
WSL2でInstantIDを試してみる

「チューニング不要の新しい最先端の方法であり、単一画像のみでアイデンティティを保持した生成を実現し、さまざまなダウンストリーム タスクをサポート」するらしい「InstantID : Zero-shot Identity-Preserving Generation in Seconds」を試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
準備
python環境
venvを構築して、
python3 -m venv instantid
cd $_
source bin/activatepip installします。
pip install opencv-python transformers accelerate insightface onnxruntime-gpu diffusersInstantID環境
リポジトリをクローンします。
git clone https://github.com/InstantID/InstantID.git
cd InstantIDチェックポイントを ./checkpoints ディレクトリにダウンロードします。
huggingface_hubパッケージをインストールし、pythonを起動。
pip install huggingface_hub
python以下を流し込んで、3つのファイルをダウンロードします。
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="InstantX/InstantID", filename="ControlNetModel/config.json", local_dir="./checkpoints")
hf_hub_download(repo_id="InstantX/InstantID", filename="ControlNetModel/diffusion_pytorch_model.safetensors", local_dir="./checkpoints")
hf_hub_download(repo_id="InstantX/InstantID", filename="ip-adapter.bin", local_dir="./checkpoints")つづいて、antelopev2.zip - Google Drive を ./models ディレクトリに配置します。wgetやcurlコマンドですと面倒なので、ブラウザでダウンロードして配置します。ダウンロードしたzipファイルをunzipします。
unzip antelopev2.zip -d models以下のように展開されます。
$ find models/
models/
models/antelopev2
models/antelopev2/scrfd_10g_bnkps.onnx
models/antelopev2/genderage.onnx
models/antelopev2/glintr100.onnx
models/antelopev2/1k3d68.onnx
models/antelopev2/2d106det.onnx流し込むコード
(1) モデルをロードするコード
READMEのUsageにあるサンプルコードのままですと動きませんでした。
・2箇所あるモデルロードの引数にdevice_map="auto" を追加
・StableDiffusionXLInstantIDPipeline.from_pretrainedメソッドの戻り値に帯する .cuda() を削除
修正後のコードは以下です。
import diffusers
from diffusers.utils import load_image
from diffusers.models import ControlNetModel
import cv2
import torch
import numpy as np
from PIL import Image
from insightface.app import FaceAnalysis
from pipeline_stable_diffusion_xl_instantid import StableDiffusionXLInstantIDPipeline, draw_kps
# prepare 'antelopev2' under ./models
app = FaceAnalysis(name='antelopev2', root='./', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
# prepare models under ./checkpoints
face_adapter = f'./checkpoints/ip-adapter.bin'
controlnet_path = f'./checkpoints/ControlNetModel'
# load IdentityNet
controlnet = ControlNetModel.from_pretrained(
controlnet_path,
device_map="auto",
torch_dtype=torch.float16
)
base_model = 'wangqixun/YamerMIX_v8' # from https://civitai.com/models/84040?modelVersionId=196039
pipe = StableDiffusionXLInstantIDPipeline.from_pretrained(
base_model,
controlnet=controlnet,
device_map="auto",
torch_dtype=torch.float16
)
# load adapter
pipe.load_ip_adapter_instantid(face_adapter)(2) 画像を生成するコード
a. こちらもサンプルコードのままだとエラーになります。修正箇所は以下です。代入先の変数imageを face_imageに文字列置換します。
image = load_image(file_path)b. negative_prompt変数が使用されていないので、コメントアウトしておきます。ま、pipelineに設定しても良いのですが。
c. 何度も繰り返し実行できるように関数にしておきます。引数としては
・画像ファイルへのパス
・プロンプト(任意)
です。
d. 生成した画像は確認したいですよね?ついでに、showもしましょう。
e. 生成した画像のファイルへの保存(save)もファイル名が重複しないようにしておきます。
修正後のコードはこちら。
import os
import time
def i(
file_path: str,
prompt: str=None,
):
# load an image
face_image = load_image(file_path)
# prepare face emb
face_info = app.get(cv2.cvtColor(np.array(face_image), cv2.COLOR_RGB2BGR))
face_info = sorted(face_info, key=lambda x:(x['bbox'][2]-x['bbox'][0])*x['bbox'][3]-x['bbox'][1])[-1] # only use the maximum face
face_emb = face_info['embedding']
face_kps = draw_kps(face_image, face_info['kps'])
if not prompt:
prompt = "film noir style, ink sketch|vector, male man, highly detailed, sharp focus, ultra sharpness, monochrome, high contrast, dramatic shadows, 1940s style, mysterious, cinematic"
#negative_prompt = "ugly, deformed, noisy, blurry, low contrast, realism, photorealistic, vibrant, colorful"
# generate image
pipe.set_ip_adapter_scale(0.8)
image = pipe(
prompt,
image_embeds=face_emb,
image=face_kps,
controlnet_conditioning_scale=0.8,
).images[0]
# save a generated image to "./outputs/image_%Y%m%d_%H%M%S.jpg"
image_basename = os.path.splitext(os.path.basename(file_path))[0]
outdir="outputs"
os.makedirs(outdir, exist_ok=True)
image.save(outdir + os.sep + image_basename + "_" + time.strftime('%Y%m%d_%H%M%S') + ".jpg")
# show image
image.show()(3) 修正後コードのまとめ
流し込みやすいように、まとめておきます。
import diffusers
from diffusers.utils import load_image
from diffusers.models import ControlNetModel
import cv2
import torch
import numpy as np
from PIL import Image
from insightface.app import FaceAnalysis
from pipeline_stable_diffusion_xl_instantid import StableDiffusionXLInstantIDPipeline, draw_kps
# prepare 'antelopev2' under ./models
app = FaceAnalysis(name='antelopev2', root='./', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
# prepare models under ./checkpoints
face_adapter = f'./checkpoints/ip-adapter.bin'
controlnet_path = f'./checkpoints/ControlNetModel'
# load IdentityNet
controlnet = ControlNetModel.from_pretrained(
controlnet_path,
device_map="auto",
torch_dtype=torch.float16
)
base_model = 'wangqixun/YamerMIX_v8' # from https://civitai.com/models/84040?modelVersionId=196039
pipe = StableDiffusionXLInstantIDPipeline.from_pretrained(
base_model,
controlnet=controlnet,
device_map="auto",
torch_dtype=torch.float16
)
# load adapter
pipe.load_ip_adapter_instantid(face_adapter)
import os
import time
def i(
file_path: str,
prompt: str=None,
):
# load an image
face_image = load_image(file_path)
# prepare face emb
face_info = app.get(cv2.cvtColor(np.array(face_image), cv2.COLOR_RGB2BGR))
face_info = sorted(face_info, key=lambda x:(x['bbox'][2]-x['bbox'][0])*x['bbox'][3]-x['bbox'][1])[-1] # only use the maximum face
face_emb = face_info['embedding']
face_kps = draw_kps(face_image, face_info['kps'])
if not prompt:
prompt = "film noir style, ink sketch|vector, male man, highly detailed, sharp focus, ultra sharpness, monochrome, high contrast, dramatic shadows, 1940s style, mysterious, cinematic"
#negative_prompt = "ugly, deformed, noisy, blurry, low contrast, realism, photorealistic, vibrant, colorful"
# generate image
pipe.set_ip_adapter_scale(0.8)
image = pipe(
prompt,
image_embeds=face_emb,
image=face_kps,
controlnet_conditioning_scale=0.8,
).images[0]
# save a generated image to "./outputs/image_%Y%m%d_%H%M%S.jpg"
image_basename = os.path.splitext(os.path.basename(file_path))[0]
outdir="outputs"
os.makedirs(outdir, exist_ok=True)
image.save(outdir + os.sep + image_basename + "_" + time.strftime('%Y%m%d_%H%M%S') + ".jpg")
# show image
image.show()ためしてみる
作成したコードをpythonに流し込みます。
そして、サンプルにあった誰かに似ている画像を入力にして、

とりあえず、景気よく9枚ぐらい作りましょう。
for idx in range(9):
i("./examples/musk_resize.jpeg")生成された画像はこちら。

1枚あたりの画像生成時間は 32秒でした。
100%|██████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:32<00:00, 1.54it/s]GPUリソース
メモリ使用量の変化
(1) コントロールネットモデルをロード
専用GPUメモリ 3.6GB
# load IdentityNet
controlnet = ControlNetModel.from_pretrained(
controlnet_path,
device_map="auto",
torch_dtype=torch.float16
)
(2) StableDiffusionXLInstantIDPipelineでモデルYamerMIX_v8をロード
専用GPUメモリ 10.5GB(+6.9GB)
base_model = 'wangqixun/YamerMIX_v8' # from https://civitai.com/models/84040?modelVersionId=196039
pipe = StableDiffusionXLInstantIDPipeline.from_pretrained(
base_model,
controlnet=controlnet,
device_map="auto",
torch_dtype=torch.float16
)
(3) 画像生成している最中
専用GPUメモリ 22.3GB(+11.8GB)

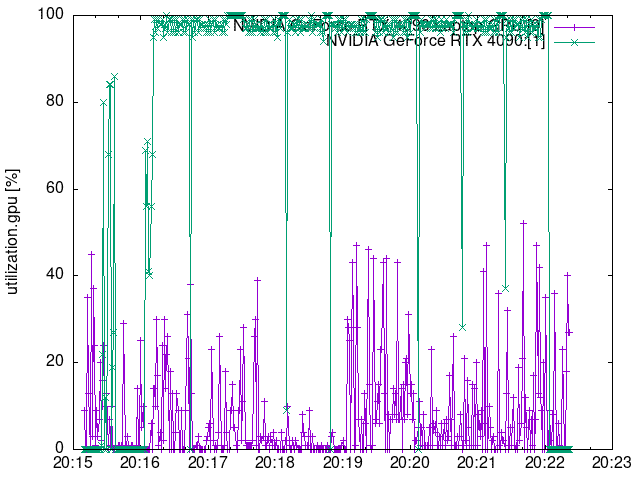
グラフ
以下の記事で書いた方法でプロットしたグラフはこちら。
緑色が今回の画像生成で使用した RTX 4090(24GB)のグラフです。
GPU使用率
メモリ使用量

温度

まとめ
ロードするモデルに依りますが、RTX 4090(24GB)ならば普通に動くことがわかりました。
おまけ
ベースモデルを本家SDXLに変更
base_model = 'stabilityai/stable-diffusion-xl-base-1.0'生成した画像がこちら。

HuggingFaceのデモ
こちらも普通にローカルで動きます。

関連
この記事が気に入ったらサポートをしてみませんか?