Google Colab で EZO-InternVL2-26B を試す

「Google Colab」で「EZO-InternVL2-26B」を試したのでまとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. EZO-InternVL2-26B
「EZO-InternVL2-26B」は、「InternVL2-26B」をベースに、複数のチューニング手法で画像認識と日本語性能を向上させたモデルです。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install -U transformers==4.37.2 sentencepiece decord
!pip install bitsandbytes accelerate
!pip install timm flash_attn(2) モデルとトークナイザーの準備。
メモリが足りないので BNB 8-bit Quantization で読み込みます。
import torch
from transformers import AutoTokenizer, AutoModel
# モデルとトークナイザーの準備
model = AutoModel.from_pretrained(
'HODACHI/EZO-InternVL2-26B',
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
trust_remote_code=True
).eval()
tokenizer = AutoTokenizer.from_pretrained(
'HODACHI/EZO-InternVL2-26B',
trust_remote_code=True,
use_fast=False
)(3) 画像読み込み関数の準備。
モデルカードのサンプルコードをコピペしました。
・load_image(image_file, input_size=448, max_num=12)
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
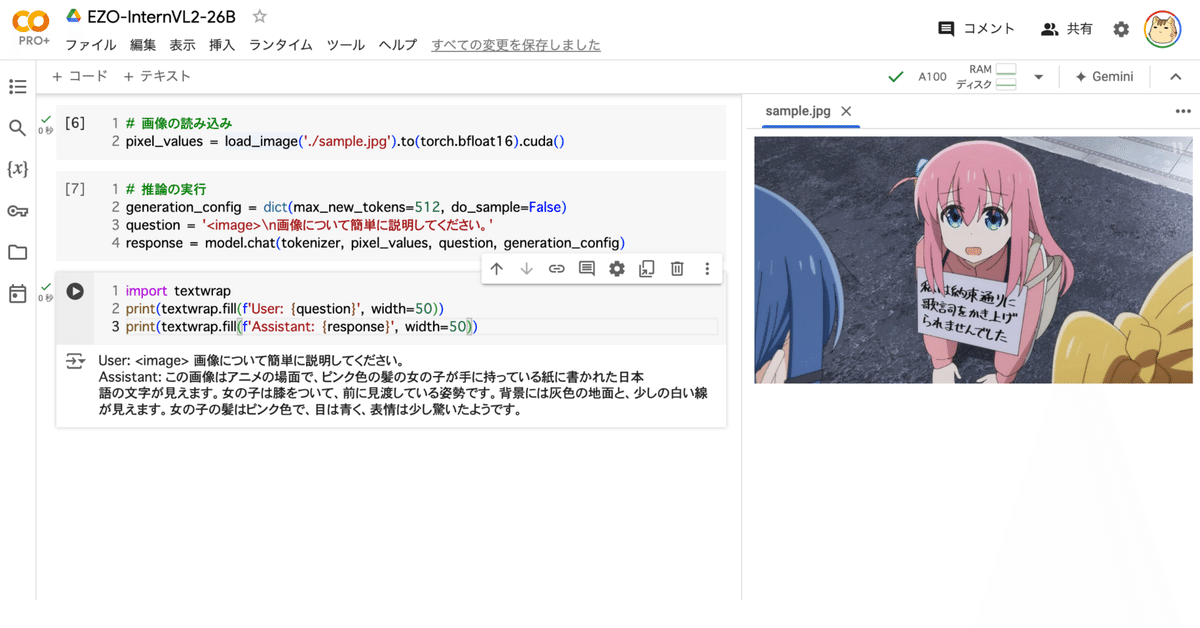
return pixel_values(4) Colabの左側のフォルダアイコンから画像 (sample.jpg) をアップロード。
(5) 画像の読み込み。
# 画像の読み込み
pixel_values = load_image('./sample.jpg').to(torch.bfloat16).cuda()(6) 推論の実行。
# プロンプトの準備
question = '<image>\n画像について簡単に説明してください。'
# 推論の実行
generation_config = dict(max_new_tokens=512, do_sample=False)
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')User: <image> 画像について簡単に説明してください。
Assistant: この画像はアニメの場面で、ピンク色の髪の女の子が手に持っている紙に書かれた日本 語の文字が見えます。女の子は膝をついて、前に見渡している姿勢です。背景には灰色の地面と、少しの白い線 が見えます。女の子の髪はピンク色で、目は青く、表情は少し驚いたようです。

メモリ消費量は次のとおりです。

この記事が気に入ったらサポートをしてみませんか?