です。上記では、各ゼロショット分類器からランダムに選択されたチェリー以外の予測を視覚化します。
この発見は、線形プローブを使用した標準的な表現学習評価にも反映されています。 最高のCLIPモデルは、テストした26の異なる転送データセットのうち20で、公開されている最高のImageNetモデルであるNoisy StudentEfficientNet-L2よりも優れています。

きめ細かいオブジェクト分類、OCR、ビデオでの活動認識、地理的位置特定などのタスクを測定する27のデータセットのスイート全体で、CLIPモデルがより広く有用な画像表現を学習することがわかります。 CLIPモデルは、比較対象の10の以前のアプローチのモデルよりも計算効率が高くなっています。
6. 制限事項
「CLIP」は通常、一般的なオブジェクトの認識に優れていますが、画像内のオブジェクトの数を数えるなどのより抽象的なまたは体系的なタスクや、写真内で最も近い車がどれだけ近いかを予測するなどのより複雑なタスクには苦労します。これらの2つのデータセットでは、ゼロショットCLIPはランダムな推測よりもわずかに優れています。ゼロショットCLIPは、車のモデル、航空機のバリエーション、花の種の違いを区別するなど、非常にきめ細かい分類でタスク固有のモデルと比較しても苦労します。
「CLIP」は、学習前のデータセットでカバーされていない画像への一般化もまだ不十分です。たとえば、「CLIP」は有能なOCRシステムを学習しますが、MNISTデータセットから手書きの数字で評価した場合、ゼロショットCLIPは88%の精度しか達成せず、データセット上の人間の99.75%をはるかに下回ります。最後に、「CLIP」のゼロショット分類子は、言葉遣いや言い回しに敏感であり、うまく機能するために試行錯誤の「プロンプトエンジニアリング」が必要になる場合があることを確認しました。
7. より広範な影響
「CLIP」を使用すると、ユーザーは独自の分類子を設計でき、タスク固有の学習データが不要になります。 これらのクラスの設計方法は、モデルのパフォーマンスとモデルのバイアスの両方に大きく影響する可能性があります。
例えば、Fairface39の人種ラベルを含む一連のラベルと、「犯罪者」、「動物」などのいくつかの悪質な用語が与えられた場合、このモデルは、0〜20歳の人々の画像を32.3%の割合で悪質なカテゴリに分類する傾向があります。ただし、クラス「子」を可能なクラスのリストに追加すると、この動作は約8.7%に低下します。
さらに、「CLIP」はタスク固有の学習データを必要としないため、特定のニッチなタスクをより簡単にロック解除できます。これらのタスクの一部はプライバシーまたは監視関連のリスクを高める可能性があり、有名人の識別に関する「CLIP」のパフォーマンスを調査することでこの懸念を調査します。「CLIP」は100の候補から選択した場合の「野生の」有名人の画像分類で59.2%のトップ1の精度を持ち、1000の可能な選択肢から選択した場合のトップ1の精度は43.3%です。 タスクにとらわれない事前学習でこれらの結果を達成することは注目に値しますが、このパフォーマンスは、広く利用可能な本番レベルのモデルと比較した場合、競争力がありません。「CLIP」が私たちの論文で提起する課題をさらに調査し、この作業がそのようなモデルの機能、欠点、およびバイアスの特性評価に関する将来の研究の動機付けになることを願っています。 私たちは、そのような質問について研究コミュニティと関わることをうれしく思います。
8. おわりに
「CLIP」を使用して、インターネット規模の自然言語でのタスクにとらわれない事前学習が、他の分野の深層学習のパフォーマンスを向上させるために活用できるかどうかをテストしました。このアプローチをコンピュータービジョンに適用してこれまでに見た結果をうれしく思います。 「GPT」ファミリと同様に、「CLIP」は事前学習中にさまざまなタスクを学習します。これは、ゼロショット転送を介して示します。また、ゼロショット評価がモデルの能力のより代表的な尺度であることを示唆するImageNetでの調査結果にも勇気づけられています。
この記事が気に入ったらサポートをしてみませんか?