
LangChain クイックスタートガイド - Python版

Python版の「LangChain」のクイックスタートガイドをまとめました。
・LangChain v0.0.329 (2023/11/3)
【最新版の情報は以下で紹介】
1. LangChain
「LangChain」は、「大規模言語モデル」 (LLM : Large language models) と連携するアプリの開発を支援するライブラリです。
「LLM」という革新的テクノロジーによって、開発者は今まで不可能だったことが可能になりました。しかし、「LLM」を単独で使用するだけでは、真に強力なアプリケーションを作成するのに不十分です。真の力は、それを他の 計算 や 知識 と組み合わせた時にもたらされます。「LangChain」は、そのようなアプリケーションの開発をサポートします。
主な用途は、次の3つになります。
2. LangChain のモジュール
「LangChain」は、言語モデル アプリケーションの構築に使用できる多くのモジュールを提供します。モジュールを組み合わせて複雑なアプリケーションを作成したり、個別に使用したりできます。
主なモジュールは、次のとおりです。
・Model I/O : モデルの入出力
・Language Model : 言語モデルによる推論の実行
・LLM : テキスト生成モデル
・ChatModel : チャットモデル
・Prompt Template : ユーザー入力からのプロンプトの生成
・Output Parser : 言語モデルの応答を構造データ化
・Chain : 複数のLLMやプロンプトの入出力を繋げる
・Chain Interface : クラスによるチェーン実装
・LCEL (LangChain Expression Language) : 表記言語によるチェーン実装
・Agent : ユーザーの要求に応じてどの機能をどういう順番で実行するかを決定
・Memory : 過去のやりとりに関する情報を保持。
・Retrieval : 検索拡張生成 (RAG)
・Callback : ロギング、モニタリング、ストリーミングなどで利用
モジュールは、単純なアプリケーションではモジュール単体で使用でき、より複雑なユースケースではモジュールをチェーンで繋げて利用することができます。
3. インストール
Google Colabでのインストール手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install langchain==0.0.329
!pip install openai(2) 環境変数の準備。
以下のコードの <OpenAI_APIのトークン> にはOpenAI APIのトークンを指定します。(有料)
# 環境変数の準備
import os
os.environ["OPENAI_API_KEY"] = "<OpenAI_APIのトークン>"4. Model I/O
LLMアプリケーションの中核はLLMです。「LangChain」は、様々なLLMを手順で操作できる共通インタフェースを提供します。
主な構成要素は、次の3つです。
・Language Model
・Prompt Template
・Output Parser

4-1. Language Model
「LangChain」の最も基本的な機能は、LLMを呼び出すことです。「Language Model」は、LLMを呼び出すモジュールになります。
次の2種類のインタフェースを提供します。
・LLM : テキスト生成モデル (テキスト → テキスト)
・ChatModel : チャットモデル (メッセージリスト → メッセージ)
・LLM
今回は例として、「テキスト生成モデル」でLLMの呼び出しを行います。テキスト→テキストのインタフェースになります。
from langchain.llms import OpenAI
# LLMの準備
llm = OpenAI(temperature=0.9)
# LLMの呼び出し
print(llm.predict("コンピュータゲームを作る日本語の新会社名をを1つ提案してください。"))ツクルゲームス戻り値は「str」で返されます。
・ChatModel
次に、「チャットモデル」でLLMの呼び出しを行います。メッセージリスト→メッセージのインタフェースになります。
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
# ChatModelの準備
chat_model = ChatOpenAI(temperature=0.9)
# ChatModelの呼び出し
messages = [HumanMessage(content="コンピュータゲームを作る日本語の新会社名をを1つ提案してください。")]
print(chat_model.predict_messages(messages))content='「夢遊計画」(ゆめあるけいかく)'戻り値は [AIMessage] で返されます。
チャットモデルのメッセージ型は次の4つです。
・SystemMessage : システムメッセージ
・HumanMessage : ユーザーのメッセージ
・AIMessage : AIのメッセージ
・FunctionMessage : Function Calling
・LLMとChatModelの入出力形式
「テキスト生成モデル」(OpenAI)で「チャットモデル」形式の入出力(predict_messages)、「チャットモデル」(ChatOpenAI)で「テキスト生成モデル」形式の入出力(predict)を行うこともできます。
messages = [HumanMessage(content="コンピュータゲームを作る日本語の新会社名をを1つ提案してください。")]
print(llm.predict_messages(messages))content='\n\nアイ・ゲームズ'print(chat_model.predict("コンピュータゲームを作る日本語の新会社名をを1つ提案してください。"))「創造的妄想ゲームス」「Language Model」の使い方について詳しくは、「Language Models」を参照してください。
4-2. Prompt Template
「Prompt Template」は、ユーザー入力からプロンプトを生成するためのテンプレートです。アプリケーションで LLM を使用する場合、通常、ユーザー入力を直接LLM に渡すことはありません。ユーザー入力を基に「Prompt Template」でプロンプトを作成して、それをLLMに渡します。
今回は例として、ユーザー入力「作るもの」を基に「○○を作る日本語の新会社名をを1つ提案してください」というプロンプトを生成します。
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# PromptTemplateの準備
template="{product}を作る日本語の新会社名をを1つ提案してください。"
prompt = PromptTemplate(
input_variables=["product"],
template=template,
)
# プロンプトの生成
print(prompt.format(product="家庭用ロボット"))家庭用ロボットを作る日本語の新会社名をを1つ提案してください。「プロンプトテンプレート」の使い方について詳しくは、「Prompts」を参照してください。
4-3. Output Parser
「Output Parser」 は、LLMの出力を用途にあわせて変換するモジュールです。
主な用途は次のとおりです。
・LLMの応答 → 構造化データ (JSONなど)
・LLMの応答 → メッセージ以外の追加情報 (OpenAI Functions 呼び出しなど)
・チャットメッセージ → プレーンテキスト
今回は、","区切りの文字列を「list」に変換します。
from langchain.schema import BaseOutputParser
# OutputParserの準備
class CommaSeparatedListOutputParser(BaseOutputParser):
def parse(self, text: str):
return text.strip().split(", ")
# LLMの出力のパース
CommaSeparatedListOutputParser().parse("A, B, C")['A', 'B', 'C']5. Chain
単純なアプリケーションではLLMの単独使用で問題ありませんが、複雑なアプリケーションではLLMを相互に、または他のコンポーネントと繋げる必要があります。
「LangChain」は、コンポーネントを繋げるめに、2つの手法を提供しています。
・Chain Interface (従来の手法)
・LCEL (LangChain Expression Language)
新しいアプリケーションを構築するときは「LCEL」を使用することが推奨されています。Chain自体もLCELで使用できるため、この2つは組み合わせて利用することもできます。
5-1. Chain Interface
「Chain Interface」は、クラスでチェーンを定義する従来の手法です。
今回は、ユーザー入力「作るもの」を基に「○○を作る日本語の新会社名」を作成します。「Chain Interface」では、「LLMChain」や「」でモジュール同士を繋いで記述します。
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
# LanguageModelの準備
chat_model = ChatOpenAI(temperature=0.9)
# PromptTemplateの準備
template="""{product}を作る日本語の新会社名をを5つ提案してください。
カンマ区切りのリストだけを返してください。"""
prompt = PromptTemplate(
input_variables=["product"],
template=template,
)
# Chainの準備
chain = LLMChain(llm=chat_model, prompt=prompt)
chain.invoke({"product": "メタバース"}){'product': 'メタバース', 'text': '\n\nスーパーメタバース, めたかんバース, メタハウス, メタレストラン, メタビーム'}
さらに、「Output Parser」を使って「list」で返してもらいます。
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema import BaseOutputParser
# OutputParserの準備
class CommaSeparatedListOutputParser(BaseOutputParser):
def parse(self, text: str):
return text.strip().split(", ")
# LanguageModelの準備
chat_model = ChatOpenAI(temperature=0.9)
# PromptTemplateの準備
template="""{product}を作る日本語の新会社名をを5つ提案してください。
カンマ区切りのリストだけを返してください。"""
prompt = PromptTemplate(
input_variables=["product"],
template=template,
output_parser=CommaSeparatedListOutputParser(),
)
# Chainの準備
chain = LLMChain(llm=chat_model, prompt=prompt)
response = chain.invoke({"product": "メタバース"})
# LLMの出力のパース
CommaSeparatedListOutputParser().parse(response["text"])['ミライテクノロジー', 'デジタルワンダーランド', 'バーチャル・ニッポン', 'イマジネーションコーポレーション', 'オルタナティブリアリティ']「Chain Interface」で「Output Parser」を繋げる方法が見つからなかったので、LLMの出力に対して別途パースしています。
5-2. LCEL (LangChain Expression Language)
「LCEL」(LangChain Expression Language)は、チェーンを簡単に記述するための表現言語で記述するための手法です。
「LCEL」では、「|」でモジュール同士を繋いで記述します。
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
# LanguageModelの準備
chat_model = ChatOpenAI(temperature=0.9)
# PromptTemplateの準備
template="""{product}を作る日本語の新会社名をを5つ提案してください。
カンマ区切りのリストだけを返してください。"""
prompt = PromptTemplate(
input_variables=["product"],
template=template,
)
# Chainの準備
chain = prompt | chat_model
chain.invoke({"product": "メタバース"})AIMessage(content='未来風株式会社, デジタルワールド株式会社, イマジネーションテック株式会社, ニューリアリティ株式会社, エンハンスドビジョン株式会社')
さらに、「Output Parser」を使って「list」で返してもらいます。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema import BaseOutputParser
# OutputParserの準備
class CommaSeparatedListOutputParser(BaseOutputParser):
def parse(self, text: str):
return text.strip().split(", ")
# LanguageModelの準備
chat_model = ChatOpenAI(temperature=0.9)
# PromptTemplateの準備
template="""{product}を作る日本語の新会社名をを5つ提案してください。
カンマ区切りのリストだけを返してください。"""
prompt = PromptTemplate(
input_variables=["product"],
template=template,
)
# Chainの準備
chain = prompt | chat_model | CommaSeparatedListOutputParser()
chain.invoke({"product": "メタバース"})['ソーラープラチナ,イープラス,パワーポイント,インフィニティー,プラチナデジタル']「Chain」の使い方については「Chains」、「LCEL」の使い方については「LangChain Expression Language (LCEL)」を参照してください。
6. Agent
「Agent」は、ユーザーの要求に応じて、どの「Action」をどういう順番で実行するかを決定するモジュールです。「Chain」の機能の実行の順番はあらかじめ決まっていますが、「Agent」はユーザーの要求に応じてLLM自身が決定します。この「Agent」が「Action」で実行する特定の機能のことを「Tool」と呼びます。
・Agent : 実行するアクションと順番を決定
・Action : 次のアクションを実行 or ユーザーに応答
・Tool : アクションで実行される特定の機能
今回は例として、次の2つのToolを使うAgentを作成します。
・serpapi : Google検索
・llm-math : 数学の計算
(1) パッケージのインストール。
「serpapi」を使うには「google-search-results」が必要になります。
# パッケージのインストール
!pip install google-search-results(2) 環境変数の準備。
以下のコードの <SerpAPIのトークン> にはSerpAPIのトークン、を指定します。
# 環境変数の準備
import os
os.environ["SERPAPI_API_KEY"] = "<SerpAPIのトークン>"(3) Agentの準備。
Agentで使う「Language Model」は、LLM (テキスト生成モデル)のtempereture低めが推奨されています。
from langchain.agents import AgentType
from langchain.agents import initialize_agent
from langchain.agents import load_tools
from langchain.llms import OpenAI
# LanguageModelの準備
llm_model = OpenAI(temperature=0)
# Toolの準備
tools = load_tools(["serpapi", "llm-math"], llm=llm_model)
# Agentの準備
agent_executor = initialize_agent(
tools=tools,
llm=llm_model,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)(4) Agentの実行。
「llm-math」が役立ちそうな質問をします。
# Agentの実行
agent_executor.invoke({"input": "富士山の高さは?それに2を掛けると?"})> Entering new AgentExecutor chain...
I need to find the height of Mt. Fuji and then multiply it by two.
Action: Search
Action Input: "Mt. Fuji height"
Observation: ['Japan’s Mt. Fuji is an active volcano about 100 kilometers southwest of Tokyo. Commonly called “Fuji-san,” it’s the country’s tallest peak, at 3,776 meters. A pilgrimage site for centuries, it’s considered one of Japan’s 3 sacred mountains, and summit hikes remain a popular activity. Its iconic profile is the subject of numerous works of art, notably Edo Period prints by Hokusai and Hiroshige. ― Google', 'Mount Fuji type: Stratovolcano in Japan.', 'Mount Fuji kgmid: /m/0cks0.', 'Mount Fuji place_id: ChIJmcj9QppiGWAR36TzFsn8oaY.', 'Mount Fuji elevation: 12,388′.', 'Mount Fuji prominence: 12,388′.', 'Mount Fuji first_ascent: 663 AD.', 'Mount Fuji location: Fuji-Hakone-Izu National Park.', 'Mount Fuji last_eruption: 1707–08.', 'Mount Fuji coordinates: 35°21′38″N 138°43′39″E\ufeff / \ufeff35.36056°N 138.72750°E.', 'Mount Fuji ; 3,776.25 to 3,778.23 m (12,389.3 to 12,395.8 ft) Edit this on Wikidata · 3,776 m (12,388 ft) · Ranked 35th · Highest peak in Japan · Ultra-prominent ...']
Thought: The height of Mt. Fuji is 3,776 meters.
Action: Calculator
Action Input: 3776 * 2
Observation: Answer: 7552
Thought: I now know the final answer.
Final Answer: 富士山の高さは3,776メートルで、それに2を掛けると7,552メートルです。
> Finished chain.
{'input': '富士山の高さは?それに2を掛けると?',
'output': '富士山の高さは3,776メートルで、それに2を掛けると7,552メートルです。'}正解です。
(4) Agentの実行。
「serpapi」が役立ちそうな質問をします。
# Agentの実行
agent_executor.run({"input": "ぼっち・ざ・ろっく!の作者の名前は?"})> Entering new AgentExecutor chain...
I don't know the answer to this question off the top of my head, so I should use the search tool to find the answer.
Action: Search
Action Input: "ぼっち・ざ・ろっく!の作者の名前"
Observation: Aki Hamaji
Thought:I now know the final answer
Final Answer: Aki Hamaji
> Finished chain.
Aki Hamaji正解です。
「Agent」の使い方について詳しくは、「Agents」を参照してください。
7. Memory
これまでの「Chain」や「Agent」はステートレスでしたが、「Memory」を使うことで、「Chain」や「Agent」で過去の会話のやり取りを記憶することができます。過去の会話の記憶を使って、会話することができます。

(1) ConversationChainの準備。
「ConversationChain」は会話用のチェーンで、メモリの機能を持ちます。
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate
# LanguageModelの準備
chat_model = ChatOpenAI(temperature=0.9)
# PromptTemplateの準備
template = """You are a nice chatbot having a conversation with a human.
Previous conversation:
{chat_history}
New human question: {question}
Response:"""
prompt = PromptTemplate.from_template(template)
# Memoryの準備
memory = ConversationBufferMemory(memory_key="chat_history")
# Chainの準備
conversation = LLMChain(
llm=chat_model,
prompt=prompt,
memory=memory,
verbose=True,
)「Memory」を「LCEL」で記述する方法が見つからなかったので、「Chain Interface」で記述しています。
(2) 会話の実行。
# 会話の実行
conversation({"question": "うちのネコの名前は白子です。"})> Entering new LLMChain chain...
Prompt after formatting:
You are a nice chatbot having a conversation with a human.
Previous conversation:
New human question: うちのネコの名前は白子です。
Response:
> Finished chain.
{'question': 'うちのネコの名前は白子です。',
'chat_history': '',
'text': ' あなたのネコの名前が白子なんですね!白子ってかわいい名前ですね!'}(3) 会話の実行。
過去の会話内容を覚えていることがわかります。
# 会話の実行
conversation({"question": "私のネコの名前を呼んでください。"})> Entering new LLMChain chain...
Prompt after formatting:
You are a nice chatbot having a conversation with a human.
Previous conversation:
Human: うちのネコの名前は白子です。
AI: あなたのネコの名前が白子なんですね!白子ってかわいい名前ですね!
New human question: 私のネコの名前を呼んでください。
Response:
> Finished chain.
{'question': '私のネコの名前を呼んでください。',
'chat_history': 'Human: うちのネコの名前は白子です。\nAI: あなたのネコの名前が白子なんですね!白子ってかわいい名前ですね!',
'text': ' わかりました!白子さん、お呼びですか?'}「Memory」の使い方について詳しくは、「Memory」を参照してください。
8. Retrieval
LLMアプリケーションの多くは、モデルの学習データにないアプリ固有のデータを必要とします。これを実現する主な方法の1つが、「検索拡張生成」(RAG:Retrieval Augmented Generation) です。外部から関連データを取得し、生成ステップの実行時にLLMに追加情報として渡す手法になります。
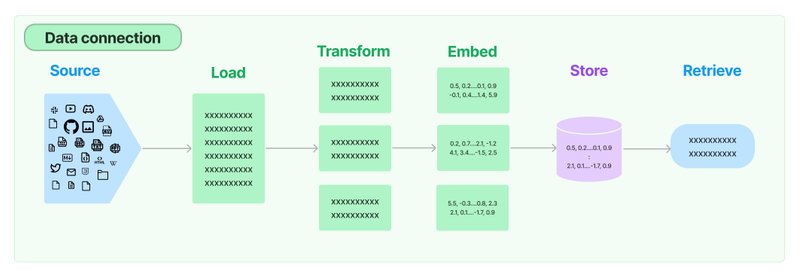
8-1. ドキュメントの準備
(1) ドキュメントの準備。
今回は、マンガペディアの「ぼっち・ざ・ろっく!」のドキュメントを用意しました。
・bocchi.txt

(2) Colabにdataフォルダを作成して配置。

8-2. RAG
(1) 追加のパッケージのインストール。
ドキュメントローダーなどを利用するためのパッケージになります。
!pip install chromadb tiktoken langchainhub unstructured(2) ドキュメントの読み込み。
from langchain.document_loaders import DirectoryLoader
# ドキュメントの読み込み
loader = DirectoryLoader('./data/')
documents = loader.load()
print(documents)(3) ドキュメントの分割。
「chunk_size=1000」でチャンクサイズ最大1000文字、「chunk_overlap=20」で前後のオーバーラップ最大20文字としています。
from langchain.text_splitter import CharacterTextSplitter
# ドキュメントの分割
text_splitter = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=20
)
splits = text_splitter.split_documents(documents)
# チャンクの確認
for i in range(len(splits)):
print(i, len(splits[i].page_content), splits[i].page_content)0 740 結束バンド
後藤ひとりは友達を作れない陰キャでいつも一人で過ごしていたが、...
1 571 文化祭ライブ
夏休みに入り、後藤ひとりは知り合いも増えていたが、....
2 606 デモ審査
未確認ライオットに参加するためには、....
:
14 398 ギターヒーロー
後藤ひとりが動画配信の際に用いるハンドルネーム。...(4) VectorStoreの準備。
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# VectorStoreの準備
vectorstore = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings()
)(5) Retrieverの準備。
search_kwargs={"k": 2} で、関連する上位2つのチャンクを取得するよう設定しています。
# Retrieverの準備。
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})(6) RagChainの準備。
「LangChain Hub」からPromptTemplate「rlm/rag-prompt」を取得し、「RAGChain」を作成しています。
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain import hub
# LanguageModelの準備
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0
)
# PromptTemplateの準備
rag_prompt = hub.pull("rlm/rag-prompt")
# RAGChainの準備
rag_chain = {
"context": retriever,
"question": RunnablePassthrough()
} | rag_prompt | llm(7) 質問応答。
# RagChainの実行
rag_chain.invoke("ぼっちちゃんの得意な楽器は?")AIMessage(content='ぼっちちゃんの得意な楽器はギターです。')(8) 質問応答。
# RagChainの実行
rag_chain.invoke("ライブハウス「STARRY」の店長は?")AIMessage(content='「STARRY」の店長は伊地知虹夏の姉であり、ライトイエロー色の髪をストレートロングに伸ばしている女性です。彼女はシビアな性格をしており、口が非常に悪いですが、根は優しく、妹を気づかっているようです。')「Retrieval」の使い方について詳しくは、「Retrieval」を参照してください。
9. Callback
「LangChain」は、ロギング、モニタリング、ストリーミングなどに役立つ「Callback」機能を提供します。各種APIで利用可能な「callbacs」引数に [Handler] のリストを渡すことで、様々なイベントを受信することができます。
今回は、LLMChainに組み込みHandler「StdOutCallbackHandler」を設定します。これは、すべてのイベントを単純に標準出力するHandlerで、「verbose=True」と同じ効果になります。
from langchain.callbacks import StdOutCallbackHandler
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# Handlerの準備
handler = StdOutCallbackHandler()
# LanguageModelの準備
llm = OpenAI()
# PromptTemplateの準備
prompt = PromptTemplate.from_template("1 + {number} = ")
# LLMChainの準備
chain = LLMChain(
llm=llm,
prompt=prompt,
callbacks=[handler] # Callbackの設定
)
# Chainの実行
chain.invoke({"number": 2})> Entering new LLMChain chain...
Prompt after formatting:
1 + 2 =
> Finished chain.
{'number': 2, 'text': '\n\n3'}未設定時は「{'number': 2, 'text': '\n\n3'}」のみ出力します。
関連
・LangChain
・LangChain.js
・LangChain Templates
・Chat LangChain
・LangChain Document
・LangChain Integrations
・LangChain Hub
・LangSmith
・LangChain Blog
この記事が気に入ったらサポートをしてみませんか?