
WSL2でM2UGenを試してみる...

「大規模言語モデルの力を利用したマルチモーダルな音楽の理解と生成」が可能であるM2UGenを試します。
試してみなくても頭では分かっているが、試してみなくちゃどこがダメなのかが分からない。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
python3 -m venv m2ugen
cd $_
source bin/activategit cloneして、
git clone https://github.com/shansongliu/M2UGen.git
cd M2UGenpip installです。
pip install -r requirements.txt2. チェックポイントのダウンロード&配置
ディレクトリckptsを新規作成し、その下にファイルを諸々配置します。
$ pwd
/path/to/venv/m2ugen/M2UGen/M2UGen
$ mkdir ckptsまず、最終形の確認です。最終的なファイル配置は、こちら。
$ find ckpts/ -path '*/.git*' -prune -o -type f -print | grep -v README.md | sort
ckpts/LLaMA-2/7B/checklist.chk
ckpts/LLaMA-2/7B/consolidated.00.pth
ckpts/LLaMA-2/7B/params.json
ckpts/LLaMA-2/tokenizer.model
ckpts/LLaMA-2/tokenizer_checklist.chk
ckpts/M2UGen-AudioLDM2/checkpoint.pth
ckpts/M2UGen-MusinGen-medium/checkpoint.pth
ckpts/MERT-v1-330M/config.json
ckpts/MERT-v1-330M/configuration_MERT.py
ckpts/MERT-v1-330M/modeling_MERT.py
ckpts/MERT-v1-330M/preprocessor_config.json
ckpts/MERT-v1-330M/pytorch_model.bin
ckpts/vit-base-patch16-224-in21k/config.json
ckpts/vit-base-patch16-224-in21k/flax_model.msgpack
ckpts/vit-base-patch16-224-in21k/preprocessor_config.json
ckpts/vit-base-patch16-224-in21k/pytorch_model.bin
ckpts/vit-base-patch16-224-in21k/tf_model.h5
ckpts/vivit-b-16x2-kinetics400/config.json
ckpts/vivit-b-16x2-kinetics400/preprocessor_config.json
ckpts/vivit-b-16x2-kinetics400/pytorch_model.bin
$ひとつずつ、ダウンロードしていきましょう。
LLaMA-2
こちらは、MetaのページからダウンロードURLをゲットしてください。
ダウンロードは、GitHubのfacebookresearch/llamaにある download.sh を使用します。 ダウンロードしたファイルを以下のとおりに配置します。
ckpts/LLaMA-2/7B/checklist.chk
ckpts/LLaMA-2/7B/consolidated.00.pth
ckpts/LLaMA-2/7B/params.json
ckpts/LLaMA-2/tokenizer.model
ckpts/LLaMA-2/tokenizer_checklist.chkLLaMA-2以外
git cloneで所定のディレクトリに格納します。
# MERT
git clone https://huggingface.co/m-a-p/MERT-v1-330M ckpts/MERT-v1-330M
# ViT
git clone https://huggingface.co/google/vit-base-patch16-224-in21k ckpts/vit-base-patch16-224-in21k
# ViViT
git clone https://huggingface.co/google/vivit-b-16x2-kinetics400 ckpts/vivit-b-16x2-kinetics400
# M2UGen-MusinGen (medium)
git clone https://huggingface.co/M2UGen/M2UGen-MusicGen-medium ckpts/M2UGen-MusicGen-medium
# M2UGen-AudioLDM2
git clone https://huggingface.co/cvssp/audioldm2-music ckpts/M2UGen-AudioLDM23. GUIを起動してみる
起動 - MusicGen
以下のようにオプションを指定して、起動です。
python gradio_app.py --model ./ckpts/M2UGen-MusinGen-medium/checkpoint.pth --llama_dir ./ckpts/LLaMA-2 --mert_path ./ckpts/MERT-v1-330M --vit_path ./ckpts/vit-base-patch16-224-in21k --vivit_path ./ckpts/vivit-b-16x2-kinetics400 --music_decoder musicgenところが。
Initialize MERT...
(snip)
MERT initialized...
Initialize ViT...
ViT initialized...
Initialize ViViT...
(snip)
ViViT initialized...
(snip)
Initialize MusicGen...
(snip)
MusicGen initialized...
(snip)
Loading Model Checkpoint
Traceback (most recent call last):
File "/path/to/venv/m2ugen/M2UGen/M2UGen/gradio_app.py", line 78, in <module>
model.to("cuda")
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1160, in to
return self._apply(convert)
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/torch/nn/modules/module.py", line 810, in _apply
module._apply(fn)
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/torch/nn/modules/module.py", line 810, in _apply
module._apply(fn)
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/torch/nn/modules/module.py", line 810, in _apply
module._apply(fn)
[Previous line repeated 5 more times]
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/torch/nn/modules/module.py", line 833, in _apply
param_applied = fn(param)
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1158, in convert
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
RuntimeError: handle_0 INTERNAL ASSERT FAILED at "../c10/cuda/driver_api.cpp":15, please report a bug to PyTorch.「PyTorchにバグレポート、ぷりーず」とのランタイムエラー。これはさすがに万事休すか?
「あきらめたらそこで試合終了ですよ」ですから、発生した箇所 M2UGen/M2UGen/gradio_app.py を確認しましょう。すると、
model.to("cuda")とありました。2つ試してみたいことがあります。
(A) コメントアウトする
# model.to("cuda")実行すると、
Traceback (most recent call last):
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/gradio/queueing.py", line 388, in call_prediction
output = await route_utils.call_process_api(
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/gradio/route_utils.py", line 216, in call_process_api
output = await app.get_blocks().process_api(
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/gradio/blocks.py", line 1555, in process_api
result = await self.call_function(
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/gradio/blocks.py", line 1193, in call_function
prediction = await anyio.to_thread.run_sync(
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/anyio/to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 2134, in run_sync_in_worker_thread
return await future
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 851, in run
result = context.run(func, *args)
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/gradio/utils.py", line 654, in wrapper
response = f(*args, **kwargs)
File "/path/to/venv/m2ugen/M2UGen/M2UGen/gradio_app.py", line 287, in predict
response = model.generate(prompts, audio, image, video, 512, temperature, top_p,
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/path/to/venv/m2ugen/M2UGen/M2UGen/llama/m2ugen.py", line 683, in generate
logits, music_output_embedding = self.forward_inference(tokens[:, prev_pos:cur_pos], prev_pos,
File "/path/to/venv/m2ugen/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/path/to/venv/m2ugen/M2UGen/M2UGen/llama/m2ugen.py", line 517, in forward_inference
h = layer(h, 0, freqs_cis, mask, feats + prefix_query[prefix_index])
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!エラーでしたが、気になるエラーメッセージが。
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
「すべてのテンソルは、同じデバイスに存在することが期待されるが、少なくともcuda:0とcpuがあるぞ!」
「ふっ、cuda:1もあるんだがな」などとマウントを取っても仕方ない。このメッセージから推測するに「全部のチェックポイントを1枚のGPUに載せないとダメ」ということか。
(B) CUDA_VISIBLE_DEVICESを変更する
export CUDA_VISIBLE_DEVICES=01つにして再実行します。
再実行 - MusicGen
気合いを入れてエンターです。
$ python gradio_app.py --model ./ckpts/M2UGen-MusinGen-medium/checkpoint.pth --llama_dir ./ckpts/LLaMA-2 --mert_path ./ckpts/MERT-v1-330M --vit_path ./ckpts/vit-base-patch16-224-in21k --vivit_path ./ckpts/vivit-b-16x2-kinetics400 --music_decoder musicgen
(snip)
Initialize MERT...
(snip)
MERT initialized...
Initialize ViT...
ViT initialized...
Initialize ViViT...
(snip)
ViViT initialized...
(snip)
Initialize MusicGen...
(snip)
MusicGen initialized...
(snip)
Loading Model Checkpoint
(snip)
Running on local URL: http://0.0.0.0:24000そして、

gradioの起動までこぎ着けました。
リソース使用状況
WSL2への割り当てメモリは 52GB にしています。起動途中、pythonプロセスは最大40.9GBを使用していました。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
516 shoji_n+ 20 0 130.6g 40.9g 277720 R 1555 80.2 10:08.86 python
317 root 20 0 80632 70176 17988 S 0.0 0.1 0:01.38 python3.10gradioが起動した直後のGPUメモリは 25.9GB。つまり、2.4GBほど溢れてました…。これはいつか見た風景。

4. 試してみる
あまり期待をせずに試してみます。
試してみるその前に。
弊環境、オンボード含めてGPUが3つあります。
チェックポイントのロードは、先のGPUリソース使用状況で示したとおり、RTX 4090のメモリを使用しています。
しかしながら、生成処理においては内蔵GPU(Intel UHD Graphics)のCPUを使用してしまうという事象が発生しました。これを回避するため、以下のようにデバイスを強制的に無効にして試しています。

では、本題に戻ります。
音楽を生成して
Textに以下のように入力して、
Generate a dance music that sounds like it was composed by Tetsuya Komuro.
(意訳)てっちゃんみたいな曲、作って。
「Submit & Run」をクリックします。待つこと6分、ターミナルに
Generating Music...というログが出力されました。クリックしてからの数分間、いったい何が行われていたのか。これから音楽を生成するとのことなので、とりあえずは待ちましょう。
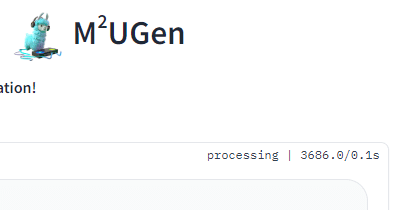
1時間(3,600秒)経過しましたが、まだ音楽は生成されない…。

GPUが使用するメモリは増えていく…。
生成できました

そして、クリックしてから約2時間30分が経過し、GPUメモリ使用が34.7GBとなった、そのとき….

応答来ました。ターミナルのログはこのような表示。
['Here is a music that is a perfect match for the given description - a dance music with a strong beat and synthesizer arrangements that could be composed by Tetsuya Komuro. [AUD0] [AUD1] [AUD2] [AUD3] [AUD4] [AUD5] [AUD6] [AUD7] ', {'aud': [array([-0.08458019, -0.0941334 , -0.06601215, ..., 0.08052649,
0.066418 , 0.07769527], dtype=float32)]}]
temp/zth81rl3.wav
text_outputs: ['Here is a music that is a perfect match for the given description - a dance music with a strong beat and synthesizer arrangements that could be composed by Tetsuya Komuro. ', '<Audio>temp/zth81rl3.wav</Audio> ']確かにwavファイルも生成されています!
$ ls -al ./temp/zth81rl3.wav
-rw-r--r-- 1 user user 3924538 Jan 11 04:00 ./temp/zth81rl3.wav
$5. まとめ
コンシューマ向けGPU(RTX 4090)ではまともに動かない、ということを実体験しました。
生成中もメモリはどんどん増えていき、一つ目の生成時点で34.7GBですから、少なくともVRAM 40GBはないとまともには動かないのだと思います。はい。
関連
この記事が気に入ったらサポートをしてみませんか?