LLMファインチューニングの LoRA と フルパラメータ の比較

以下の記事が面白かったので、かるくまとめました。
・Fine-Tuning LLMs: LoRA or Full-Parameter? An in-depth Analysis with Llama 2
1. LoRA と フルパラメータ の比較
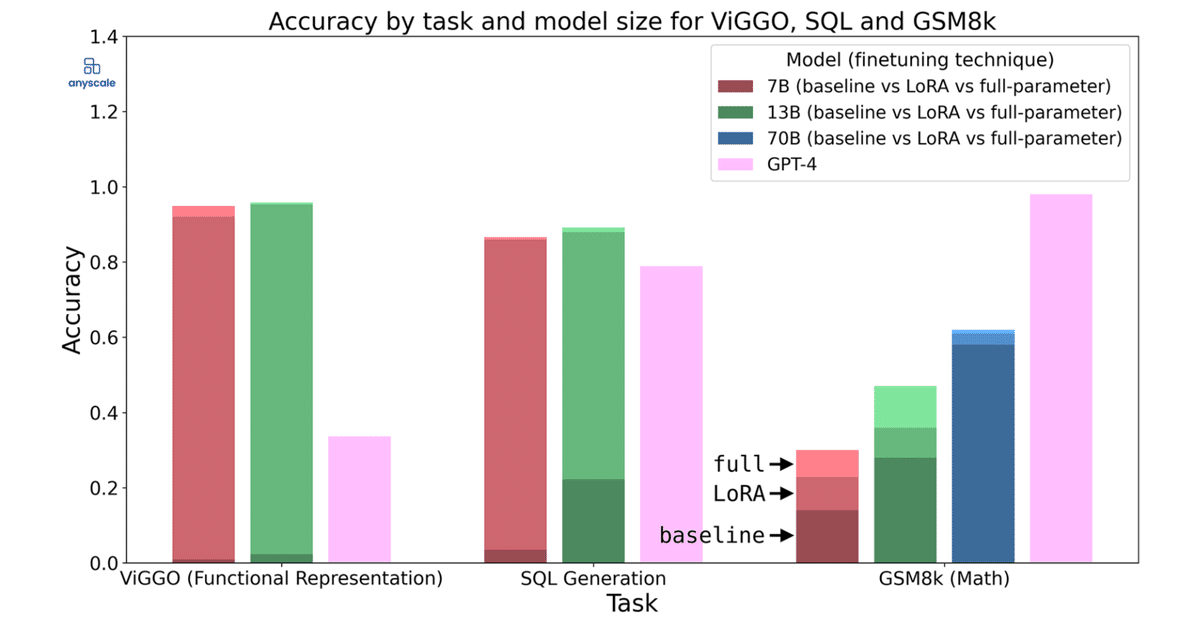
この記事では、「LoRA」と「フルパラメータ」のLLMファインチューニングを比較し、2つの手法の長所と短所を探ります。「GSM8k」「ViGGO」「SQL」の3つのデータセットで「Llama 2」を「LoRA」と「フルパラメータ」でファインチューニングして調査しました。
1-1. ViGGO
「ViGGO」は、文章から関数表現を抽出するタスクを学習するためのデータセットです。このタスクには、高レベルな論理や推論は必要ありません。ある表現から別の表現にマッピングするだけです。

評価は、次のとおりです。

「LoRA」は「フルパラメータ」よりわずかに劣りますが (95% 対 97%) 、実用上は大して問題ないかもしれません。
1-2. GSM8k
「GSM8k」は、小学校の算数問題に対しての推論能力を学習するためのデータセットです。他のデータセットとは異なり、正解に到達するには多くの方法があります。評価は、最終回答のみを考慮しています。

評価は、次のとおりです。

「LoRA」は「フルパラメータ」と比較して、明らかにパフォーマンスが劣っています。70Bの差は小さいですが、ベースラインからの改善も小さいです。他のタスクと比較すると「フルパラメータ」も、そこまでうまくは機能していません。
数千の例を使ったファインチューニングのみでは、数学的な推論能力を学習することは難しいことがわかります。
1-3. SQL-create-context
「SQL-create-context」は、自然言語をSQLクエリに変換するタスクを学習するためのデータセットです。

評価は、次のとおりです。

「ViGGO」タスクとの類似性から、このタスクがファインチューニングで解決できる有望な候補である理由がわかります。
2. 考慮すべき事項
「LoRA」および「フルパラメータ」のLLMファインチューニングを行う際に、考慮すべき事項があります。
2-1. タスクの種類が重要
「LoRA」は、ファインチューニングの際に理想的な重みの下位近似値として機能するため、ネットワークの「適応能力」が事実上制限されます。
「GSM8k」タスクでは、挑戦的な新しいスキルを学習する必要がありましたが、これは低ランクの近似ではうまく捉えられませんでした。それに対し、「ViGGO」や「SQL-create-context」などの、ある表現から別の表現にマッピングするタスクはうまく学習できました。
2-2. 学習率に対する LoRA の感度
「LoRA」が良い性能を発揮するタスクであっても、学習を安定させるために「学習率」を調整する必要がありました。「LoRA」ではパラメータの数が限られているため、最適化は「フルパラメータ」よりも難しくなります。
以下は「SQL-create-context」のグラフで、学習の安定性に対する学習率の影響と、検証セットに対する複雑さを示しています。
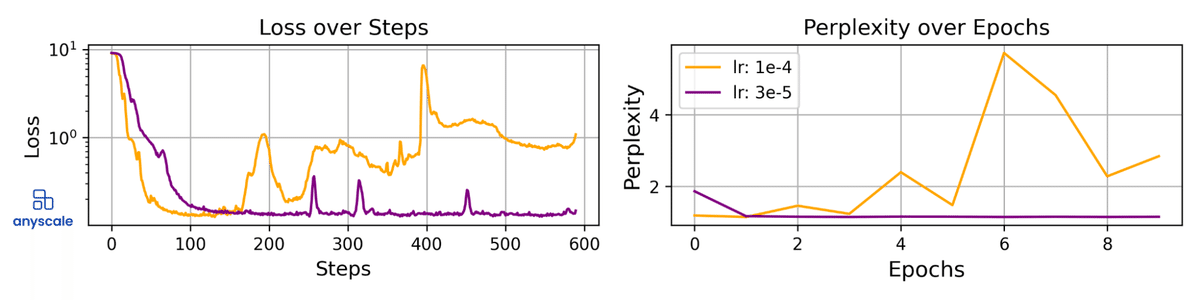
このタスクでは、学習を安定させるために学習率を 1e-4 から 3e-5 に下げました。Lossの不安定さは、LoRAモデルの能力を大幅に低下する可能性があります。適切な学習率を選択すると、収束はほぼ最適になります。
学習率が低いとお手本のような学習曲線が生成されますが、学習率が高いと不安定に見えます。学習コストを節約したいという誘惑に負けずに、不安定の可能性を認識することが大事になります。
2-3. プロンプトにタスク説明を追記
「LoRA」の主な利点の1つは、メモリとサービスの効率性 です。しかし、最適な構成を見つけるために複数のジョブを起動し、グリッド検索を実行する必要があるのであれば、あまり魅力的ではありません。
ここで、プロンプトにタスク説明を追記することで、この問題を軽減できます。タスク説明により、回答内のトークンの出現が質問に存在するトークンに基づいて条件付けされる可能性が高くなり、最適化問題がより簡単になり、より効果的にファインチューニングできるようになります。

以下は「ViGGO」のグラフで、タスク説明プロンプトの影響を示しています。

他のハイパーパラメータを固定すると、プロンプトによる学習の安定性が大幅に向上しました。ただし、プロンプト短縮というファインチューニングの目的の1つが損なわれる可能性があることに注意が必要です。
3. LoRAのハイパーパラメータ
実験に使われたLoRAのハイパーパラメータは、次のとおりです。
"r": 8,
"lora_alpha": 16,
"lora dropout": 0.05,
"target_modules": ["q_proj", "v_proj", "k_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "embed_tokens", "lm_head"],
"modules_to_save": [],◎ Rank: 8
分解行列に高い「Rank」を選択すると、「LoRA」のパフォーマンス向上が妨げられてしまいます。予備テストでは、16 に上げた場合のパフォーマンス向上は最小限であることが示唆されました。その結果、チェックポイントファイルのサイズの増大を避けるため、8 に落ち着きました。
◎ Alpha: 16
「Alpha」は学習した重みをスケーリングします。オリジナルの LoRA 論文を含む既存の文献では、Alphaを調整可能なハイパーパラメータとして扱うのではなく、Alphaを固定 (多くの場合 16) することが推奨されています。
◎ Target modules: All dense layers
オリジナルの LoRA 論文は、「Q」と「V」のアテンション行列のみをファインチューニングすることに焦点を当てており、この手法の有効性を証明する確かな結果を達成しました。しかしその後の研究により additional layers、さらには全てのレイヤー all layers をターゲットにすることでパフォーマンス向上することがわかりました。
LoRAをより多くのレイヤーに適用することで、フルパラメータのファインチューニングに近づくと仮説を立てています。したがって、すべてのレイヤーにわたって LoRA を実装することを選択しています。
◎ Base learning rate: 1e-4
「LoRA」で LLMファインチューニングする場合、1e-4 の学習率が標準になっています。学習損失の不安定性が時々発生しましたが、学習率を 3e-5 などの低い値に下げることがプロセスの安定化に効果的であることが判明しています。