Youtuber「鐵坊主」さんのやっている分析をpythonでやってみた

鐵坊主さんという方は、YouTubeで鉄道に関する動画を上げている方で、その動画は主に学術的な観点からのものが多いです。
その鐵坊主さんの動画で、時々、「○○駅から半径○○mの人口を調べて、その結果に基づいて路線や駅の現状や今後の見通しを分析する」というのがあります。
この動画は2022/06時点で6万再生されており、関心の高さが伺えますが、であれば、引用した動画の大糸線末端区間以外でも、この分析をやってみたいという方がいるんじゃないでしょうか。
そこで、pythonでやってみました。
必要なツール
geopandasという、多数の地理データに対して分析をすることに向いたツールを使います。geopandasがインストールできると、他に地理情報を扱うのに必要なツール(Shapelyなど)のインストールも行われます。
インストールは、pip install geopandas で可能ですが、Windows環境だとこのコマンドだけではインストールできないようです。検索するとインストールする方法も出てくるので、私はそれでしていますが、環境はLinuxのほうが楽です。
以下にコードを記していきますが、この実行の中で、pygeosというモジュールのインストールを求められます。pip install pygeosで予めインストールをしておけば大丈夫です。
コード:前処理
import geopandas as gpd
import pandas as pdpandasを使ったことがあれば、geopandasは基本的にはほぼ同様な動作をするものとして考えて良いと思います。pandas.DataFrameのかわりにgeopandas.GeoDataFrameというオブジェクトを操作していく感じになります。
kokusei_ = gpd.read_file('data/kokusei2020tokyo/r2ka13.shp', crs=4612)
stations_ = gpd.read_file('data/N02-17_Station.geojson', crs=4612).iloc[:, 2:]
stations_ = stations_[stations_.N02_003 == '五日市線']
kokusei_ = gpd.GeoDataFrame(pd.concat([kokusei_.iloc[:, :7], kokusei_.iloc[:, 24:26]], axis=1), geometry=kokusei_.loc[:, 'geometry']) 国土数値情報から全国の駅の位置データを、統計で見る日本・地図で見る統計から、東京都の人口データ・小地域、をダウンロードします。小地域データの解説については、鐵坊主さんの動画を見ればどのような感じのデータなのかわかると思います。
付随するデータが多いので、それぞれ、.ilocメソッドを使って削っていますが、これはしなくても良いです。
read_file()はShapeFileやGeoJSONなどの読み込みに対応しています。ここでcrs(座標系)を設定しておくと後々面倒が少ないです。日本の行政の出すデータは、(緯度経度座標系であれば)座標系の番号が4612であることが多いのでそのように設定しています。
今回は五日市線を対象にするので、路線名(列名:N02_003)が五日市線の駅だけを対象にするようにしています。ただし、この条件だけだと路線名が同じ路線(都営”新宿線”と西武”新宿線”など)が出てきてしまいます。五日市線は全国に他にないのでこの場合は大丈夫です。
kokusei = kokusei_.to_crs(2451)
stations = stations_.to_crs(2451)
stations.geometry = stations.centroid.buffer(1500)
kokusei['area_all'] = kokusei.area
stations['ekicode'] = stations.index to_crsというのは、座標系を変換するメソッドです。ここで、緯度経度座標系を平面直角座標系にしておかないと、距離の計算ができないのでそうしています。(注:平面直角座標系というのは、地球上のあるエリアに対し、そこを平面と仮定し、メートルなどの単位でXY座標を決定するものです。)
三行目で駅から1500mの円を生成しています。(このときに緯度経度座標系だと歪んだ円になってしまいます。)centroidというのは駅の重心を求めています。駅のデータは直線で示されるためこのような処理をしています。
後で必要なため、国勢調査の小地域の面積を求めた列と、駅を一意に特定するためのコード(仮に設定するものです)の列を生成しています。
コード:分析
overlay = gpd.overlay(kokusei, stations) geopandasのoverlayというメソッドを使います。引数一番目のGeoDataFrameのうち、二番目の引数のGeoDataFrameに被っている領域を計算し、GeoDataFrameとして返します。

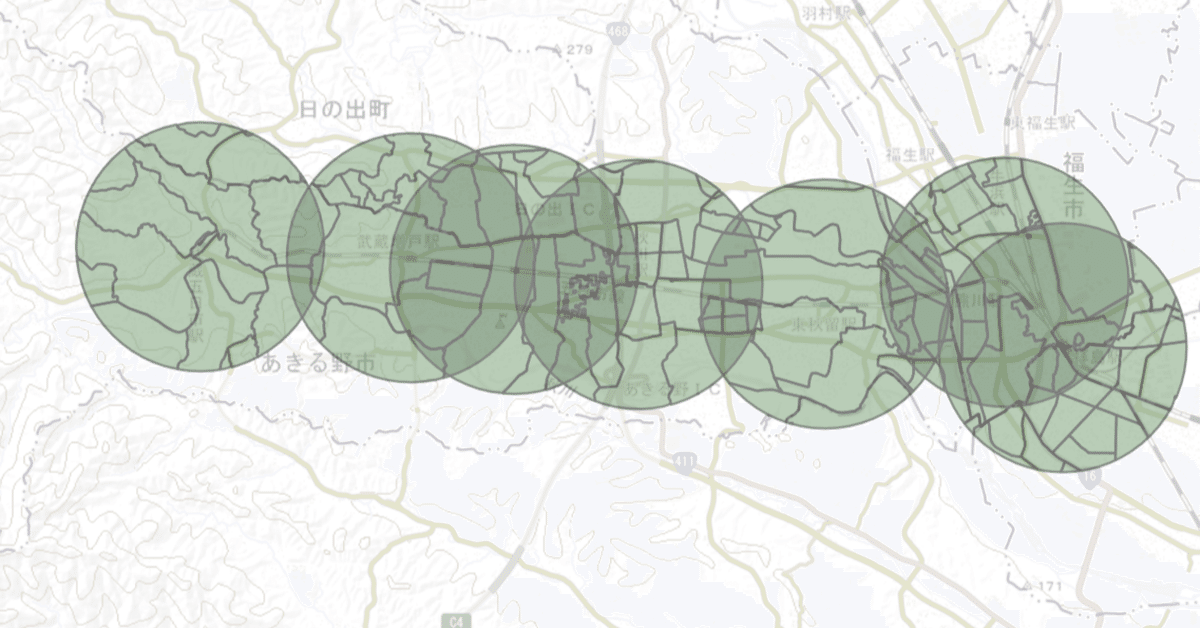
Overlayしてみた結果を可視化してみるとこのような感じになります
overlay['p'] = overlay.JINKO * (overlay.area / overlay.area_all)
station_population = overlay.loc[:, ['ekicode', 'p']].groupby('ekicode').sum().reset_index()
ans = pd.merge(stations, station_population, how='inner', on='ekicode').sort_values('p', ascending=False)
ans.p = round(ans.p).astype(int) overlayして得られた小地域のピースに対して、面積按分という処理を行います。一行目で、もとの小地域の人口✕(ピースの面積/もとの小地域の面積)とやっているのがそれです。これによって、ピースの部分の人口を推定します。
このままだと、バラバラに分裂したピースの部分の人口しか求まっていないので、groupbyを使って合計を求めます。また、按分した人口は小数になっているので、見た目的にあれなので一応四捨五入しておきます。
もとのデータとekicode(先ほど作った、駅を一意に特定する数字)で結合し、人口の多い順に並べます。

その結果をCSVとして出力したものです。最も人口の多い駅は拝島駅、少ない駅は武蔵五日市駅です。
五日市線は途中や終点にに人口の多い駅がなく、終点に近づくに従って駅周辺人口が減衰していく路線ということになります(注:CSV出力の際、偶然、拝島駅から順番にデータが並んでいますが、順番通りにならないこともあります)。ただし、武蔵五日市駅は檜原村からの長距離のバス路線があるなど、駅勢圏(駅の需要が発生する地域)が1500mよりも広範囲にあると考えられます。また、そのような地域への行楽の拠点でもあります。

以上の結果をGISソフトでみてみます。ファイルへの出力は、
ans.to_file('itsukaichi.geojson', driver='GeoJSON')のようにして行います。鐵坊主さんの動画ではGoogle earthを用いていますが、Google Earthで用いられるKMLという形式への出力は対応していません。QGISなどの別のソフトウェアを利用して変換する必要があります。
参考にさせていただきました
この記事が気に入ったらサポートをしてみませんか?