
Googleコラボで簡単に動的スクレイピングを始めよう!---Seleniumを使った実践ガイド付き

スクレイピングとはWebサイトから自動的にデータを取得する技術です。
データドリブンの重要性が高まる中、ぜひとも、身につけておきたいスキルだと思います。
ただ、初学者がスクレイピングをやろうとすると、
いろいろ、つまずきやすい箇所があります。
最たるものが以下の3つです
【つまずきやすいところ】
1️⃣ Pythonの環境構築が面倒
2️⃣ HTML・CSSがよく分からない
3️⃣ 動的サイトのスクレイピングが難しい
このうち、
1️⃣のPythonの環境構築が面倒という点は、
Googleコラボを使うことで解消されます。
また、
2️⃣のHTML・CSSが分からないという点も、
ChatGPTを活用すれば解消できます。
ChatGPTを活用したスクレイピングについて、詳しくはこちらのサイトを参照してください。
問題は、3️⃣の動的サイトのスクレイピングです。
そもそも動的サイトとは何か?については
後から詳しく説明しますが、
Googleコラボで動的サイトをスクレイピングするのは、
普通にやると、なかなか難しいという問題があります。
そこで、この記事では、
Googleコラボで、動的スクレイピングを
簡単に実現する方法を紹介します。
動的サイトとは何か?
ユーザーからのリクエスト、
例えば、フォームの送信やフィルターの適用などに応じて、
コンテンツが動的に変化するサイトのことです。
ユーザーごとのプロフィールページや
サイト上で検索結果をフィルタリングできるページなどを
想像していただくと分かりやすいでしょうか。
要は、表示内容がユーザーの動作によって変わるサイトです。
これとは逆に静的サイトとは
誰がいつ見ても同じ情報が表示されるサイトです。
動的サイトをスクレイピングするには?
動的サイトをスクレイピングするには、
あたかも人間のようにブラウザを操作する必要があります。
そして、ブラウザを操作するツールとして、
PythonではSeleniumというライブラリーが用意されており、
これを使います。
ちなみに、こうした動的サイトというのは
JavaScriptという言語が使われています。
この点、動的スクレイピングは、
JavaScriptで動的に生成されるコンテンツを取得する手法と
言えます。
なお、静的サイトの場合
Beautiful SoupやRequestsなどのライブラリを使用します。
一般的に、HTMLを直接解析するだけなので比較的簡単です。
GoogleコラボでSeleniumを使うためには?
これが最大の難関です。
というのも、GoogleコラボでSeleniumを使うためには、
GoogleChromeのバージョンと
ブラウザを動かすドライバー(Chromeドライバー)のバージョンを
あわせる必要があるのです。
これの何が大変かというと、
Chromeのバージョンがコロコロ変わってしまうので、
一度うまくいっても
次回はうまくいかないことがあるのです。
しかし、安心してください。
2024年5月現在ですが、
以下のコードを使えば、
ChromeのバージョンとChromeドライバーのバージョンを合わせることができます!
# 更新を実行
!sudo apt -y update
# 日本語フォントインストール
!apt install fonts-ipafont-gothic
# ダウンロードのために必要なパッケージをインストール
!rm -f *.deb
# 足りなくなったら継ぎ足していく(今回はlibvulkan1)
!sudo apt install -y wget curl unzip libvulkan1
# 以下はChromeの依存パッケージ
!wget http://archive.ubuntu.com/ubuntu/pool/main/libu/libu2f-host/libu2f-udev_1.1.4-1_all.deb
!dpkg -i libu2f-udev_1.1.4-1_all.deb
# Chromeのインストール
!wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
!dpkg -i google-chrome-stable_current_amd64.deb
#stableversionのバージョン名だけを取得する
import json
import subprocess
import os
# curlコマンドを実行してデータを取得
curl_command = "curl -sS https://googlechromelabs.github.io/chrome-for-testing/last-known-good-versions.json" # ここに取得したいURLを入力
completed_process = subprocess.run(curl_command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
# エラーチェック
if completed_process.returncode == 0:
# 成功した場合、データはcompleted_process.stdoutに格納されています
data = completed_process.stdout
else:
# エラーが発生した場合、エラーメッセージはcompleted_process.stderrに格納されています
error_message = completed_process.stderr
print("エラーメッセージ:")
print(error_message)
json_data = json.loads(data)
version_number = json_data["channels"]["Stable"]["version"]
#環境変数に入れる
os.environ["VERSION_NUMBER"] = version_number
print()
print(version_number)
# Chrome Driverのインストール
# 再実行した際に色々残っているとエラーになるので
!rm -rf /tmp/*
!wget -N https://storage.googleapis.com/chrome-for-testing-public/$VERSION_NUMBER/linux64/chromedriver-linux64.zip -P /tmp/
!unzip -o /tmp/chromedriver-linux64.zip -d /tmp/
!cp -rf /tmp/chromedriver-linux64 /tmp/chromedriver
!chmod +x /tmp/chromedriver/chromedriver
!mv /tmp/chromedriver/chromedriver /usr/local/bin/chromedriver
!pip install selenium以下を実行してバージョンがあっていれば合格です!
!google-chrome --version
!chromedriver --versionこれで、めでたく、
Googleコラボ上でSeleniumを使うことができます。
なお、これらのコードはこちらのサイトを参照しています。
実践!動的スクレイピング
実際に、Googleコラボでseleniumを使って
スクレイピングしていきましょう!
必ず、スクレイピングする時点で、
対象サイトの規約をチェックし、
スクレイピングが禁止されていないことを確認しましょう
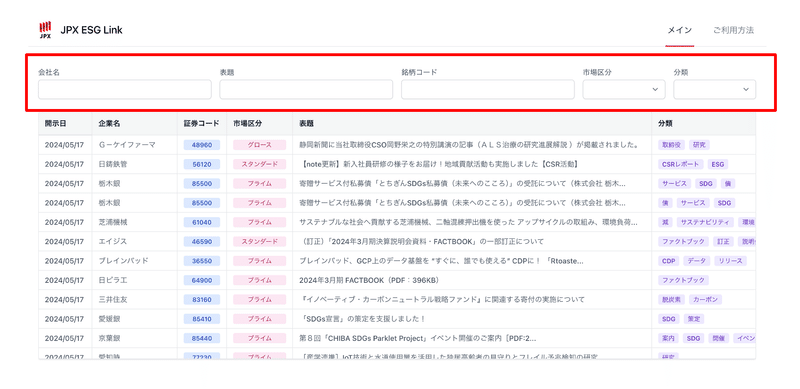
こちらのサイトをスクレイピングしていきます。
こちらのサイトは、
上場会社のホームページ上で開示されているESG関連ニュース及び統合報告書、サステナビリティレポートといったESG情報を含む報告書の該当ページ(HTML)又は資料(PDF)のURL、日付、ヘッドライン(表題)を収集したものになります。
この中から、統合報告書のURL、日付、会社名、ヘッドラインを取得していきます
サイトを開くと以下のようになっています。
赤く囲んだところを、ユーザーが選べるようになっています。
ユーザーの選択によって、画面表示が変わるので、動的サイトといえます。
スクレイピングの流れは次のとおりです。
まず、分類タブで統合報告書を選択し、表を更新する
更新した表データから、日付、企業名、証券コード、市場区分、表題、URLを取得する
ライブラリーのインポート
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import timeChromeドライバーの起動
# ChromeDriverの実際のパスを指定
chrome_driver_path = '/usr/local/bin/chromedriver' # 実際のパスに変更
# ブラウザオプションの設定
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
# ドライバーの起動
driver = webdriver.Chrome(service=Service(chrome_driver_path),
options=chrome_options
)ちょっと腕試し
実際にデータを取得する前に、
分類タブから「統合報告書」を選択し、
表データが更新されるかどうかを見てみましょう。
表データを更新した後、スクショを撮ってみます。
try:
# 指定されたURLにアクセス
driver.get('https://jpx.esgdata.jp/app')
# 「分類」ドロップダウンメニューが表示されるまで待機
wait = WebDriverWait(driver, 30)
type_dropdown = wait.until(EC.presence_of_element_located((By.NAME, "type")))
# JavaScriptを使用して「統合報告書」を選択
driver.execute_script("""
var select = arguments[0];
for (var i = 0; i < select.options.length; i++) {
if (select.options[i].text === '統合報告書') {
select.selectedIndex = i;
select.dispatchEvent(new Event('change'));
break;
}
}
""", type_dropdown)
# テーブルの更新が完了するまで待機
wait.until(EC.staleness_of(driver.find_element(By.XPATH, "//tbody/tr")))
# テーブルが再度ロードされるまで待機
wait.until(EC.presence_of_all_elements_located((By.XPATH, "//tbody/tr")))
# スクリーンショットを撮る
driver.save_screenshot('screenshot_after_selection.png')
finally:
# ブラウザを閉じる
driver.quit()
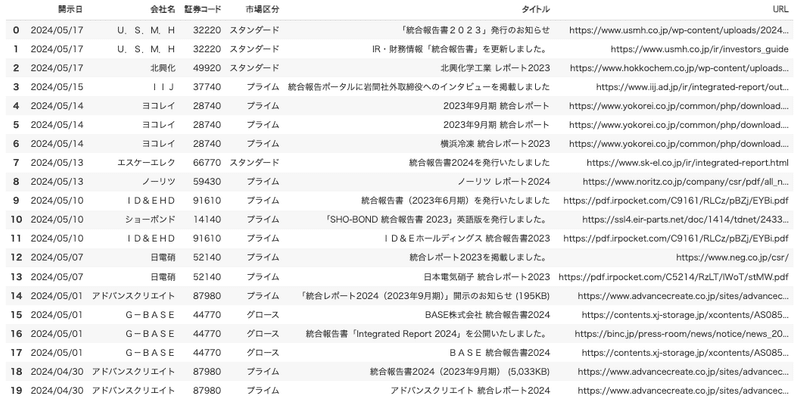
print("スクリーンショットを撮影しました。 'screenshot_after_selection.png' を確認してください。")screenshot_after_selection.pngを開いてみて、
こんな感じで、統合報告書だけを抜き出した表データが
取得できていれば成功です!

いざ、本番
このコードの最大のポイントは、
各行からfor文でデータを抽出する際に、
ゆっくりとスクロールさせていくことです!
スクロールさせなかったり、時間の間隔をとらないと
うまくいきません。
try:
# 指定されたURLにアクセス
driver.get('https://jpx.esgdata.jp/app')
# 「分類」ドロップダウンメニューが表示されるまで待機
wait = WebDriverWait(driver, 30)
type_dropdown = wait.until(EC.presence_of_element_located((By.NAME, "type")))
# JavaScriptを使用して「統合報告書」を選択
driver.execute_script("""
var select = arguments[0];
for (var i = 0; i < select.options.length; i++) {
if (select.options[i].text === '統合報告書') {
select.selectedIndex = i;
select.dispatchEvent(new Event('change'));
break;
}
}
""", type_dropdown)
# テーブルの更新が完了するまで待機
wait.until(EC.staleness_of(driver.find_element(By.XPATH, "//tbody/tr")))
# テーブルが再度ロードされるまで待機
wait.until(EC.presence_of_all_elements_located((By.XPATH, "//tbody/tr")))
# テーブル内の行を取得
rows = driver.find_elements(By.XPATH, "//tbody/tr")
# データを格納するリスト
data = []
# 各行からデータを抽出
for index, row in enumerate(rows):
try:
# 各行をスクロールして表示
driver.execute_script("arguments[0].scrollIntoView();", row)
time.sleep(2) # スクロール後に少し待機→ポイント!
print(f"Processing row {index + 1}/{len(rows)}")
# 各行の要素を取得
date = row.find_element(By.XPATH, "./td[1]").text
company = row.find_element(By.XPATH, "./td[2]").text
code = row.find_element(By.XPATH, "./td[3]/span").text
market = row.find_element(By.XPATH, "./td[4]").text
title_element = row.find_element(By.XPATH, "./td[5]/a")
title = title_element.text
url = title_element.get_attribute('href')
# データをリストに追加
data.append({
'開示日': date,
'会社名': company,
'証券コード': code,
'市場区分': market,
'タイトル': title,
'URL': url,
})
except Exception as e:
print(f"データの取得に失敗しました: {e}")
finally:
# ブラウザを閉じる
driver.quit()
# データフレームに変換
df = pd.DataFrame(data)
# データフレームを表示
display(df.head(20))こんな感じのものが出力されれば成功です
まとめ
この記事では、GoogleコラボとSeleniumを使って動的スクレイピングを簡単に始める方法を紹介しました。
Googleコラボを使えば、無料で手軽に強力なスクレイピング環境を構築できます。
ぜひ試してみてください!
参考リンク
• Selenium公式ドキュメント
• Googleコラボの使い方
この記事が気に入ったらサポートをしてみませんか?