
World Model : 夢の中で学ぶ強化学習アルゴリズム

1. 強化学習の問題
「強化学習」は、「エージェント」が「環境」の「状態」に応じてどのように「行動」すれば「報酬」を多くもらえるかを求める手法です。「強化学習」は「深層学習」と組み合わさったことで、近年大きく発展しています。しかし、「強化学習」には大きな問題が2つあります。
(1)非常に多くの学習データを必要とする。
(2)環境やタスクが変わった場合うまく対応できない。
(1)の問題は、現在の強化学習が「モデルフリー」なため、環境のモデルを仮定せず、試行錯誤しながら方策を最適化していることに起因します。これを解決するには、タスクをモデル化する必要がありますが、世の中の多くの環境はモデル化することが困難です。
(2)の問題は、観察をそのまま学習データとして扱っていることに起因します。これを解決するには、観察をそのまま扱わずに、タスクと関係のない特有の情報を捨て、抽象化された情報の上で学習しなければなりません。
これらの問題を解決するためには、環境の抽象的なモデルを構築し、そのモデル上で学習を行うことが必要になります。
これを実現する手法の1つが、David HaとJürgenSchmidhuberが提案した「World Model」になります。
2. World Model
人間は、あらゆるものを知覚できるわけではありません。脳に入ってくる情報は限られています。そこで脳の内部では、知覚した情報から外の世界をモデル化した「World Model」を構築します。
「World Model」は外の世界をシミュレートするモデルです。より正確に言うと、現在の運動や行動を使って、将来の刺激を予想しています。これは、学習した脳の「World Model」によって、未来を予測しているということになります。
「強化学習」は、状態と行動、そして環境からの報酬によって、エージェントの最適な方策を求めます。この時エージェントは、「過去や現在の状態の良い表現」や「未来の予測モデル」があれば、モデルベースな学習が可能になると考えられます。
つまり、エージェントは、世界をモデル化する大規模なモデル「World Model」と、タスクを実行するための小規模なモデル「コントローラ」を分けて学習すれば良いのではないかと考えられます。
3. 提案モデル
これまでの考察から、以下のようなシンプルなモデルが提案されました。
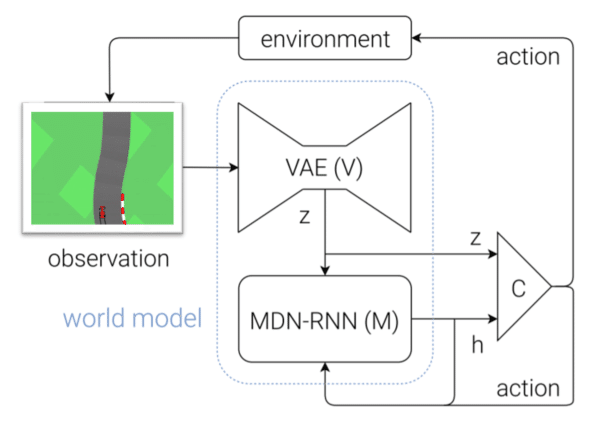
このモデルは次の3つの要素から成り立ちます。
・Vision Model(V) : 高次元の観測データを低次元のコードに圧縮
・Memory RNN(M) : 過去のコードから未来の状態を予測
・Controller(C) : VとMから良い行動を選択
「Vision Model(V)」と「Memory RNN(M) 」が「World Model」、「Controller(C)」 が「コントローラ」にあたります。これらは個別に訓練されます。
CarRace環境に関するケーススタディを使用して、モデルは次のことを行います。
(1)「観察」は、環境から2D画像(64x64x3)形式で取り出されます。
(2)「観測」は、「VAE」(Convolutional Variational Autoencoder)である「Vision Model(V)」に供給され、サイズ32の潜在ベクトル「z」にエンコードされます。
(3)次のモジュールは「Memory RNN(M)」です。混合密度ネットワークを備えたRNNは、「Vision Model(V)」から潜在ベクトル「z」、「Controller(C)」によって選択された以前の行動「a」、および自身の以前の非表示状態「h」を取得します。「Vision Module(V)」と同様に、次の「z」がどのようになるかを予測することにより、環境の潜在的な理解/観察をキャプチャすることが目的です。 256の長さのRNNの非表示状態「h」を転送します。
(4)最後に「Controller(C)」です。「Vision Module(V)」の観測「z」と「Memory Module(M)」の非表示状態「h」を各タイムステップでの行動にマッピングする単純な単層線形モデルです。出力は、ステアリング方向(-1から1)、加速度(0から1)およびブレーキング(0から1)の定量的表現を含むサイズ3の行動ベクトルになります(例: [0.44, 0.6, 0])。
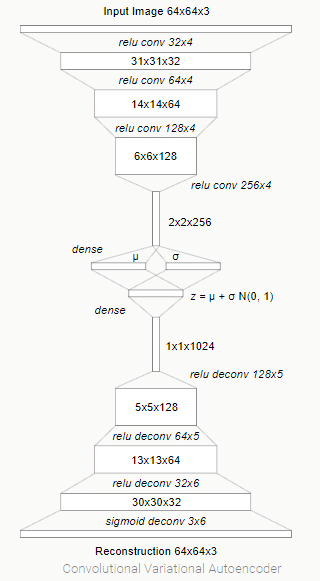
4. Vision Model(V)
このモジュール用に「VAE」(Convolutional Variational Autoencoder)が訓練されます。「VAE」は、半教師あり学習で訓練された強力な生成モデルです。私たちにとって重要なのは潜在ベクトル「z」です。これは、平均μと対角分散σをもつ因数分解されたガウス分布Nからサンプリングされます。環境(画像)からの各観測に対して、潜在ベクトル「z」が次のモデルに提供されます。
エージェントは入力画像の埋め込み表現のみを見ることができるため、エンコードにより訓練プロセスが向上します。
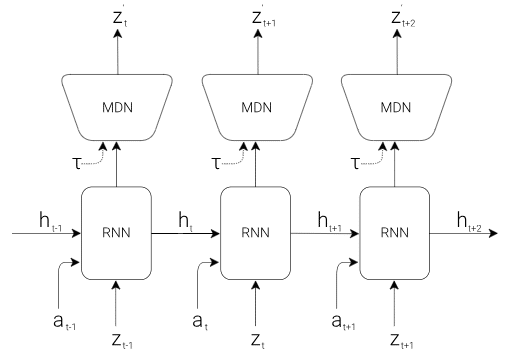
5. Memory RNN(M)
Mモデルは、基本的に256の非表示状態と混合密度ネットワーク(MDN)を持つ「LSTM」(Long Short-Term Memory)です。次の「z」値がどうなるかを予測しようとします。これは、ランダム性を導入することを目的とするMDNモジュールに供給されます。基本的に、MDNは「決定性のz値」であるLSTMの出力を「zの可能性の範囲」に変更します。
6. Controller(C)
最良の決定を行うように訓練された単純な線形モデルは次のとおりです。
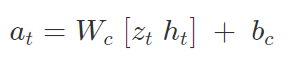
Cモデルの最適パラメータ(W[c]およびb[c])を見つけるために、「CMA-ES」(Covariance Matrix Adaption Evolution Strategy)が使用されます。これは、64CPUのポピュレーションサイズを使用して実行され、各エージェントは異なる初期ランダムシードでタスクを16回実行しました。これにより、コントローラの複数のバリアントがCPU全体で評価され、実際の環境で実行される最適なパラメータが選択されました。
この設定は、100回の試行で少なくとも平均900ポイントを目標とするカーレース環境でうまく機能しました。
7. 夢の中での訓練
World Modelから未来の状態をサンプリングできます。そのため、夢だけで学習できるかどうか、夢で学習した後に実際の環境で動作するか試します。
この実験はDOOM環境で行いました。さまざまな画像入力サイズとエージェントが死ぬことができるという事実を考慮して、その環境に合わせて調整された何らかの設定があります。
基本的な貢献(実際にエージェントが「夢」で学ぶストーリーで誇張された)は、Mモデルによって生成された予測「z」潜在表現を使用してエージェントを訓練し、DOOMのプレイ中により良いスコアを得たというデモにあります。Mモデルはエージェントの指示で火の玉を放つモンスターを生成することを学習し、Cモデルはこれらの生成された火の玉を回避する方策を発見します。 Vモデルは、Mモデルによって生成された潜在ベクトル「z」を一連のピクセルイメージにデコードするためにのみ使用されます。
8. 実行
Linuxホストマシンで実行されるdockerイメージを実験のためにまとめてくれたFábiánFülekiに感謝します。GitHubリポジトリは以下にあります。
・SemesterProject/docker_setup at master · ffabi/SemesterProject · GitHub
CUDA対応GPUを搭載したシステムを実行していることと、Docker、nvidia-docker、CUDA 9.0がインストールされていることを確認してください。
(1)dockerのセットアップ
(1-a)dockerhubからイメージをプル
docker pull ffabi/gym:90(1-b)ローカルに構築
git clone https://github.com/ffabi/SemesterProject.git
cd SemesterProject/docker_setup
docker build -f Dockerfile_cuda90 -t ffabi/gym:90 .(2)dockerコンテナの実行
mkdir ./ffabi_shared_folder
nvidia-docker create -p 8192:8192 -p 8193:22 -p 8194:8194 --name / ffabi_gym -v $(pwd)/ffabi_shared_folder:/root/ffabi_shared_folder / ffabi/gym:90
nvidia-docker start ffabi_gym
docker exec -it ffabi_gym bash(3)World Modelのコンセプト実装をクローン
cd ffabi_shared_folder
git clone https://github.com/ffabi/SemesterProject.git
cd SemesterProject/WorldModels(4)アプリケーションの実行
mkdir data
xvfb-run -a -s "-screen 0 1400x900x24" python3 01_generate_data.py car_racing --total_episodes 200 --start_batch 0 --time_steps 300
xvfb-run -a -s "-screen 0 1400x900x24" python3 02_train_vae.py --start_batch 0 --max_batch 9 --new_model
xvfb-run -a -s "-screen 0 1400x900x24" python3 03_generate_rnn_data.py --start_batch 0 --max_batch 9
xvfb-run -a -s "-screen 0 1400x900x24" python3 04_train_rnn.py --start_batch 0 --max_batch 0 --new_model
xvfb-run -a -s "-screen 0 1400x900x24" python3 05_train_controller.py car_racing --num_worker 1 --num_worker_trial 2 --num_episode 4 --max_length 1000 --eval_steps 259. 結論
David HaとJürgenSchmidhuberによる「World Model」は間違いなく有用なモデルであり、環境を学習し、エージェントが環境でうまく機能するように教えることができます。この研究は、行動の決定を下すために脳がどのように情報を処理するかについての良い説明を提供し、モデルベースにおける将来の研究のための優れたフレームワークとして役立つでしょう。
10. 参考
・World Models
・World models — a reinforcement learning story
・世界モデル:world model、想像の中で学習できるか
・[DL輪読会]World Models
この記事が気に入ったらサポートをしてみませんか?