
GPT-4o の概要

以下の記事が面白かったので、簡単にまとめました。
1. GPT-4o
「GPT-4o」 (「omni」の「o」) は、人間とコンピュータのより自然な対話に向けた一歩です。テキスト、音声、画像のあらゆる組み合わせを入力として受け入れ、テキスト、音声、画像の出力のあらゆる組み合わせを生成します。 音声入力にはわずか232ミリ秒 (平均320ミリ秒) で応答できます。これは、人間の会話における応答時間とほぼ同じです。英語のテキストおよびコードでは「GPT-4 Turbo」のパフォーマンスに匹敵し、英語以外の言語のテキストでは大幅に改善されており、APIでははるかに高速で50%安価です。「GPT-4o」は、既存のモデルと比較して、特に視覚と音声の理解に優れています。
2. モデルの機能
「GPT-4o」以前は、音声モードを使用して、平均2.8秒 (GPT-3.5) および5.4秒 (GPT-4) の遅延で「ChatGPT」と会話できました。 これを実現するために、3つの個別のモデルのパイプラインを使用していました。1つ目で音声をテキストに変換し、2つ目で「GPT-3.5」または「GPT-4」がテキストを取り込んでテキストを出力し、3番目でそのテキストを音声に変換します。このプロセスは、主な知能源である「GPT-4」が多くの情報を失うことを意味します。「GPT-4」は、声調、複数の話者、背景雑音を直接観察できず、笑い声、歌唱、感情表現を出力できません。
「GPT-4o」では、テキスト、ビジョン、オーディオにわたって単一の新しいモデルをエンドツーエンドで学習しました。これは、すべての入力と出力が同じニューラルネットワークによって処理されることを意味します。「GPT-4o」はこれらすべてのモダリティを組み合わせた最初のモデルであるため、このモデルで何ができるか、そしてその制限についてはまだ表面をなぞっただけです。
3. モデルの評価
従来のベンチマークで測定したように、「GPT-4o」はテキスト、推論、コーディングに関して「GPT-4 Turbo」レベルの性能を達成すると同時に、多言語、オーディオ、ビジョン機能に関して最高水準を達成しました。
3-1. テキスト評価

3-2. オーディオASR性能

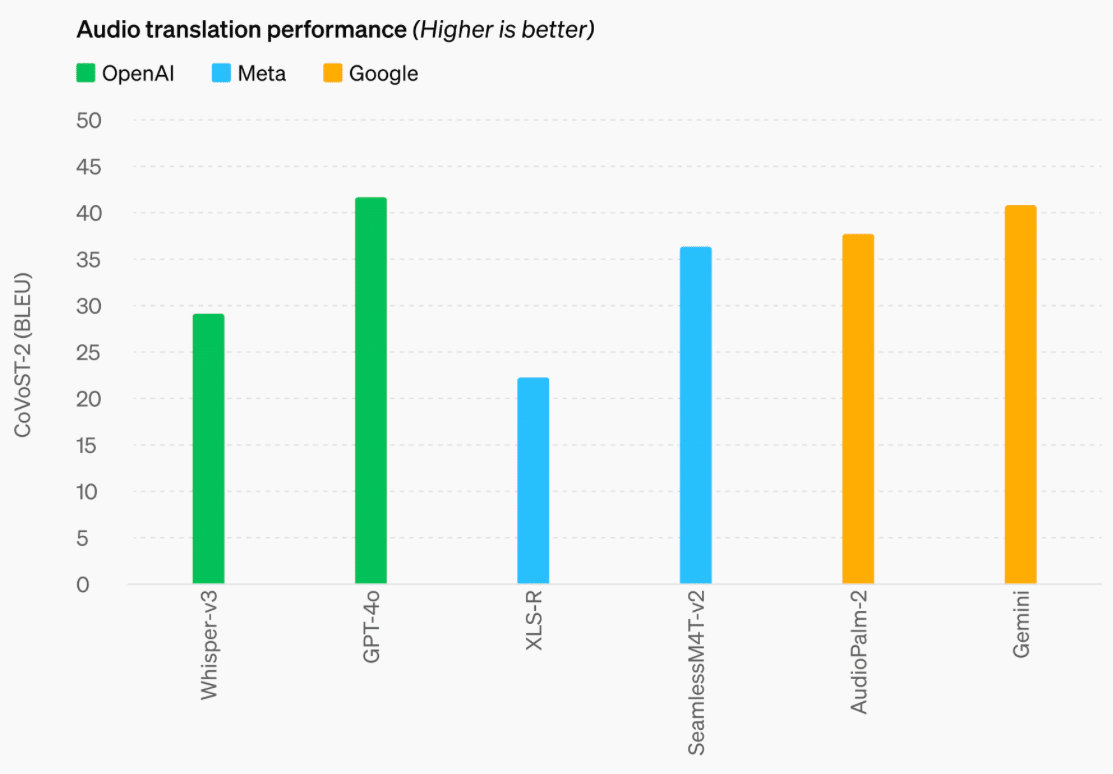
3-3. オーディオ翻訳性能
3-4. M3Exam Zero-Shot結果

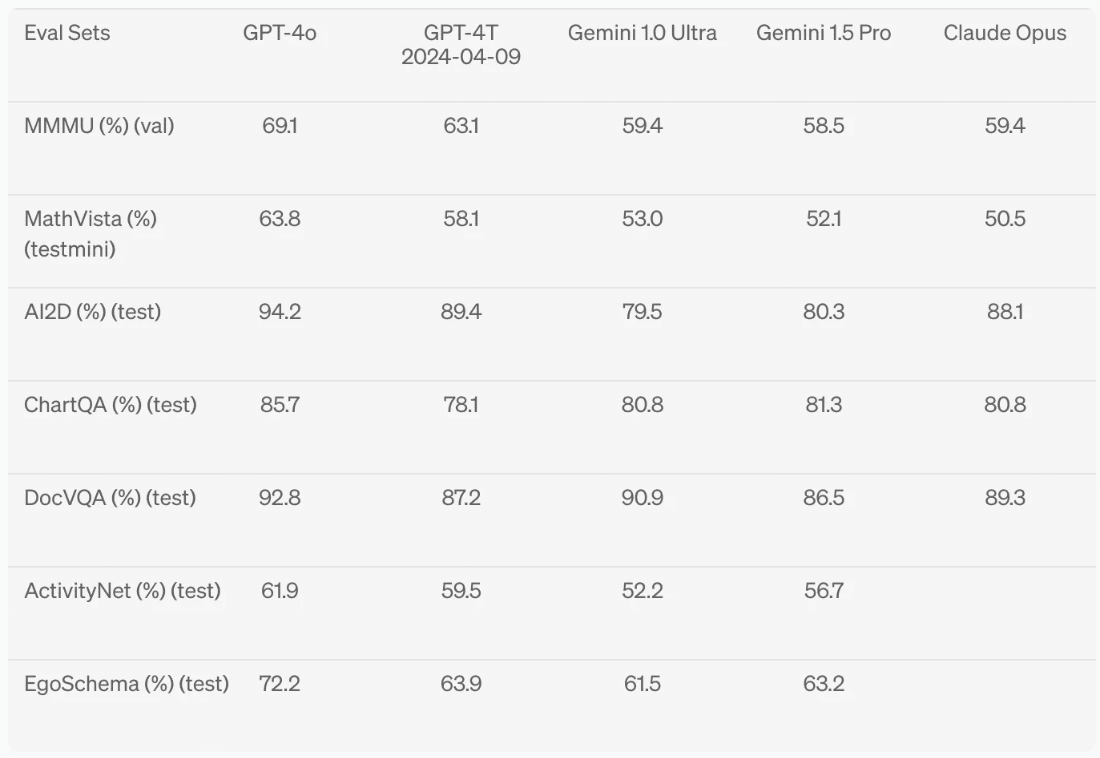
3-5. ビジョン理解評価
3-6. 言語のトークン化
以下の20 言語は、新しいトークナイザーの圧縮を代表するものとして選択されました。
・Japanese 1.4x (from 37 to 26)
・English 1.1x (from 27 to 24)
・Gujarati 4.4x (from 145 to 33)
・Telugu 3.5x (from 159 to 45)
・Tamil 3.3x (from 116 to 35)
・Marathi 2.9x (from 96 to 33)
・Hindi 2.9x (from 90 to 31)
・Urdu 2.5x (from 82 to 33)
・Arabic 2.0x (from 53 to 26)
・Persian 1.9x (from 61 to 32)
・Russian 1.7x (from 39 to 23)
・Korean 1.7x (from 45 to 27)
・Vietnamese 1.5x (from 46 to 30)
・Chinese 1.4x (from 34 to 24)
・Turkish 1.3x (from 39 to 30)
・Italian 1.2x (from 34 to 28)
・German 1.2x (from 34 to 29)
・Spanish 1.1x (from 29 to 26)
・Portuguese 1.1x (from 30 to 27)
・French 1.1x (from 31 to 28)
4. モデルの安全性と制限事項
「GPT-4o」には、学習データのフィルタリングや学習後のモデルの動作の調整などの技術を通じて、モダリティ全体に安全性が組み込まれています。また、音声出力にガードレールを提供する新しい安全システムも作成しました。
準備フレームワークに従って、また自主的な取り組みに沿って「GPT-4o」を評価しました。サイバーセキュリティ、CBRN、説得、モデルの自律性に関する評価では、「GPT-4o」はこれらのカテゴリのいずれにおいても中リスク以上のスコアを獲得していないことが示されています。この評価には、モデルの学習プロセス全体を通じて一連の自動評価と人間による評価の実行が含まれます。モデルの機能をより適切に引き出すために、カスタムファインチューニングとプロンプトを使用して、モデルの安全性緩和前バージョンと安全性緩和後のバージョンの両方をテストしました。
「GPT-4o」はまた、社会心理学、偏見と公平性、誤った情報などの分野で70人以上の外部専門家と広範な外部レッドチームを結成し、新たに追加された手法によって導入または増幅されるリスクを特定しました。これらの学習を利用して、「GPT-4o」とのやり取りの安全性を向上させるための安全介入を構築しました。新たなリスクが発見され次第、引き続き軽減していきます。
「GPT-4o」のオーディオモダリティにはさまざまな新たなリスクがあることを認識しています。本日、テキストと画像の入力とテキスト出力を一般公開します。今後数週間から数か月かけて、技術インフラストラクチャ、学習後の使いやすさ、他のモダリティをリリースするために必要な安全性に取り組んでいきます。たとえば、発売時にはオーディオ出力はプリセット音声の選択に制限され、既存の安全ポリシーに準拠します。今後のシステムカードで「GPT-4o」のモダリティの全範囲に対応するさらなる詳細を共有する予定です。
5. モデルの入手可能性
「GPT-4o」のテキストおよび画像機能は、「ChatGPT」で本日から展開され始めます。
「GPT-4o」を使用する場合、無料ユーザーも次の機能にアクセスできます。
・GPT-4レベルの知能を体験
・モデルとウェブの両方から応答を取得
・データを分析し、チャートを作成
・写真についてチャット
・要約、書き込み、または分析を支援するためのファイルのアップロード
・GPTとGPTストアの使用
・メモリの使用
有料ユーザーは、メッセージ制限が最大5倍になります。今後数週間以内に、「ChatGPT Plus」内でα版の「GPT-4o」を使用した音声モードの新バージョンを公開する予定です。
また開発者は、APIで「GPT-4o」のテキストおよびビジョンにアクセスできるようになりました。「GPT-4o」は「GPT-4 Turbo」と比較して2倍高速で、価格は半分で、レート制限が5倍高くなります。今後数週間以内に、APIの信頼できるパートナーの小グループに対して「GPT-4o」の新しいオーディオおよびビデオ機能のサポートを開始する予定です。