
OpenAIのAPIを使って、PDFファイルの内容を瞬時に把握する方法

この記事では、ChatGPTでお馴染みのOpenAIのAPIを使って、PDFファイルに書かれている内容を把握する方法をご紹介します。
この方法を使えば、大量の文章が書かれているPDFファイルの中から、自分が知りたいことだけを瞬時に把握することができます。
OpenAIのAPIキーは取得したけど、どう活用したらいいか分からないという方も、ぜひご一度くださいね。
GoogleColaboratoryを使って実装していきます
1. 必要なもの
OpenAIのAPIキーが必要なります。あらかじめ取得しておいてください。
OpenAIのAPIキーの取得方法はこちらのサイトをご覧ください。
大量の文書を読み込むには、GPT-4が使えるAPIキーが良いです。
GPT-4のAPIキーを取得するには以下の追加登録(1ヶ月程度待ちます)が必要です。
2. Let's Try! それではやっていきましょう
●使用するPDFファイルについて
今回、使用するPDFファイルはこちらを使います。
https://www.fsa.go.jp/news/r4/ginkou/20230427/02.pdf
金融庁が今年4月に公表したオペレーショナル・レジリエンスにかかるディスカッション・ペーパーになります。
全文35ページのPDFファイルです。
★ライブラリーのインストール&インポート
pipで必要なライブラリーをインストールしていきます
!pip install openai chromadb langchain tiktoken必要なライブラリーのインポート
import os
import platform
import openai
import chromadb
import langchain
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.document_loaders import PyPDFLoader★PDFファイルの読み込み
PyPDFLoaderを使って、PDFファイルを読み込みます。
PyPDFLoaderの引数に、先ほどのURLを指定します。
loader = PyPDFLoader("https://www.fsa.go.jp/news/r4/ginkou/20230427/02.pdf")これで、loaderの中にPDFファイルが読み込まれました。
続けて、PDFファイルをページごとに分割し、1ページ目を表示させてみましょう。
#ページを分割する
pages = loader.load_and_split()
#pdfファイルを確認する
pages[1].page_content目 次
I. はじめに ................................ ................................ ................................ .. 1
なぜ今オペレーショナル・レジリエンスか ................................ .... 1
本文書の位置づけに関する留意事項 ................................ .............. 4
II. オペレーショナル・レジリエンスを巡る議論・背景 .............................. 5
国際的な議論の動向 ................................ ................................ ....... 5
バーゼル銀行監督委員会の国際原則 ................................ ..... 5
主要海外当局の動向 ................................ .............................. 6
国内外の環境変化 ................................ ................................ ........... 8
III. 金融機関に期待される役割 ................................ ................................ .... 10
「重要な業務」の特定 ................................ ................................ .. 13
「耐性度」の設定 ................................ ................................ ......... 16
相互連関性のマッピング・必要な経営資源の確保 ....................... 18
適切性の検証・追加対応 ................................ .............................. 27
IV. 今後の対話の進め方 ................................ ................................ .............. 31
こんな感じで、1ページ目にある目次が取得できました
★OpenAIの自然言語モデル(LLM)の呼び出し
OpenAIのAPIキーを使って、LLMを呼び出します。
モデルの指定もできて、ここではGPT-4を指定しています。
#APIキーを環境変数に入力
os.environ["OPENAI_API_KEY"] = 'ここにAPIキーを入力'
openai.api_key = os.getenv("OPENAI_API_KEY")
#モデルを指定
llm = ChatOpenAI(temperature=0, model_name="gpt-4")テキスト情報をベクトルに変換します
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(pages,
embedding=embeddings, persist_directory=".")
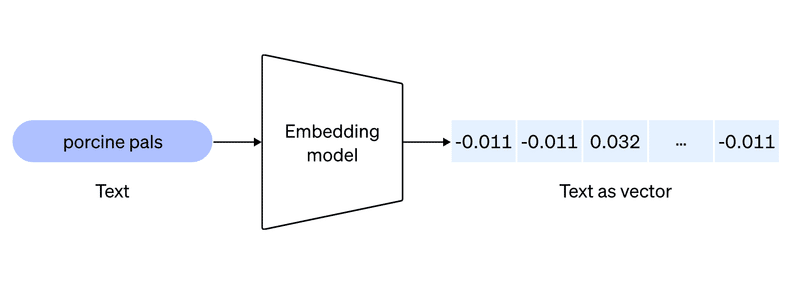
vectorstore.persist()テキスト情報をコンピュータが処理できるように、ベクトル(数値)に変換します。
イメージは以下の通りです。
Textが、Embeddingmodelを通じて、 ベクトルに変換されます。
★PDFファイルの内容を把握しましょう
まず、Chat形式で質問に対し答えてくれるインスタンスを生成します
crc = ConversationalRetrievalChain.from_llm(
llm,
vectorstore.as_retriever(),
return_source_documents=True)
queryに質問を入力します。
オペレーショナルレジリエンスとは何でしょうか?と聞いてみます。
query = "オペレーショナルレジリエンスとは何でしょうか?"
chat_history = []
result = crc({"question": query, "chat_history": chat_history})
result["answer"]回答
オペレーショナル・レジリエンスとは、業務の強靭性(レジリエンス)と復旧力を指します。これは、システム障害、テロやサイバー攻撃、感染症、自然災害などの事象が発生しても、金融機関が重要な業務を最低限維持すべき水準(耐性度)において、提供し続ける能力を意味します。金融機関がオペレーショナル・レジリエンスを確保するためには、重要な業務を特定し、業務中断後(危機時)の金融システムや利用者への影響を耐性度(最終防衛ライン)内に収めるよう、平時から社内外の業務プロセスの相互連関性をマッピングし、必要な経営資源(ヒト・モノ・カネ)を確保し、訓練・テスト等を通じて適切性を検証し、定期的に見直し続けることが求められます。
わかりやすく答えを返してくれましたね。
続いて、やや難し目の質問をしてみます。
オペレーショナル・レジリエンスを確保することのメリットは何でしょうか?と聞いてみます。
query = "オペレーショナル・レジリエンスを確保することのメリットは何でしょうか?"
chat_history = []
result = crc({"question": query, "chat_history": chat_history})
result["answer"]回答
オペレーショナル・レジリエンスを確保することのメリットは以下の通りです。
事業継続性の向上: システム障害、テロやサイバー攻撃、感染症、自然災害などの事象が発生しても、金融機関が重要な業務を最低限維持し、提供し続ける能力が向上します。
リスク管理の強化: 既存のリスク管理やBCPだけでは対応できない想定外の事象にも対応できるようになり、リスク環境の複雑化に対応できる体制が整います。
顧客信頼の維持・向上: 金融システムや利用者への影響を最小限に抑えることができるため、顧客からの信頼を維持・向上させることができます。
経営資源の効率的な活用: 重要な業務を特定し、経営資源(ヒト・モノ・カネ)を効率的に活用することで、業務プロセス全体の態勢整備が進みます。
国際的な基準への適合: オペレーショナル・レジリエンスは国際的にも重要視されており、国際的な基準に適合することで、金融機関の競争力が向上します。
組織全体の協力体制の構築: オペレーショナル・レジリエンスに対する組織横断的な理解の浸透や、経営陣のトップダウンによるコミットメントが不可欠であるため、組織全体の協力体制が構築されます。
箇条書きに整理して、返してくれました。さすがGPT-4ですね。
さいごに、更に難しい質問を投げてみましょう。
オペレーショナル・レジリエンスと従来型のBCPはどのような点が異なるのでしょうか?と聞いてみます。
そして、モデルがGPT-3.5とGPT-4でどう変わるかみてみます。
query = "オペレーショナル・レジリエンスと従来型のBCPはどのような点が異なるのでしょうか?"
chat_history = []
result = crc({"question": query, "chat_history": chat_history})
result["answer"]回答〜GPT-3.5の場合
従来型のBCPは、特定のリスク事象を想定して対応計画を策定することに主眼が置かれています。一方、オペレーショナル・レジリエンスは、想定外の事象が発生した場合にも、金融機関が重要な業務を最低限維持すべき水準において提供し続ける能力を確保することを目的としています。また、オペレーショナル・レジリエンスは、業務プロセス全体の包括的な態勢整備によって確保されるため、外部委託業務や連携サービスを含めた業務プロセスの相互連関性をマッピングし、必要な経営資源を確保し、訓練・テスト等を通じて適切性を検証し、定期的に見直し続けることが求められます。
回答〜GPT-4の場合
オペレーショナル・レジリエンスと従来型のBCP(事業継続計画)は、いくつかの点で異なります。
対象範囲:オペレーショナル・レジリエンスは、金融機関が重要な業務を最低限維持すべき水準で提供し続ける能力を確保することを目的としており、システム障害、テロやサイバー攻撃、感染症、自然災害などの幅広い事象に対応します。一方、従来型のBCPは、特定のリスク事象(例えば地震)を想定した対応計画に焦点を当てています。
柔軟性:オペレーショナル・レジリエンスは、想定外の事象が発生した場合でも、代替手段や早期復旧を通じて影響範囲を軽減する枠組みを確保することが重要です。従来型のBCPは、事前に想定されたリスク事象に対する対応策を立てることが主な目的であり、想定外の事象に対する柔軟性には限りがあります。
組織横断的な取り組み:オペレーショナル・レジリエンスを実効性のある形で確保するためには、組織全体での理解と経営陣のトップダウンによるコミットメントが不可欠です。従来型のBCPは、主にリスク管理部門や事業部門が主導する計画策定が中心でした。
比例原則に基づく対応:オペレーショナル・レジリエンスは、金融機関の規模、リスク選好度、金融システムへの影響に応じた比例原則に基づく対応が求められます。従来型のBCPでは、一定の基準や手順に従って対応策を立てることが一般的でした。
これらの違いから、オペレーショナル・レジリエンスは、従来型のBCPよりも包括的で柔軟なアプローチを提供し、金融機関が様々なリスク環境に対応できるように支援します。
3. 注意事項
OpenAIのAPI利用は、無料ではありません。
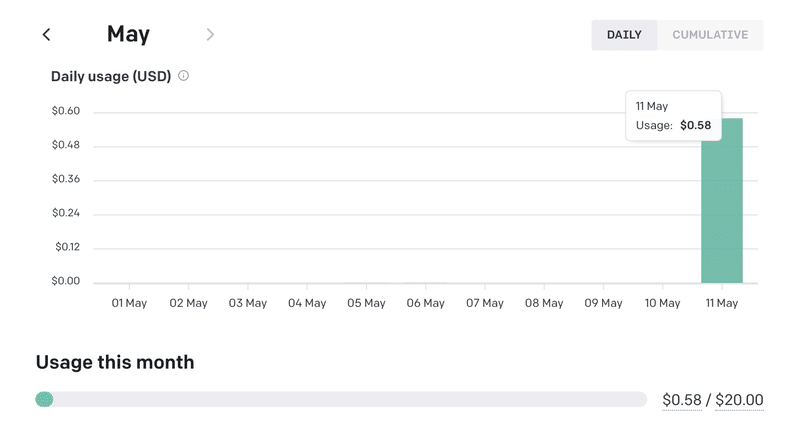
上記の利用で、だいたい、0.2ドルぐらいかかりました。
(以下は、このサイトを作成している日の利用料金です。他にも実行しているため、0.58ドルになっています)
ただ、この手のものは、あまりケチらない方がいいですね。
この記事が気に入ったらサポートをしてみませんか?