
OpenAI Five

以下の記事が面白かったので、ざっくり訳してみました。
1. OpenAI Five
5つのニューラルネットワークで構成される「OpenAI Five」のチームは、「Dota 2」でアマチュアの人間のチームに勝利を収めるようになりました。
私たちは制限付きでプレーではありますが、8月に「The International」でトッププロのチームを打ち負かすことを目指しています。私たちは成功しないかもしれません。
「Dota 2」は、世界で最も人気があり複雑なeスポーツゲームの1つであり、
年間4,000万ドルの賞金プールの一部を獲得するために年間を通じてトレーニングを行うプロゲーマーがいるます。
「OpenAI Five」は、180年分のゲームを毎日セルフプレイで学習します。「256」のGPUと「128,000」のCPUコアで実行される「PPO」(Proximal Policy Optimization)のスケールアップバージョンを使用してトレーニングします。ヒーローごとに個別の「LSTM」を使用し、人間のデータを使用せずに、認識可能な戦略を学習します。これは強化学習は、プロジェクトを開始する際の私たち自身の期待に反して、大規模だが達成可能な規模で長期計画を生み出すことができることを示しています。
進捗をベンチマークするために、8月5日にトッププレイヤーとの対戦を開催します。Twitchでフォローしてライブブロードキャストを視聴するか、直接参加する招待をリクエストしてください。
2. 問題
AIのマイルストーンの1つは、「StarCraft」や「Dota」などの複雑なビデオゲームで人間の能力を超えることです。チェスや囲碁などの以前のAIマイルストーンに比べて、複雑なビデオゲームは、現実世界の混乱と継続的な性質を捉え始めます。複雑なビデオゲームを解決するシステムが、ゲーム以外のアプリケーションでも使用できることが期待されます。
「Dota 2」は、5人のプレイヤーからなる2つのチーム間でプレイされるリアルタイムストラテジーゲームで、各プレイヤーは「ヒーロー」と呼ばれるキャラクターを操作します。
「Dota 2」をプレイするAIは、以下を習得する必要があります。
◎プレイ時間の長さ
「Dota」は、平均45分間、1秒あたり30フレーム、1ゲームあたり80,000もの行動を選択します。ほとんどの行動(ヒーローに特定の場所に移動するように命じるなど)は個々に与える影響はわずかですが、タウンポータルの使用などの行動は大きな影響を与える戦略的行動です。「OpenAI Five」は4フレームごとに観察し、20,000の行動を生み出します。通常チェスは40、以後は150の行動でゲーム終了し、ほぼ全ての行動が戦略的行動です。
◎不完全情報ゲーム
「Dota」は不完全情報ゲームです。ユニットと建物は、周囲のエリアのみを観察することができます。マップの残りの部分は、敵とその戦略を隠す霧に覆われています。上級プレイには、不完全なデータに基づいて推論を行うことと、対戦相手が何をするかを予測することが必要です。チェスと囲碁は完全情報ゲームになります。
◎高次元の連続行動空間
「Dota」では、各ヒーローは何十もの行動を選択でき、多くの行動は別のユニットまたは地上の位置をターゲットにしています。ヒーローごとに170,000の可能な行動空間を離散化します(クールダウンで呪文を使用するなど、全タイムステップで有効なわけではありません)。連続部分をカウントしない場合、各タイムステップには平均で最大1,000個の有効な行動があります。チェスの行動の平均数は35、囲碁は250になります。
◎高次元の連続観察空間。
「Dota」は、10人のヒーロー、数十の建物、数十のNPCユニット、およびルーン、樹木、病棟などのゲーム機能の長い尾を含む大きな連続したマップでプレイされます。このモデルでは、「Volve Bot API」を介してゲームの状態を、人間がアクセスを許可されているすべての情報を表す20,000(主に浮動小数点)の数値として観察します。チェスは、約70の列挙値(6個のピースとマイナーな履歴情報の8x8盤)、囲碁は約400の列挙値(2ピースタイプとKoの 19x19ボード)になります。
「Dota」のルールも非常に複雑です。ゲームは10年以上にわたって積極的に開発されており、ゲームロジックは数十万行のコードで実装されています。このロジックの実行にはタイムステップ毎にミリ秒かかりますが、チェスまたは囲碁エンジンの場合はナノ秒です。また、ゲームは約2週間に1回更新され、環境のセマンティクスが常に変更されます。
3.私たちのアプローチ
私たちのシステムは、「PPO」の大規模なバージョンを使用して学習します。「OpenAI Five」と以前開発した「OpenAI 1v1 Bot」の両方は、完全に自己プレイから学習します。これらはランダムなパラメーターで始まり、人間のリプレイからの探索またはブートストラップを使用しません。

私たちを含む強化学習の研究者は、長期的な視野には「階層強化学習」などの根本的に新しい進歩が必要であると考えていました。私たちの結果は、少なくとも十分な規模で合理的な探索方法で実行されている場合、今日のアルゴリズムに十分な信用を与えていないことを示唆しています。
エージェントは、γと呼ばれる減衰係数で重み付けされた、指数関数的に減衰する将来の報酬の合計を最大化するように訓練されています。「OpenAI Five」の最新のトレーニングで、γを0.998(46秒の半減期で将来の報酬を評価)から0.9997(5分の半減期で将来の報酬を評価)にアニールしました。PPO論文の最長期間は0.5秒の半減期であり、Rainbow論文の最長期間は4.4秒の半減期であり、Observe and Look Additional論文の半減期は46秒になります。
「OpenAI Five」の現在のバージョンは「ラストヒッティング」が苦手ですが、その客観的な優先順位付けは一般的なプロの戦略と一致しています
(テストマッチを観察し、プロのDotaコメンテーター「Blitz」がDotaプレイヤーの中央値を推定)。戦略的なマップコントロールなどの長期的な報酬を獲得するには、攻撃タワーへのグループ化に時間がかかるため、農業から獲得した金などの短期的な報酬を犠牲にすることが必要になることがよくあります。この観察は、システムが長期にわたって真に最適化されているという私たちの信念を強固にします。
4. モデル構造
「OpenAI Five」の各ネットワークには、現在のゲームの状態(Valve Bot APIから抽出された)を確認し、いくつかの可能な行動ヘッドから行動を発行する、単一層の1024ユニット「LSTMが」含まれています。各ヘッドにはセマンティックな意味があります。たとえば、この行動を遅らせるタイムステップ数、選択する行動、ユニットの周囲のグリッド内のこの行動のXY座標などです。行動ヘッドは独立して計算されます。
「OpenAI Five」は、世界を20,000個の数字のリストと見なし、8つの列挙値のリストを出力することにより行動を実行します。さまざまな行動とターゲットを選択して、「OpenAI Five」が各行動をエンコードする方法と、それが世界を観察する方法を理解します。以下の画像は、人間が見るシーンを示しています。
「OpenAI Five」は、表示されているものと相関する欠落した状態の断片に反応できます。たとえば、最近まで「OpenAI Five」の観察には、人間が画面に表示する shrapnel ゾーン(発射体が敵に降り注ぐ領域)が含まれていませんでした。ただし、「OpenAI Five」は、その健康状態が低下するのを見ることができるため、アクティブなshrapnel ゾーンから(入ることを避けませんが)立ち去ることを学習しました。
5. 探索
長い視野を扱うことができる学習アルゴリズムを考えるには、環境を調査する必要があります。私たちの制限にもかかわらず、数百のアイテム、数十の建物、呪文、ユニットの種類、そして学ぶべきゲームの仕組みがあります。
その多くは強力な組み合わせを生み出します。この組み合わせの広大な空間を効率的に探索するのは簡単ではありません。
「OpenAI Five」は、環境を探索するための自然なカリキュラムを提供するセルフプレイ(ランダムな重みから開始)から学習します。「戦略の崩壊」を避けるために、エージェントは自身のゲームの80%を訓練し、他の20%は過去の自己を訓練します。最初のゲームでは、ヒーローはマップをあてもなく歩きます。数時間のトレーニングの後、レーニング、農業、または半ばでの戦闘などの概念が現れます。数日後、彼らは一貫して基本的な人間の戦略を採用します。バウンティルーンを敵から盗み、タワーまで歩いて農場を作り、ヒーローをマップ上で回転させてレーンのアドバンテージを獲得します。さらにトレーニングを重ねることで、高度な戦略に習熟します。
2017年3月、最初のエージェントはボットを打ち負かしましたが、人間に対しては混乱しました。戦略空間での探索を強制するために、トレーニング中(およびトレーニング中のみ)、ユニットのプロパティ(健康、速度、開始レベルなど)をランダム化し、人間を倒し始めました。その後、テストプレーヤーが1v1ボットを常に叩いているときに、トレーニングのランダム化を増やし、テストプレーヤーが負け始めました(当社のロボットチームは、物理ロボットに同様のランダム化手法を同時に適用して、シミュレーションから実世界に移行しました)。
「OpenAI Five」は、1v1ボット用に作成したランダム化を使用します。また、新しい「レーン割り当て」を使用します。各トレーニングゲームの開始時に、各ヒーローをレーンの一部のサブセットにランダムに割り当て、ゲーム内でランダムに選択された時間まで、それらのレーンからの逸脱に対してペナルティを科します。
探検も良い報酬によって助けられます。私たちの報酬は、主に人間がゲームでどのように行動しているかを決定するために追跡する指標で構成されています(純資産、キル、デス、アシスト、ラストヒットなど)。他のチームの平均報酬を差し引くことで、各エージェントの報酬を後処理し、エージェントがプラスサムの状況を見つけられないようにします。
アイテムビルドとスキルビルド(スクリプトベースライン用に元々作成されたもの)をハードコーディングし、ランダムに使用するビルドを選択します。クーリエ管理も、スクリプト化されたベースラインからインポートされます。
6. 調整
「OpenAI Five」には、ヒーローのニューラルネットワーク間の明示的な通信チャネルが含まれていません。チームワークは、「チームスピリット」と呼ばれるハイパーパラメーターによって制御されます。チームの精神は0から1の範囲であり、「OpenAI Five」のヒーローのそれぞれがチームの報酬機能の平均に対して個々の報酬機能をどれだけ気にかけるかを重視しています。トレーニング中に0から1の値をアニールします。
7. Rapid
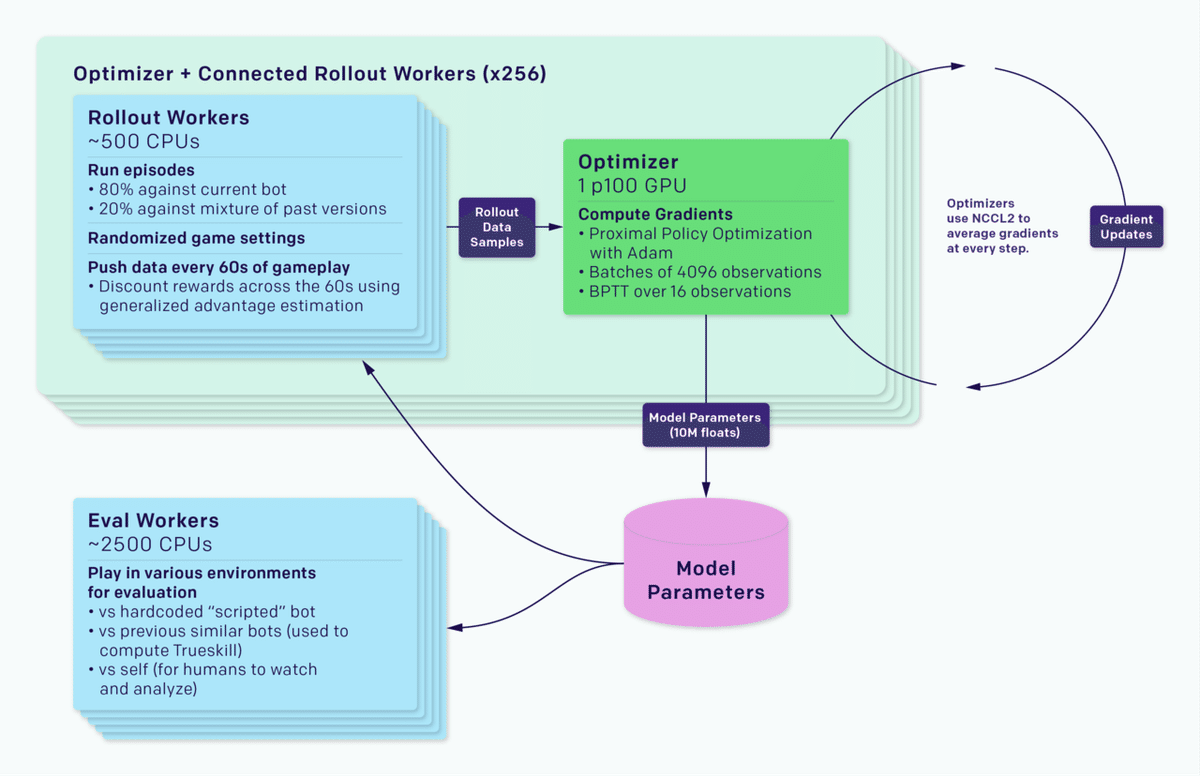
このシステムは、「Rapid」と呼ばれる汎用強化学習RLトレーニングシステムとして実装されており、あらゆるGym環境に適用できます。「RapidAI」を使用して、競合AIを含むOpenAIの他の問題を解決しました。
トレーニングシステムは、ゲームのコピーを実行するロールアウトワーカーと経験を収集するエージェント、およびGPUのフリート全体で同期勾配降下を実行するオプティマイザーノードに分かれています。ロールアウトワーカーは、Redisを介してオプティマイザーにエクスペリエンスを同期します。各実験には、トレーニング済みのエージェントと参照エージェントを評価するワーカー、およびTensorBoard、Sentry、Grafanaなどの監視ソフトウェアも含まれています。
同期勾配降下中に、各GPUはバッチの一部で勾配を計算し、勾配はグローバルに平均化されます。当初は平均化にMPIのallreduceを使用していましたが、現在はGPU計算とネットワークデータ転送を並列化する独自のNCCL2ラッパーを使用しています。異なる数のGPU間で58MBのデータ(OpenAI Fiveのパラメーターのサイズ)を同期するためのレイテンシーを右側に示します。レイテンシーは十分に低く、それと並行して実行されるGPU計算によって大部分がマスクされます。
Rapid用にKubernetes、Azure、およびGCPバックエンドを実装しました。
8. ゲーム
これまでに、「OpenAI Five」はこれらの各チームに対して(私たちの制限付きで)プレイしています。
・最高のOpenAI従業員チーム:2.5k MMR(46パーセンタイル)
・OpenAIの従業員の試合を観戦した最高の視聴者(OpenAIの最初の従業員の試合をコメントしたBlitzを含む):4-6k MMR(90〜99パーセンタイル)。
ただし、チームとしてプレーしたことはありません。
・バルブ従業員チーム:2.5〜4k MMR(46〜90パーセンタイル)。
・アマチュアチーム:4.2k MMR(93パーセンタイル)、チームとしてトレーニング。
・セミプロチーム:5.5k MMR(99パーセンタイル)、チームとしてトレーニングします。
「OpenAI Five」の4月23日バージョンは、スクリプトベースラインを打ち破った最初のバージョンです。「OpenAI Five」の5月15日バージョンは、チーム1と均等にマッチし、1つのゲームに勝ち、別のゲームに負けました。「OpenAI Five」の6月6日バージョンは、チーム1〜3に対してすべてのゲームを決定的に勝ち取りました。私たちはチーム4と5で非公式のスクリムを設定し、健全な敗北を予想しましたが、「OpenAI Five」は最初の3ゲームのうち2ゲームで勝利しました。
「OpenAI Five」は次のことを確認しました。
敵の安全なレーンを制御することと引き換えに、自身の安全なレーン(悲惨な場合は一番上のレーン、放射する場合は一番下のレーン)を繰り返し犠牲にし、敵が防御するのが難しい側に戦いを強制しました。この戦略は、ここ数年でプロのシーンで出現し、現在では一般的な戦術と見なされています。Blitzは、Team Liquidがそれについて彼に話したとき、彼はこれを8年間のプレーの後に初めて学んだとコメントしました。
対戦相手よりも早くゲームの初期から中期への移行を推進しました。
(1) プレイヤーがレーンを超えて延長した場合に、成功したギャンクをセットアップする(プレイヤーが敵ヒーローを待ち伏せするためにマップを移動するとき—アニメーションを参照)
(2) 敵が編成する前にグループ化してタワーを取るカウンタープレイ
サポートヒーロー(通常はリソースを優先しない)に多くの初期経験とゴールドを与えるなど、いくつかの領域で現在のプレイスタイルから逸脱しました。OpenAI Fiveの優先順位付けにより、ダメージがより早くピークに達し、その優位性をより強く押し上げ、チームの戦いに勝ち、ミスを利用して速い勝利を確実にします。
9. 人間との違い
「OpenAI Five」は、人間と同じ情報へのアクセスを許可されていますが、人間が手動で確認する必要がある位置、健康状態、アイテムインベントリなどのデータを即座に確認できます。私たちの方法は、基本的に状態の監視とは関係ありませんが、ゲームからピクセルをレンダリングするだけで数千のGPUが必要になります。
「OpenAI Five」は、1分あたり平均150〜170の行動を実行します(4番目のフレームごとに観測されるため、理論上の最大値は450です)。フレーム完璧なタイミングは、熟練したプレーヤーにとっては可能ですが、「OpenAI Five」にとっては些細なことです。「OpenAI Five」の平均反応時間は80ミリ秒で、これは人間よりも高速です。
これらの違いは1v1(ボットの反応時間は67ミリ秒)で最も重要ですが、人間がボットから学習し、適応するのを見て、競技場は比較的公平です。昨年のTI以降、数十人の専門家が1v1ボットをトレーニングに使用しました。Blitzによると、1v1ボットは1v1についての人々の考え方を変えました(ボットはペースの速いプレイスタイルを採用し、誰もが追いつくようになりました)。
10. 驚くべき発見
・「バイナリ報酬」は、優れたパフォーマンスを提供できる。
1v1モデルには、最後のヒットやキルなどの報酬を含む、形を整えた報酬がありました。
私たちは、勝ち負けに対してのみエージェントに報酬を与える実験を行い、通常見られる滑らかな学習曲線とは対照的に、1桁遅く、途中でやや停滞した状態で訓練しました。
この実験は4,500コアと16 k80 GPUで実行され、最高の1v1ボットの90 TrueSkillではなく、準プロ(70 TrueSkill)のレベルまでトレーニングされました。
・クリープブロックはゼロから学習できる。
1v1では、従来の強化学習を使用してクリープブロックを学習し報酬を受け取りました。
私たちのチームメンバーの1人は、休暇中に2v2モデルトレーニングを辞め、
トレーニングがどれだけ長くなるとパフォーマンスが向上するかを確認しようとしました。
驚いたことに、モデルは特別なガイダンスや報酬なしでクリープブロックを学びました。
・まだバグを修正している。
チャートは、アマチュアプレイヤーを倒したコードのトレーニング実行を示しています。
これは、トレーニング中のまれなクラッシュや、レベル25に達すると大きな負の報酬をもたらすバグなど、
いくつかのバグを単に修正したバージョンと比較しています。
深刻なバグを隠しながら、善良な人間を倒すことが可能であることがわかりました。
11. 今後の展望
私たちのチームは、8月の目標の達成に注力しています。それが達成可能かどうかはわかりませんが、一生懸命働いて(そして少し運が良ければ)祝杯があげられると信じています。
この投稿では、6月6日現在のシステムのスナップショットについて説明しました。人間のパフォーマンスを上回る方法でアップデートをリリースし、プロジェクトが完了したら最終システムに関するレポートを作成します。8月5日のトッププレイヤーのチームとの対戦はぜひ直接見てください。
私たちの根底にある動機は「Dota」を超えています。実際のAIの展開では、チェス、囲碁、Atariゲーム、Mujocoなどベンチマークタスクに反映されない「Dota」によって提起された課題に対処する必要があります。最終的に、実世界のタスクへの適用における「Dota」システムの成功を評価します。
この記事が気に入ったらサポートをしてみませんか?