
WSL2でMoore-AnimateAnyoneを試してみる

npaka先生の記事をみて、試してみたくなったので試しました。
先生、ありがとうございます!
ここでは、環境に依存する箇所を中心にまとめます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
python3 -m venv moore-animateAnyone
cd $_
source activateリポジトリのクローンとパッケージのインストールです。
git clone https://github.com/MooreThreads/Moore-AnimateAnyone
cd Moore-AnimateAnyone
pip install -r requirements.txtあと、vid2pose.py(ビデオからPoseへ)を実行する際に「パッケージcontrolnet_aux が見当たらない」と怒られました。それをインストールしても「mediapipeパッケージが無いと機能が制限されるよ」との警告メッセージが出力されました。結果として、以下の2つをインストールしておきます。
pip install controlnet_aux mediapipe動作に必要なファイルを pretrained_weights ディレクトリ下に配置します。
※詳細は、npaka大先生のnoteを参照ください。
$ tree pretrained_weights/
pretrained_weights/
├── DWPose
│ ├── dw-ll_ucoco_384.onnx
│ └── yolox_l.onnx
├── denoising_unet.pth
├── image_encoder
│ ├── config.json
│ └── pytorch_model.bin
├── motion_module.pth
├── pose_guider.pth
├── reference_unet.pth
├── sd-vae-ft-mse
│ ├── README.md
│ ├── config.json
│ ├── diffusion_pytorch_model.bin
│ └── diffusion_pytorch_model.safetensors
└── stable-diffusion-v1-5
├── feature_extractor
│ └── preprocessor_config.json
├── model_index.json
├── unet
│ ├── config.json
│ └── diffusion_pytorch_model.bin
└── v1-inference.yaml
6 directories, 17 files2. 試してみる - pose2vid.py
Poseからビデオへ変換です。
絵心がないため、いらすとやから拝借してきます。

(注)当然にドラえもんで試したわけですが、耐えがたい結果なのと著作権が。Poseの体型?にあわせないと…ですね。
手元にRTX 4090というprefixのGPUが2枚ありますので、それぞれで試してみましょう。
いらすとやの全身タイツさんを configs/inference/ref_images ディレクトリに格納し、
$ ls -l configs/inference/ref_images/
total 2724
-rw-rw-r-- 1 user user 505852 Jan 15 16:32 anyone-1.png
-rw-rw-r-- 1 user user 431296 Jan 15 16:32 anyone-10.png
-rw-rw-r-- 1 user user 516239 Jan 15 16:32 anyone-11.png
-rw-rw-r-- 1 user user 295856 Jan 15 16:32 anyone-2.png
-rw-rw-r-- 1 user user 493409 Jan 15 16:32 anyone-3.png
-rw-rw-r-- 1 user user 177205 Jan 15 16:32 anyone-5.png
-rw-r--r-- 1 user user 244689 Jan 15 18:02 fashion_zenshin_taitsu.png設定ファイル configs/prompts/animation.yaml のtest_caseの箇所を修正します。
$ cat configs/prompts/animation.yaml
pretrained_base_model_path: "./pretrained_weights/stable-diffusion-v1-5/"
pretrained_vae_path: "./pretrained_weights/sd-vae-ft-mse"
image_encoder_path: "./pretrained_weights/image_encoder"
denoising_unet_path: "./pretrained_weights/denoising_unet.pth"
reference_unet_path: "./pretrained_weights/reference_unet.pth"
pose_guider_path: "./pretrained_weights/pose_guider.pth"
motion_module_path: "./pretrained_weights/motion_module.pth"
inference_config: "./configs/inference/inference_v2.yaml"
weight_dtype: 'fp16'
test_cases:
"./configs/inference/ref_images/fashion_zenshin_taitsu.png":
- "./configs/inference/pose_videos/anyone-video-2_kps.mp4"
$(1) RTX 4090 (24GB)
動画生成は1秒間としました。3回ほど計測しましたが、だいたい4分30秒前後で生成完了します。
$ time python -m scripts.pose2vid --config ./configs/prompts/animation.yaml -W 512 -H 784 -L 64
Some weights of the model checkpoint were not used when initializing UNet2DConditionModel:
['conv_norm_out.weight, conv_norm_out.bias, conv_out.weight, conv_out.bias']
/home/shoji_noguchi/devsecops/venv/Moore-AnimateAnyone/lib/python3.10/site-packages/torch/_utils.py:776: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.__get__(instance, owner)()
pose video has 136 frames, with 30 fps
/home/shoji_noguchi/devsecops/venv/Moore-AnimateAnyone/Moore-AnimateAnyone/src/pipelines/pipeline_pose2vid_long.py:406: FutureWarning: Accessing config attribute `in_channels` directly via 'UNet3DConditionModel' object attribute is deprecated. Please access 'in_channels' over 'UNet3DConditionModel's config object instead, e.g. 'unet.config.in_channels'.
num_channels_latents = self.denoising_unet.in_channels
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [03:37<00:00, 7.26s/it]100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 64/64 [00:08<00:00, 7.48it/s]
real 4m26.861s
user 5m42.420s
sys 0m37.100sいらすとやの全身タイツさんもすらっとしていますが、できあがった動画はさらにシュッとしています。
VRAMは、ちょうど 20.0GB。溢れることなく動きました。
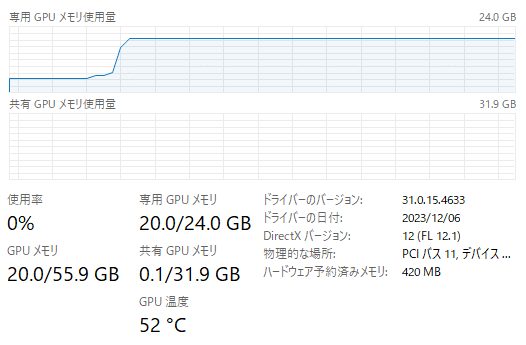
(2) RTX 4090 Laptop GPU(16GB)
VRAM、足りませんでした。実行前、VRAMを1.0GB使用済みでしたので、19.2 -15.6-1.0、2.6GBほど溢れています。
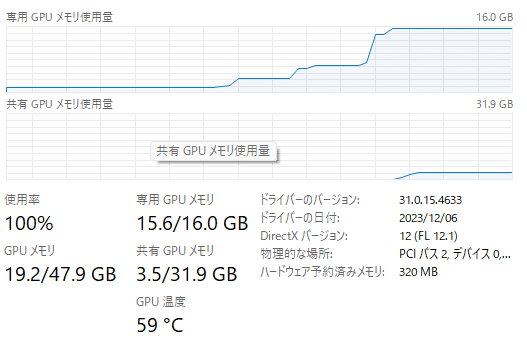
動画生成も同じ題材で 27分ほどかかりました。
real 26m57.355s
user 27m50.595s
sys 0m27.301s24GBと比較すると6倍の時間がかかりますが、動きはします。
3-1. 試してみる - vid2pose.py
絵心が無いので、こちらのフリー動画をPoseに変換します。

toolsディレクトリの下にvid2pose.pyがあります。引数にこの動画ファイルへのパスを指定して実行です。
$ python -m tools.vid2pose --video_path configs/inference/pose_videos/dance-46012.mp4だがしかし。「CUDAExecutionProviderが見つからない」との警告メッセージが出力されました。少なくとも2つあるのに…。
/path/to/venv/Moore-AnimateAnyone/lib/python3.10/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py:69: UserWarning: Specified provider 'CUDAExecutionProvider' is not in available provider names.Available providers: 'AzureExecutionProvider, CPUExecutionProvider'
調べたところ、onnxruntimeパッケージのインストール方法に問題があるよう。
以下のように onnxruntime と onnxruntime-gpuのパッケージを削除後、onnxruntime-gpuパッケージだけをインストールすると良いようです。
pip uninstall onnxruntime onnxruntime-gpu
pip install onnxruntime-gpu(1) RTX 4090(24GB)
1分ほどでPoseができました。
real 0m54.841s
user 0m50.182s
sys 0m26.574sできたPoseはこちら。
気になるVRAMの使用状況です。
Windowsのモニタだと最大値をうまく収集できなかったため、nvidia-smiコマンドで1秒単位に収集したテータから見てみます。
$ grep ^1 log/gpu-Moore-AnimateAnyone-20240115-231634.log | sort -k 10 -n | tail -1
1, 2024/01/15 23:16:59.275, 97 %, 6 %, 24564 MiB, 17563 MiB, 36, NVIDIA GeForce RTX 4090
$最大値を見るに、VRAMは最大17GB(17,563 MiB)付近でした。
(2) RTX 4090 Laptop GPU(16GB)
数回試しましたが、実行時間はほぼ変わらず。
real 0m52.361s
user 0m48.415s
sys 0m26.812sVRAMは、10GB~11GB付近という結果でした。
$ grep ^0 log/gpu-Moore-AnimateAnyone-20240115-231634.log | sort -k 10 -n | tail -1
0, 2024/01/15 23:18:45.124, 70 %, 31 %, 16376 MiB, 10658 MiB, 53, NVIDIA GeForce RTX 4090 Laptop GPU3-2. 試してみる - pose2vid.py
設定ファイル configs/prompts/animation.yaml の最下行を、生成したPoseのパスへと書き改めます。
pretrained_base_model_path: "./pretrained_weights/stable-diffusion-v1-5/"
pretrained_vae_path: "./pretrained_weights/sd-vae-ft-mse"
image_encoder_path: "./pretrained_weights/image_encoder"
denoising_unet_path: "./pretrained_weights/denoising_unet.pth"
reference_unet_path: "./pretrained_weights/reference_unet.pth"
pose_guider_path: "./pretrained_weights/pose_guider.pth"
motion_module_path: "./pretrained_weights/motion_module.pth"
inference_config: "./configs/inference/inference_v2.yaml"
weight_dtype: 'fp16'
test_cases:
"./configs/inference/ref_images/fashion_zenshin_taitsu.png":
- "./configs/inference/pose_videos/dance-46012_kps.mp4"28秒ほどありますが、いったんL=256で生成します。
time python -m scripts.pose2vid --config ./configs/prompts/animation.yaml -W 512 -H 784 -L 1792(1) RTX 4090(24GB)
13分ほどかかりました。Poseの動画サイズがサンプルよりも大きめだからですかね。
100%|██████████████████████████████████████████████████████████████████████████████████████| 30/30 [11:45<00:00, 23.51s/it]
100%|████████████████████████████████████████████████████████████████████████████████████| 256/256 [00:36<00:00, 7.05it/s]
real 12m53.024s
user 14m44.452s
sys 0m43.131s生成された動画はこちら。10秒ほど。黒タイツ、踊っています。
VRAMは20GBほど。
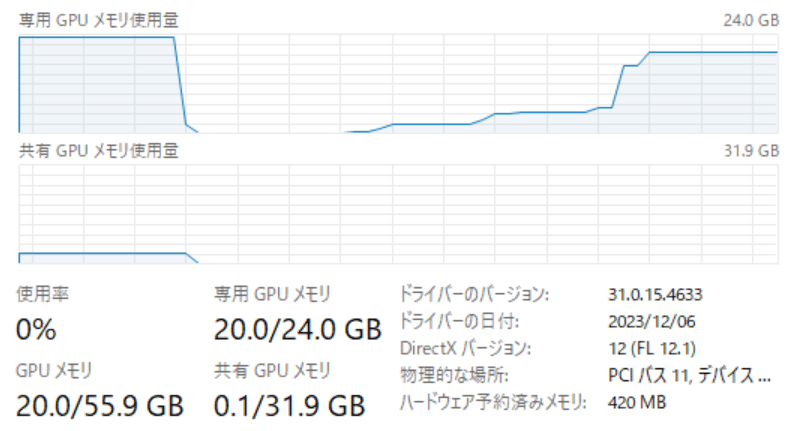
動画生成の秒数を増やすとVRAMの使用量も段階的に増えていきます。8秒にすると25.6GBと溢れてしまいました。
(Steamで書き出せばよいとは思いますが、試していません)
以下の記事で書いたスクリプトを使用して、
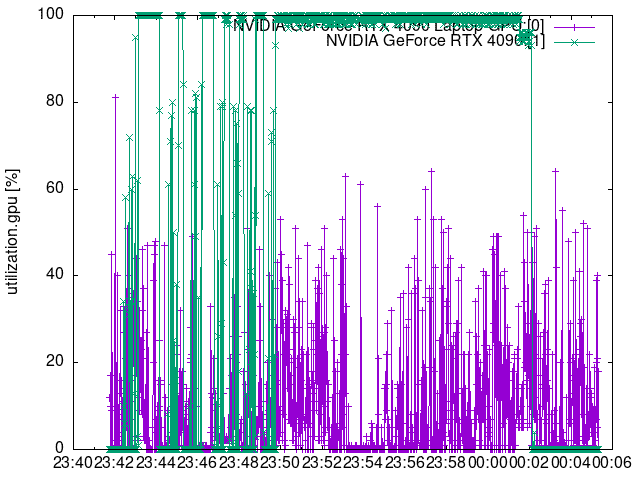
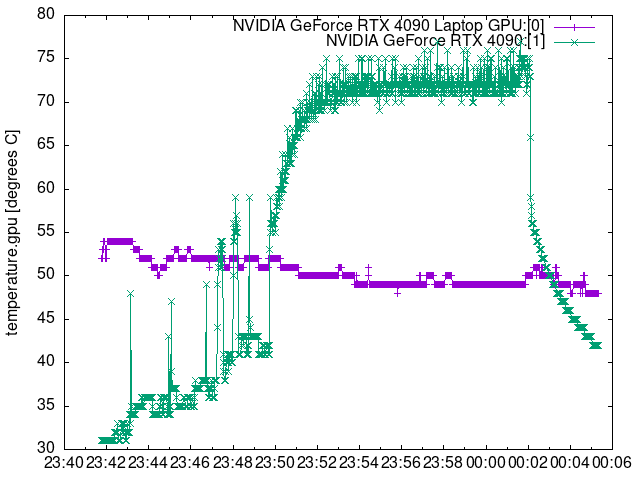
可視化すると以下のような感じです。緑色がRTX 4090のグラフです。
●メモリ使用量 MiB
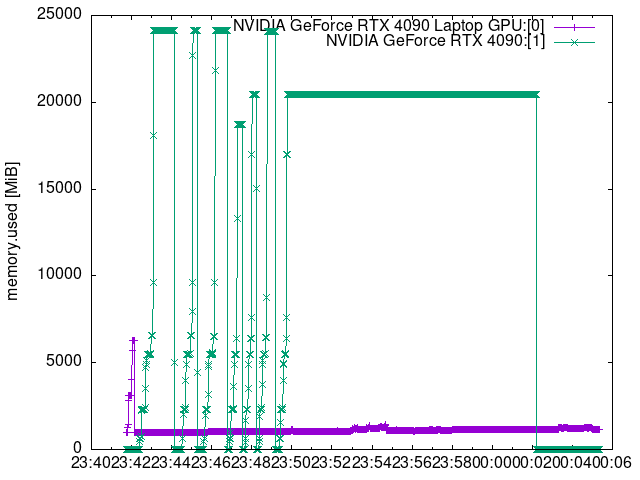
●GPU使用率 %
●温度 ℃
(2) RTX 4090 Laptop GPU(16GB)
VRAMは、4.4 GBほど溢れました。 ※21.0 - 15.6 - 1.0 GB

100%|████████████████████████████████████████████████████████████████████████████████████| 256/256 [01:12<00:00, 3.52it/s]
real 63m18.319s
user 64m37.171s
sys 1m18.405s63分かかりました…。
4. まとめ
onnxruntimeパッケージは、onnxruntimeとonnxruntime -gpuの2つインストールするのではなく、onnxruntime-gpuだけにしましょう。
ローカルで動かすためには、少なくともVRAM 24GBは必要です。
この記事が気に入ったらサポートをしてみませんか?