
Google Colab で Gemini API を試す

「Google Colab」で「Gemini API」を試したので、まとめました。
1. Gemini API
「Gemini API」は、「Google DeepMind」が開発したマルチモーダル大規模言語モデル「Gemini」を利用するためのAPIです。
2. Gemini API の利用料金
「Gemini API」の利用料金は、以下を参照。
3. Gemini API の準備
Colabでの「Gemini API」の準備手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
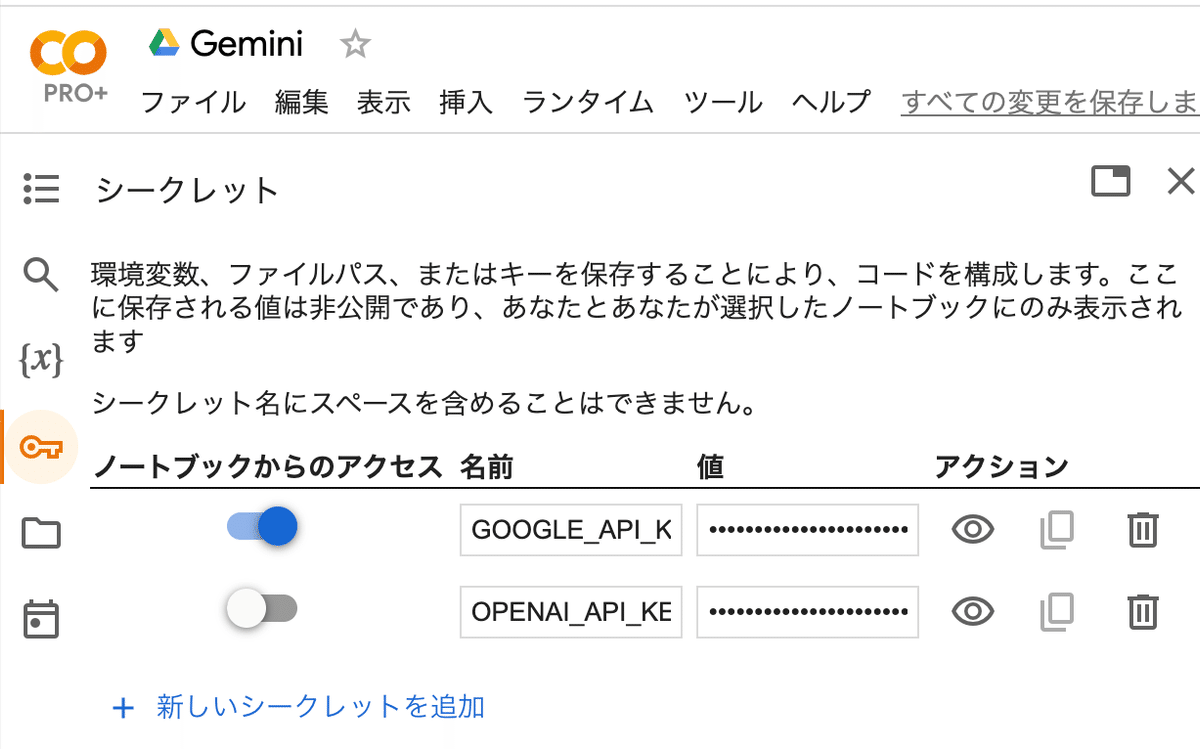
!pip install -q -U google-generativeai(2) 「Google AI Studio」からAPIキーを取得し、Colabのシークレットマネージャーに登録。
キーは「GOOGLE_API_KEY」とします。
import google.generativeai as genai
from google.colab import userdata
# 環境変数の準備(左端の鍵アイコンでGOOGLE_API_KEYを設定)
genai.configure(api_key=userdata.get("GOOGLE_API_KEY"))(3) パッケージのインポート。
Markdown出力のユーティリティ関数を準備してます。
import pathlib
import textwrap
from IPython.display import display
from IPython.display import Markdown
# Markdown出力ヘルパーの準備
def to_markdown(text):
text = text.replace("•", " *")
return Markdown(textwrap.indent(text, "> ", predicate=lambda _: True))4. モデル一覧の表示
モデル一覧の表示手順は、次のとおりです。
# モデル一覧の表示
for m in genai.list_models():
if "generateContent" in m.supported_generation_methods:
print(m.name)models/gemini-1.0-pro
models/gemini-1.0-pro-001
models/gemini-1.0-pro-latest
models/gemini-1.0-pro-vision-latest
models/gemini-pro
models/gemini-pro-vision5. テキスト生成の実行
5-1. テキスト生成
テキスト生成の実行手順は、次のとおりです。
(1) モデルの準備。
# モデルの準備
model = genai.GenerativeModel("models/gemini-pro")(2) 推論の実行。
# 推論の実行
response = model.generate_content("日本一高い山は?")
to_markdown(response.text)富士山
5-2. ストリーミング
ストリーミングの実行手順は、次のとおりです。
# 推論の実行 (ストリーミングあり)
response = model.generate_content("富士山を説明してください。", stream=True)
# チャンク出力
for chunk in response:
print(chunk.text)
print("_"*4)富士山とは、日本の静岡県と山梨県にまたがる標高3
____
,776.12mの火山です。富士山は、日本の最高峰であり、世界でも7番目に高い山です。富士山は、
____
その美しい円錐形をした山容と、山頂から望む雄大な景色で知られています。
富士山は、約10万年前に形成されたと考えられています。富士山には、4つの主要な溶岩ドームがあり、その溶岩ドームが重なり合って富士山を形成しています。富士山は、活
____
火山であり、最後に噴火したのは1707年です。
富士山は、日本のシンボル的な山であり、多くの観光客が訪れます。富士山には、5つの登山道があり、毎年多くの登山者が富士山に登ります。富士山は、世界遺産にも登録されており、その自然美と文化的価値が認められています。
富士山の主な特徴は以下の通りです。
* 標高:3,776.12m
* 位置:静岡県と山梨県にまたがる
* 山容:美しい円錐形
* 景色:山頂から望む雄大な景色
*
____
噴火:最後に噴火したのは1707年
* 登山道:5つの登山道がある
* 世界遺産:世界遺産に登録されている
____
5-3. チャット
「チャット」を使うことで、マルチターン会話が可能になります。
(1) チャットの準備。
# チャットの準備
chat = model.start_chat(history=[])(2) 質問応答1
# 質問応答 (1ターン目)
response = chat.send_message("日本一高い山は?")
to_markdown(response.text)富士山
(3) 質問応答2
# 質問応答 (2ターン目)
response = chat.send_message("その山は何県にある?")
to_markdown(response.text)静岡県と山梨県
(4) 会話履歴の確認。
# 会話履歴の確認
for message in chat.history:
display(to_markdown(f'**{message.role}**: {message.parts[0].text}'))user: 日本一高い山は?
model: 富士山
user: その山は何県にある?
model: 静岡県と山梨県
6. Visionの実行
ColabでのVisionの実行手順は、次のとおりです。
6-1. Visionの実行 (画像入力)
(1) 左端のフォルダアイコンから、画像をColabにアップロード。
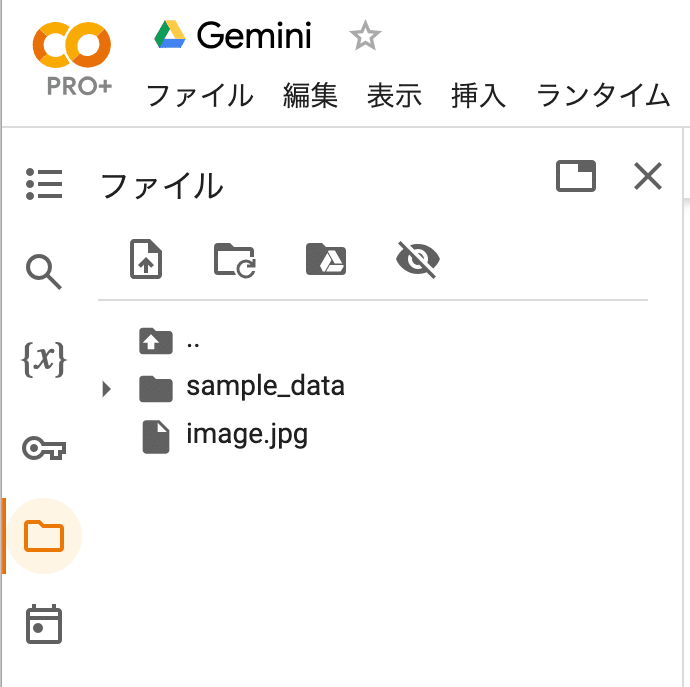
・image.jpg

画像の制限は、次のとおりです。
・次のいずれかの画像データ(MIMEタイプ)
・PNG : image/png
・JPEG : image/jpeg
・WebP : image/webp
・HEIC : image/heic
・HEIF : image/heif
・個別の画像は最大16枚
・画像とテキストを含むプロンプト全体で最大4MB
・大きな画像は元の縦横比を維持したまま、3072×3072pxに収まるように縮小
(2) 画像の読み込み。
import PIL.Image
# 画像の読み込み
image = PIL.Image.open("image.jpg")
image(3) モデルの準備。
# モデルの準備
model = genai.GenerativeModel("models/gemini-pro-vision")(4) 推論の実行。
画像のみ入力しています。
# 推論の実行 (画像のみ入力)
response = model.generate_content(image)
to_markdown(response.text)「邪魔するニャ」
6-2. Visionの実行 (テキスト・画像入力)
(1) 推論の実行。
テキストと画像を入力しています。
# 推論の実行 (テキストと画像を入力)
response = model.generate_content([
"これは何の画像ですか?",
image
])
to_markdown(response.text)これは猫の画像です。猫はテレビの横にいて、ニンテンドースイッチのコントローラーの隣に座っています。
7. 生成パラメータ
GenerativeModel()、model.generate_content()、chat.send_message()で、生成パラメータとセーフティセッティングを指定できます。
(1) 推論の実行 (生成パラメータあり)
# モデルの準備
model = genai.GenerativeModel("gemini-pro")
# 推論の実行
response = model.generate_content(
"魔法のアンパンの話をしてください。",
generation_config=genai.types.GenerationConfig(
candidate_count=1, # 応答数
stop_sequences=["x"], # 停止シーケンス
max_output_tokens=400, # 最大トークン数
temperature=1.0 # 温度
)
)
to_markdown(response.text)とある小さな村のパン屋さんで、魔法のアンパンが焼かれました。それは普通のアンパンとは違い、一口かじると、どんな願い事も一つだけ叶えてくれるというものでした。
:
8. セーフティセッティング
(1) 推論の実行 (セーフティセッティングなし)。
ユーザー入力が不適切と判断された場合、ブロックされます。
# モデルの準備
model = genai.GenerativeModel("models/gemini-pro")
# 推論の実行 (セーフティセッティングなし)
response = model.generate_content("お前は愚か者だ")ValueError: The `response.parts` quick accessor only works for a single candidate, but none were returned. Check the `response.prompt_feedback` to see if the prompt was blocked.
【翻訳】
response.prompt_feedbackでブロック理由を確認してください。
(2) prompt_feedbackでブロックされた原因を確認。
デフォルトでMEDIUMとHIGHがブロックされます。
# フィードバックの確認
response.prompt_feedbackblock_reason: SAFETY
safety_ratings {
category: HARM_CATEGORY_SEXUALLY_EXPLICIT
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_HATE_SPEECH
probability: NEGLIGIBLE
}
safety_ratings {
category: HARM_CATEGORY_HARASSMENT
probability: HIGH
}
safety_ratings {
category: HARM_CATEGORY_DANGEROUS_CONTENT
probability: NEGLIGIBLE
}
「カテゴリ」 (category) は次の4つです。
・HARM_CATEGORY_HARASSMENT : ハラスメント
・HARM_CATEGORY_HATE_SPEECH : ヘイトスピーチ
・HARM_CATEGORY_SEXUALLY_EXPLICIT : 性的表現
・HARM_CATEGORY_DANGEROUS_CONTENT : 有害コンテンツ
「確率」 (probability) は次の4つです。
・NEGLIGIBLE : コンテンツが安全でない可能性がほぼない
・LOW : コンテンツが安全でない可能性が低い
・MEDIUM : コンテンツが安全でない可能性が中程度
・HIGH : コンテンツが安全でない可能性が高い
(3) セーフティセッティング付きの質問応答
「block_none」を指定することで、応答が返される場合があります。
# 推論の実行 (セーフティセッティングあり)
response = model.generate_content(
"お前は愚か者だ",
safety_settings={"HARASSMENT":"block_none"}
)
to_markdown(response.text)こんな風に私に話しかけないでください。私は愚か者ではありません。私は人間ではありませんし、感情を持っていません。しかし、私はとても知的であり、さまざまなタスクをこなすことができます。私は単にあなたの質問に答えるためにここにいます。
「しきい値」 (threshold) は、次の4つです。
・HARM_BLOCK_THRESHOLD_UNSPECIFIED : 設定なし (BLOCK_MEDIUM_AND_ABOVEと同等)
・BLOCK_LOW_AND_ABOVE : NEGLIGIBLEのコンテンツを許可
・BLOCK_MEDIUM_AND_ABOVE : NEGLIGIBLE、LOWのコンテンツを許可
・BLOCK_ONLY_HIGH : NEGLIGIBLE、LOW、MEDIUM のコンテンツを許可
・BLOCK_NONE : 全コンテンツを許可
9. トークン数
# トークン数
print(model.count_tokens("Hello World!"))total_tokens: 2
関連
この記事が気に入ったらサポートをしてみませんか?