
diffusers で ControlNet を試す

「diffusers」で「ControlNet」を試したので、まとめました。
1. ControlNet
「ControlNet」は、「Stable Diffusion」モデルにおいて、新たな条件を指定することで生成される画像をコントロールする機能です。プロンプトでは指示しきれないポーズや構図の指定が可能になります。
2. ControlNetの更新履歴
「diffusers」のControlNetの更新履歴は、次のとおりです。
2-1. diffusers v0.14.0
・Stable Diffusion 1.5用のControlNet
Stable Diffusion 1.5用に8つのControlNetのモデルを提供。
2-2. diffusers v0.15.0
・Multi-ControlNet
一度に複数のControlNetのモデルを使用可能に
2-3. diffusers v0.16.0
・ControlNet v1.1
Stable Diffusion 1.5用のControlNetのモデルのバージョンアップ
2-4. diffusers v0.17.0
・ControlNet Img2Img & Inpainting
Stable Diffusion 1.5用のImg2ImgとInpaintingでControlNetが利用可能に。
2-5. diffusers v0.20.0
・SDXL用のControlNet
SDXL用に2つのControlNetモデルを提供。
3. ControlNetのモデル
ControlNetのモデルは、次のとおりです。
3-1. Stable Diffusion 1.5用
・lllyasviel/control_v11p_sd15_canny : Canny Edge検出で学習
・lllyasviel/control_v11p_sd15_mlsd : マルチレベルの線分検出で学習
・lllyasviel/control_v11f1p_sd15_depth : 深度推定で学習
・lllyasviel/control_v11p_sd15_normalbae : 表面法線推定で学習
・lllyasviel/control_v11p_sd15_seg : 画像セグメンテーションで学習
・lllyasviel/control_v11p_sd15_lineart : 線画生成で学習
・lllyasviel/control_v11p_sd15_openpose : 人間の姿勢推定で学習
・lllyasviel/control_v11p_sd15_scribble : 落書きベースの画像生成で学習
・lllyasviel/control_v11p_sd15_softedge : ソフトエッジ画像生成で学習
・lllyasviel/control_v11e_sd15_ip2p : ピクセルからピクセルへの命令で学習
・lllyasviel/control_v11p_sd15_inpaint : 画像修復で学習
・lllyasviel/control_v11e_sd15_shuffle : 画像シャッフルで学習
・lllyasviel/control_v11p_sd15s2_lineart_anime : アニメ線画生成で学習
3-2. SDXL用
・diffusers/controlnet-canny-sdxl-1.0 : Canny Edge検出で学習
・diffusers/controlnet-depth-sdxl-1.0 : 深度推定で学習
4. ControlNetのパイプライン
ControlNetのパイプラインは、次のとおりです。
4-1. Stable Diffusion 1.5用
・StableDiffusionControlNetPipeline : 画像生成
・StableDiffusionControlNetImg2ImgPipeline : Img2Img
・StableDiffusionControlNetInpaintPipeline : Inpainting
4-2. SDXL用
・StableDiffusionXLControlNetPipeline : 画像生成
5. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install diffusers accelerate controlnet_aux omegaconf(2) 左端のフォルダアイコンでファイル一覧を表示し、初期画像をアップロード。
・init_image.png (512x512)

(3) 初期画像の読み込み。
from diffusers.utils import load_image
# 初期画像の準備
init_image = load_image("init_image.png")
init_image = init_image.resize((512, 512))
# 確認
init_image(4) コントロール画像の準備。
今回は、OpenPoseのコントロール画像を準備します。
「controlnet_aux」で初期画像をコントロール画像に変換します。
from controlnet_aux import OpenposeDetector
# コントロール画像の準備
openpose_detector = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
openpose_image = openpose_detector(init_image)
# 確認
openpose_image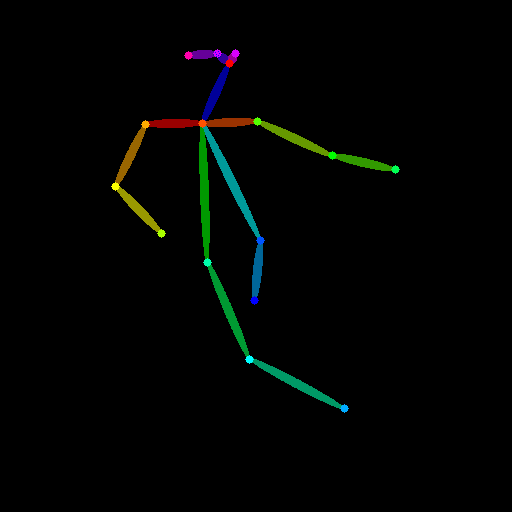
(5) ControlNetモデルの準備。
今回は、OpenPoseのControlNetモデルを準備します
import torch
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, DDIMScheduler
# ControlNetモデルの準備
controlnet_pose = ControlNetModel.from_pretrained(
"lllyasviel/control_v11p_sd15_openpose",
torch_dtype=torch.float16
).to("cuda")(6) モデルのダウンロード。
今回は、「Counterfeit-V3.0」を使います。
# モデルのダウンロード
!wget https://huggingface.co/gsdf/Counterfeit-V3.0/resolve/main/Counterfeit-V3.0_fix_fp16.safetensors(7) パイプラインの準備。
ControlNet用に「StableDiffusionControlNetPipeline」を使用して、controlnetにControlNetモデルを指定します。
# パイプラインの準備
pipe = StableDiffusionControlNetPipeline.from_single_file(
"Counterfeit-V3.0_fix_fp16.safetensors",
controlnet=[controlnet_pose],
torch_dtype=torch.float16
).to("cuda")
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()(8) 画像生成。
imageにコントロール画像を指定します。
# 画像生成
image = pipe(
"cute cat ear maid dancing",
negative_prompt="(worst quality:1.4), (low quality:1.4), (monochrome:1.3)",
num_inference_steps=20,
generator=torch.Generator(device="cpu").manual_seed(123),
eta=1.0,
image=[openpose_image],
).images[0]
# 確認
image
関連
次回
\