
成功への道標~ニューラルワークスPredict入門

はじめに
読者がお持ちのデータ解析問題の究極の解決策である強力なPredictの世界へようこそ。Predictは、データを分析し、行動につなげることのできる知識を生成する、強靭なニューラルネットワークを構築するための先進のモデリングとデータマイニングのためのプラットホームです。
読者がビジネスユーザー、科学者、エンジニアまたは解決方法を模索している分析者のどなたに対しても、この短編“成功への近道”により、Predictの威力を最大限活用する方法をご理解されると思います。
ニューラルネットワークは、データ間の複雑な関係性や未知の関係性を発見するための技術で、長い時間と実績によりその有用性が証明されてきた技術です。基本的には、ニューラルネットワークはパターンを発見します。最初に、それは経験的データからの一般化されたパターンを学習します。そして、それが同じ問題領域からの新しいデータと類似したパターンを認識したとき、ニューラルネットワークは出力値(すなわち、教師なしでの予測または分類の決定)を生成することができます。
あなたのデータ分析の要求がたとえ何であっても、Predictは役に立つでしょう。現在、Predictの威力により、以下のような世界中のさまざまな産業で、広範囲にわたる問題を解決しています:
・市場タイミング、株選択、資産分散などに影響を与える金融市場傾向
の見極め
・与信審査と信用供与後のリスク管理
・治療法選択に影響最も効果的治療を提起する、複雑な医学条件の分析
・マーケティンターゲットマーケティングのため、特定の特徴を持つ
人口統計的グループの選定
・製造プロセスのコントロールとサプライ・チェーンの最適化のモデル構築
・生物学的特徴を識別、抽出して分類したり、手書きの文字や話し言葉を
認識、さらに事実上あらゆる種類のイメージ・データでも処理し解読
・その他、様々な分野に対して!
基礎的なコンピュータのスキルがあって、Excelに精通していれば、あなたもPredictの威力を利用できる準備ができていることになります!
この 成功への道標 を読了したあと、使い初めにあたって でさらなるPredictの機能と能力を堪能することができます。より詳細な情報がこのガイドの終わりにあります。
始める前に、以下の点に注意してください:
・体験使用モードでPredictを実行しているならば、たとえモデルを保存ダイアログボックスが現れても、モデルを保存することができません。
・また、体験使用モードでPredictを使って、あなた自身の応用データを分析することができます;しかし、体験使用モードにはデータのサイズに制限があり、32列、512のレコードまでのデータしが処理することができません。もちろん、完全に公認の製品は、数千列と数十万レコード(数100万レコードさえ)を扱うことができます!
ニューラルネットワークおよびPredictソフトウェアに関連した用語の簡単な説明用として、このガイドの最後に用語集があります。
では早速始めましょう!
以降の説明では、読者のコンピュータ上にExcelがインストールされ、またPredictソフトウェアが正しくインストールされ、この成功への道標が確認できていることを仮定いたします。準備ができていれば、早速始めましょう!
Excelが読者のコンピュータにない、あるいは、Predictソフトウェアをインストールしていないならば、この続きを読む前にそれらの手続きを行ってください。
Excelを起動することによって、Predictを実行できます―PredictはExcelメニューバーあるいはアドインタブ中の新しいメニューになります。それでは、Excelを起動してください。
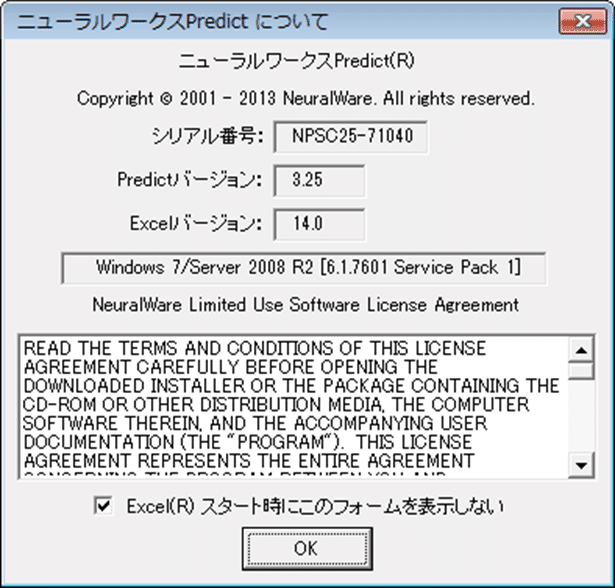
ニューラルワークスPredictについてダイアログボックスは、読者がPredictをインストールしたあと初めてExcelを起動したときに現れます:
このチェックボックスを選択し、OKをクリックして続けてください。
ソフトウェアライセンスの有効化
製品版Predict製品(評価用のライセンスも提供していますのでご相談ください)を実行時に、ライセンスキーがまだ入力されていないならば、ニューラルワークスPredictライセンスキー管理ダイアログボックスが表示されます。
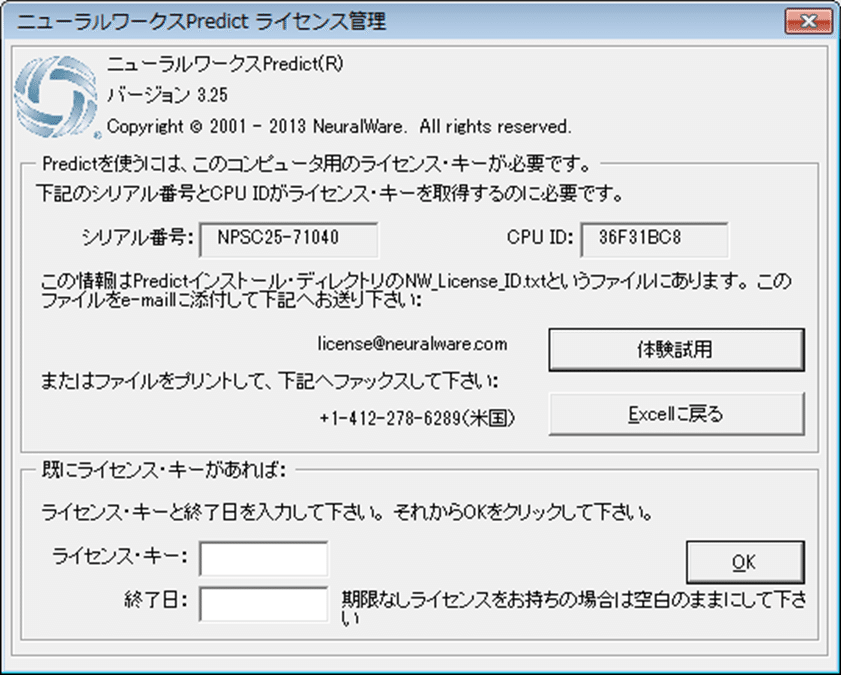
このダイアログボックスが現れたとき、あなたがすでにライセンスキーと終了日(オプション)を受け取っている場合は、ダイアログボックスの該当するテキストボックスに情報を入力し、OKをクリックします。
さもなければ、以下のライセンスキー情報ファイル
C:\Program Files\NeuralWare\NeuralWorks\Predict\NW_License_ID.txt
をann@setsw.co.jpにEメールで送付してください。
上記情報を送信してから、ライセンスキーがあなたに届くのを待つ間、あなたはデモンストレーションモードでPredictを実行することができます。
このチュートリアルを続ける、または体験試用モードでPredictを実行し、他のデータに対して使う場合は、体験試用をクリックして下さい。
チュートリアルを続行しない場合やPredictを使用しない場合は、Excelに戻るをクリックして下さい。
Excelのメニューバーは、以下のようになっているはずです。アドイン」をクリックすると、「メニューコマンド」に「予測」メニューが表示されます。

Predictメニューが現れない場合、あるいは、この成功への道標の実施の間にサポートを必要とする場合は、製品サポートに連絡(e-mail: ann@setsw.co.jp)してください。
これから何をしようとするか?
このチュートリアルで読者が構築するモデルは、土から湿気蒸発の率を予測するモデルです。湿気蒸発率は、耕地が人工的に潅漑されなければならないかどうかの判断のための重要な指針です。しかし、潅漑するという決定は高価なものとなります-例えば、水を購入しなければなりません、ポンプを動かすため電気や燃料を購入しなければなりませんし、潅漑システムの監視とメンテナンスのため、さらなる人員が必要になるかも知れません。
同時に、耕地が潅漑されず、かんばつの損害を受けたならば、収穫量は減り、予想以下の収益となってしまいます。
明らかに、正確に湿気蒸発率を予測することができれば、利益率の高い収穫を行う可能性を大いに向上させることができます;正確なモデルが構築できれば、不必要な潅漑の回避を通して経費を最小とする助けとなります。
これから作成しようとするモデルは、非常に特別な問題領域におけるデータを使用しますが、このモデルを作成する理由は、事実上全てのモデル構築におけるお手本となると考えられるからです。正確な予想または分類は、正確でよりよい(より適切な)決断を確かにします―収益成長率を促進し、経費最小化し、あるいは単により正確になります(そのモデルが診断や発見を行う関数である場合)。
どのようにしてモデルを作るか?
モデルを構築する意義について理解したならば、あとは簡単です!読者が自身の解析課題に取り組むためのモデルを開発し始める際、全ての問題が必ずしも湿気蒸発問題ほど明確であるというわけではないことが分かるでしょう。しかし、一旦問題を設定したならば、Predictを用いて必要とするモデルを構築することはとても簡単です。
Excelファイルメニューから、開くをクリックしてください。そしてフォルダを移動して次のExcelシートを開いてください:
C:\Program Files\NeuralWare\NeuralWorks\Predict\evap.xls.
最初の6つの列は、計測条件値あるいは属性値です―土温度、相対湿度、風速等々。全ての行において、これらの6つの列の値は、複合した影響を最後の列(1日の蒸発率)の値に与える「独立変数」です。1日の蒸発率(従属変数)は、ニューラルネットワークモデルを学習するのに用いられる教師変数です。
最初に異なる名前でスプレッドシートを保存してから始めてください。
1. Excelファイルメニューから、名前をつけて保存をクリックして
ください。
2. ファイル名は”チュートリアル”とし、保存をクリックしてください。
次に、ExcelメニューバーのアドインタブのPredictメニューから、読者のニューラルネットワークモデルを作成し始めるために、新規をクリックしてください。
すると、新しいモデルダイアログボックスが現れます。
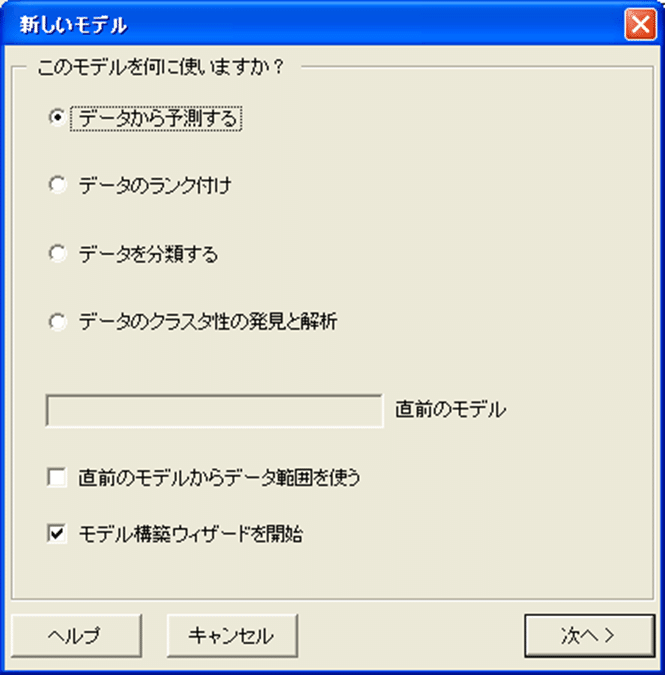
以前にも記載したように、湿気蒸発問題は予測問題に該当します。
1. データから予測するを選択してください。
2. モデル構築ウィザードを開始が選択されていることを確認してください。
3. 次へをクリックして続けてください。
あなたが初めてPredictを使ってモデルを構築する際には、モデル構築ウィザード挨拶ダイアログボックスが表示されます。
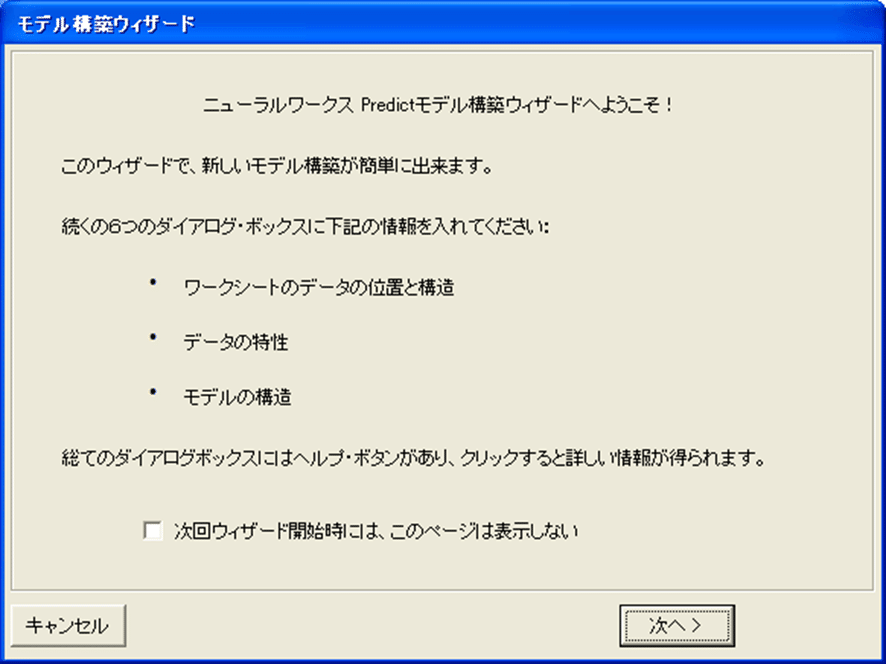
ダイアログボックスは、読者がモデルを作成する際に行うステップを示します。
1. 2度と挨拶ダイアログボックスを見たくないならば、チェックボックスを選択してください。
2. 次へをクリックして続けてください。
モデル構築-ステップ1
モデル構築(ステップ1の6)ダイアログボックスでは、あなたはモデルの要素名を指定します。
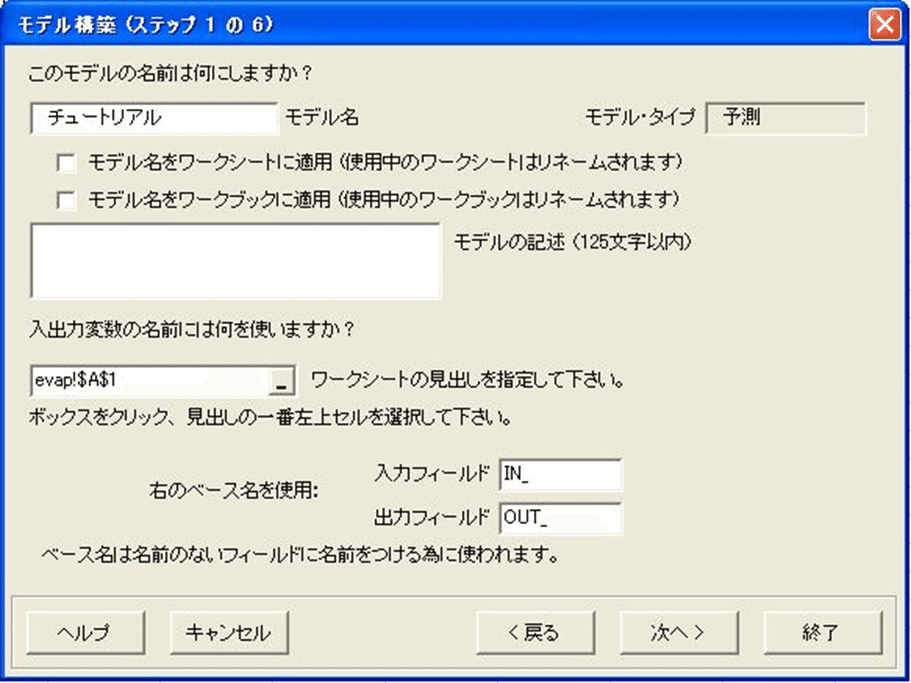
モデル自体がチュートリアルと名づけられることに注意してください。―Predictデフォルトは、スプレッドシート名を使用いたします。
次に、スプレッドシートのどの行がデータフィールドの名前(あるいは“ヘッダ群”)を含んでいるかを、Predictに指示します。
1. 入力変数の名前には何を使いますか?のラベルの下のテキストボックスをクリックして、それからA1セルをクリックしてください。
Predictは、ヘッダ行の位置で、自動的にテキストボックスを満たします。
2. 次へをクリックしてください。
モデル構築-ステップ2
このステップでは、スプレッドシート内の入力データの配列状態を、Predictに伝えます。スプレッドシートの各々の行には、個別のデータレコードがあるとします。

1. 最初の入力データ・レコードテキストボックスをクリックして、それからスプレッドシート上でマウスを動かして、A2セルからF2セル(必ずF2セルを含めてください)までドラッグしてください。
この操作により、最初のデータレコードの入力値がA2からF2であるとPredictに伝えることができます。
Predictが指定した範囲値で自動的にテキストボックスの値を満たしていることに注目してください。
2. 次に、2番目の入力データ・レコードテキストボックスをクリックし、そして、A3セル(2番目のレコードの最初のセルです)をクリックしてください。今度は、F3セルまでドラッグする必要はありません。PredictがF3セルで終わると自動的に判断します。
3. 最後に、全ての入力データテキストボックスをクリックし、スプレッドシートでA列のヘッダをクリックしてください。
この操作は全ての列を選んで、スプレッドシートの全てのレコードから入力値を使うようにPredictに指示します。
4. 次へをクリックしてください。
モデル構築-ステップ3
このステップでは、出力データ値(目標値)がスプレッドシートのどの範囲あるかについて、Predictに伝えます。出力値は、通常、入力値の右に続いています。
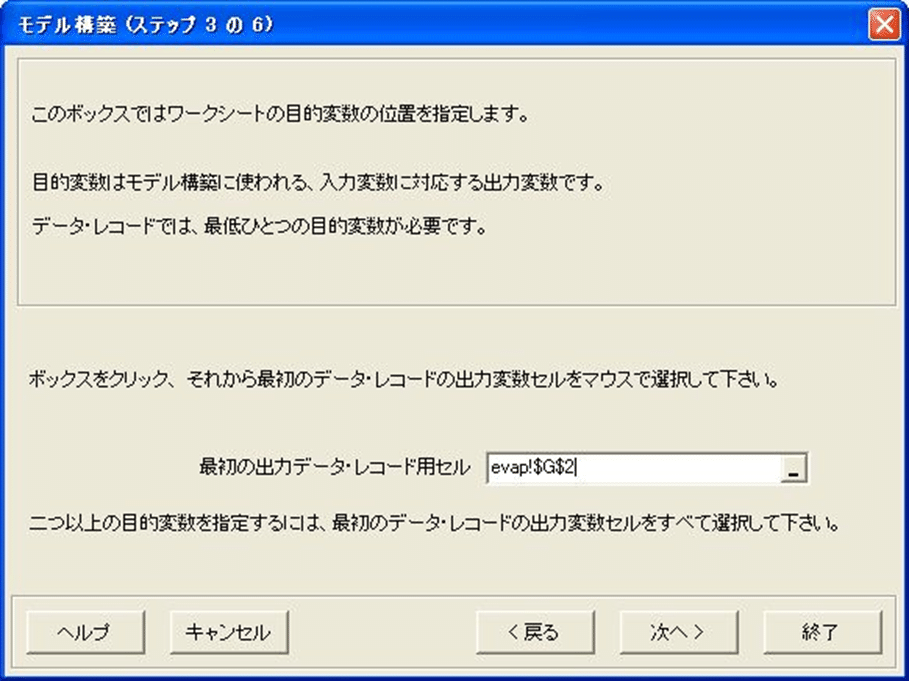
問題説明から、データの最後の列(1日の蒸発率)が、モデルが予測するための目標値であることを思い起こしてください。
1. テキストボックスをクリックし、G2セルをクリックして出力値の最初のレコードがどの位置であるかをPredictに伝えてください。
出力値の最初のデータレコードの位置を指定するだけでよいことに注意してください―Predictは、他の全てのデータレコードの入力値と出力値のフィールドのレイアウト関係から、そのフィールドのレイアウトを決定することができます。
2. 次へをクリックしてください。
モデル構築 - ステップ4
通常は、このダイアログボックスで、利用できるデータの特徴と、データがどのように変換(前処理)するかについて、Predictに伝えるオプションを検討し、選択します。
しかしなから、この成功への道標では、そのままデフォルト設定を選択します。

次へをクリックしてください。
モデル構築-ステップ5
通常はこのダイアログボックスで、入力フィールドがどのように分析されるべきか、また実際のニューラルネットワークがどのように構築されるべきかをPredictに伝えるオプションを検討して、選択します。
この設定も、この成功への道標ではデフォルトのままとします。

次へをクリックしてください。
モデル構築-ステップ6
このダイアログボックスは、前の5つのステップで行ったことの総括を示します。
ここでは、更なる選択を行う必要はありません。(<モデル構築(ステップ6の6)>ダイアログボックスが下の図がと同じようになっているか確認してください)。
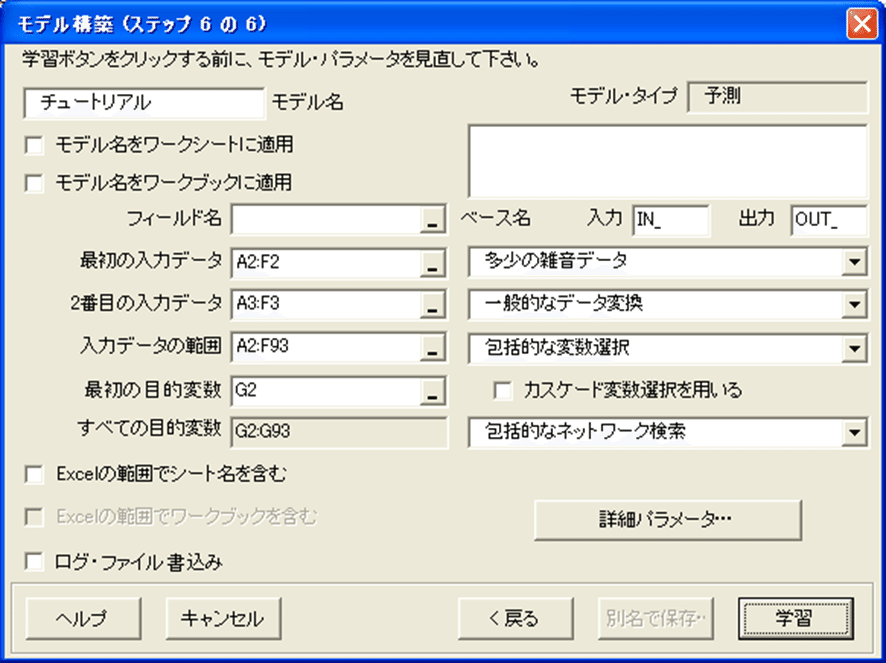
1. 学習をクリックしてください。
モデルを保存ダイアログボックスが現れます。しかし、あなたが体験試用ソフトウェアを使用している場合は、あなたのモデルは実際には保存されません。
2. 保存をクリックしてください。
モデル構築の進捗
モデルを保存ダイアログボックスを閉じた後、すぐにモデル構築進捗ダイアログボックスは現れます(非常に短時間だけです!)。
このダイアログボックスは、Predictが実行する主な工程(最初にモデル構築の準備を行い、そして実際にモデルを構築)の進捗状況を把握できます。

このチュートリアルの湿気蒸発率予測モデルでは、このダイアログボックスは数秒の間だけ見えます―そしてそれがモデル構築に要する全ての時間です!
このダイアログボックスは自動的に閉じます。
学習終了後
Predictの学習が完了したあと、そのモデルについての統計指標値のまとめとモデル構築に用いたデータに対してのパフォーマンス示すダイアログボックスが表示されます。ダイアログボックスの完全な説明はこの成功への道標では行いませんが、次の章では、あなたが構築するモデルの品質を評価するのに役立つさらなるPredictの機能を述べます。
およそ15分で、あなたが特定の問題を解決するためのロバストなニューラルネットワークモデルを構築するためにPredictを使えるようになったことに気づいてください―あなたは現在、Predictの力を用いて、あなた自身の領域のデータにおいてモデルを構築する能力を獲得しました。
おめでとうございます!
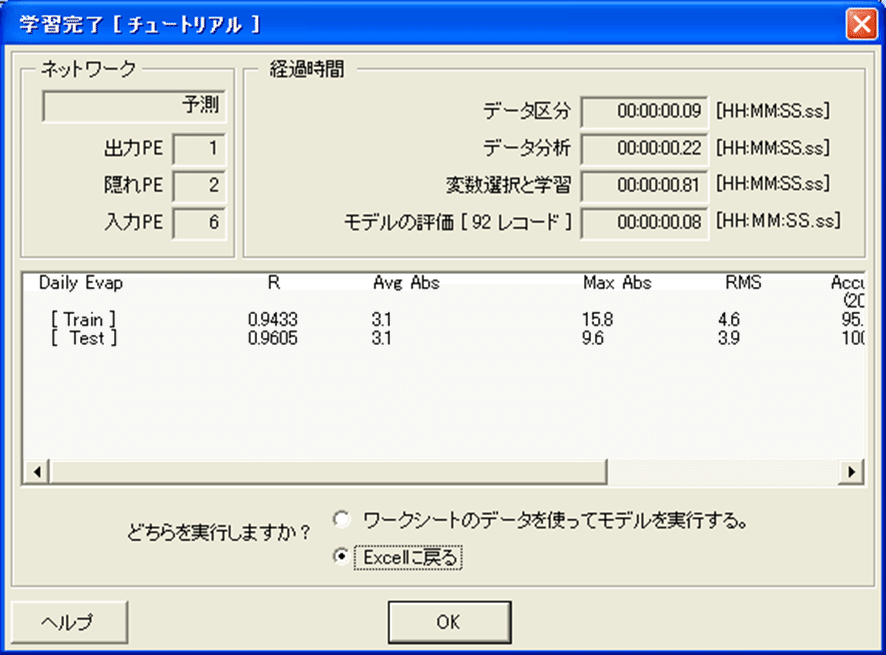
学習完了ダイアログボックスの情報を見終わったあと、Excelに戻るが選ばれていることを確認して、OKをクリックしてください。
ダイアログボックスが閉じた後、Excelスプレッドシートは、モデル構築前と厳密に同じように見えています。しかし、ExcelメニューバーのPredictメニューは、完成したモデルの名前を(下の図に示すような)示していることに注意してください:

モデルのテスト
モデルの品質を測る1つの方法は、それを学習するのに用いられるデータで、そのパフォーマンスに関連した基本的な統計量を計算することです。Predict のテストコマンドは、そのための統計量を計算出力します。
1. Predictメニューで、テストをクリックしてください。
結果範囲(一番左上セル)テキストボックスは、どこにテストコマンドの出力結果を書き始めるかを、Predictに伝えます。
2. テキストボックスをクリックして、I列の最初のセルをクリックしてください。(本来はどのセルを選んでもよく、選んだセルを先頭に結果は出力されます。)しかしながら、H列でクリックしないでください―次のセクションで、我々は他のモデル出力のためにH列を使いますので。

3. 以下のオプションが選択されていなければ、選択してください(そして他の選択されている項目をクリアしてください):
・ 入力データの範囲
・ 学習セット
・ テストセット
4. テストをクリックしてください。
Predictはあなたが上で選んだオプションと関連するデータレコードをモデルに渡して、スプレッドシートに統計値をあなたが指定したセルから書き込みます。
5. 閉じるをクリックしてダイアログボックスを閉じてください。
テスト結果の解釈
テストコマンドは、下の図で示すような性能測定基準表を生成します。(あなたのtutorialスプレッドシートに書かれる値は、これらと同様であるはずです)

予測モデルのために最も重要で役に立つ測定基準は、通常はR(ピアソンのR)値、RMS(平均2乗)誤差とAvg. Abs誤差(平均絶対誤差)です。ときにはMax. Abs.誤差(最大絶対誤差)が重要であることもあります。
どの測定基準に頼るべきか決めることは重要で、ある程度問題に依存します。この成功への道標のガイドでは、パフォーマンス測定基準について簡潔に説明するのみに留めたいと思います。Predictにはモデルを評価するのを助け、モデルの性能を改善するための広範囲で強力な機能があります―それらは製品版のPredict に付属のPredictユーザガイドで詳しく解説されています。
R値とRMS誤差はデータ群がもう一つにどれほど“近い”ものであるかを示します-今回のケースでは、学習目標値(実際の値)とモデルが生成した予測値がどの程度近いかどうかです。
R値は、-1.0から+1.0までの値をとります。R値の(絶対値が)大きい程、2つのデータにはより強い相互関係があるといえます。R値の符号は、相互関係が正相関(1つのデータの値が増加すると、もう一方のデータの値も増加する)であるか、逆相関(1つのデータの値が増加すると、もう一方のデータの値は減少します)であるかを示します。R値が0.0ならば、2つのデータ群に相互関係がないことを意味します。一般に正の値で大きいR値(1に近い値)は、“より良い”モデルを示します。
RMS誤差は、対応する2つのデータ群の組の値の間の誤差の尺度です。RMS値は、値が小さいほどよいといえます。
最後に、性能測定基準を見る際の鍵は、同じ種類の統計値を異なるデータセットで比較することです。上の表のハイライトされたTrainとTestセットのR値に注目してください。値の差が比較的小さい(0.9432と0.9604)ことは、モデルがよく一般化されていて、そして、それが新しいデータ(学習またはテストデータセットから得られないデータ)を処理するときにも、正確な予測をするであろうことを示唆します。
過去データでのモデルの実行
統計値の概要と性能測定基準を計算するためにテストコマンドを使うことに加えて、あなたは過去データ(モデル構築データ)の全てで、モデルを実行することができます。これにより学習目標値と予測値の値を比較することができます。それらの値は、簡単にグラフにプロットすることができ、モデルの品質の目安を視覚的にすばやく得ることができます。
1. Predictメニューから、実行をクリックしてください。
モデルを実行ダイアログボックスが表示されます。デフォルトでは、入力データの範囲テキストボックスは、学習に用いたオリジナルの入力データを含むExcelの範囲にセットされています。
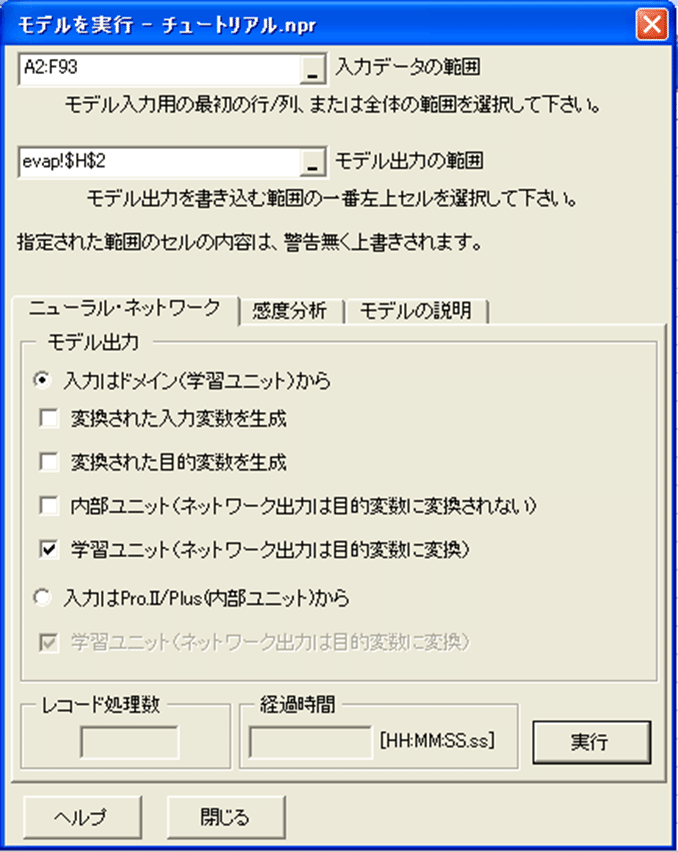
2. 必要であれば、モデルを実行ダイアログボックスをExcelのH2セルが見えるように動かしてして下さい。
3. モデル出力の範囲テキストボックスをクリックし、そのあとH2セルをクリックしてください。
この操作により、モデルの予測値をどこに書くかをPredictに伝えます。モデル出力の範囲でH2セルを指定すれば、予測値と実際の値(学習目標値)をとなりに表示できるので、比較が簡単になります。
4. 実行をクリックして下さい。
5. データがスプレッドシートに書かれたあと、閉じるをクリックしてください。
実際の値(学習目標値)とモデルの予測値をスプレッドシート上に並べて表示できたので、モデルの品質を視覚的に評価するためのExcelグラフを作成することは簡単です。
1. 最初に、G列とH列の全てのデータを選択ください。
2. Excelバージョンが2007以前の場合には、Excel の挿入メニューから、グラフをクリックしてください。
グラフウィザードダイアログボックスが表示されます:

3. グラフの種類リストでは、折れ線を選んでください。
4. 完了をクリックしてください。
5. Excel2007以降の場合には、Excelの挿入メニューから折れ線をクリックして、マーカー付き折れ線を選択してください。

予測値(ピンク)と学習目標値(ダークブルー)どれぐらい近いかを、Excelグラフが表示します。

新しいデータでのモデル実行
もちろん、どんなモデルを構築する際にも、その目的は新しいレコードの値に対し正確な予測値を算出することです。
以下の数回の操作は、新しいデータに対してPredictモデルを実行する為の簡単なデモです。ただし、まず必要なのは”新しい”データレコードです。
1. 以下の6個の数値(蒸発率予測モデルのための6個の入力値)を、A95セルからF95セルに追加してください(それらのセルはオリジナルデータの下にあります):
100 150 200 50 400 400 (スプレッドシートに最後の数値をタイプしたあと、エンターキーまたはタブキーを押してください)
2. Predictメニューから、実行をクリックしてください。
モデルを実行ダイアログボックスが再び現れます。しかし、今度は2つのテキストボックス中のデフォルトの範囲を書き換える必要があります。
3. 入力データの範囲テキストボックス内をハイライトするようにマウスをドラッグし、その後A95セルをクリックしてください。
4. 次に、モデル出力の範囲テキストボックスの内容をハイライトするために、マウスをドラッグして、H95セルをクリックしてください。
これらのステップを完了したとき、モデルを実行ダイアログボックスは下のように表示されているはずです; あなたが入力した2つの範囲が正しいかどうかを確認してください。

5. 実行をしてください。
6. 閉じるをクリックしてください。
あなたが入力した新しいデータについての予測値(52.186981)が、H95セルに表示されています。
おめでとうございます! あなたは、この成功への道標を正しく完了しました!
Predictメニューで、閉じるをクリックしてモデルを閉じてください。
必要であれば、後の参考のために、Predictのテストコマンドの結果とモデルの予測値のスプレッドシートを保存することができます。Excelファイルメニューから、保存をクリックしてください。
このチュートリアルの総括
成功への道標を終了して、あなたは土から湿気蒸発率を正確に予測するニューラルネットワークモデルを実際に作成して、評価することができました。
これを達成するにあたって、読者は:
・モデルを構築するための過去データを読み込むためにExcelを用いました;
・Predictにニューラルネットワーク予測モデルを構築する設定をしました;
・過去データを用いてモデルを学習しました;
・モデルの性能をテストし、スプレッドシートに結果を記録しました;
・過去データを用いてモデルを実行し、モデルの予測値と実際の学習目標値を比較しました;そして
・新しいデータを用いてモデルを実行し、初見のデータに対する予測値を生成しました。
しかしながら、あなたはPredictの威力の一部分に触れただけであるということを心に留めておいてください!
あなたが実施できることははるかにたくさんあり、それらをあなた自身のモデル化問題に適用することができます。例えば;
・ロバストな一般性を保証するために、学習、テストセットと独立した確認データセットにデータを分離すること。
・モデル構築の為の数値のより良い分布を実現するために、Predictの包括的なデータ変換機能を使うこと。
・遺伝的アルゴリズムに基づくPredictの強力な変数選択メカニズムで、ニューラルネットワークモデルを構築する際に使用する最も重要なフィールドを特定すること。
・感度分析グラフや、最終的なニューラルネットワークの構造やPE重みに関する情報等の詳細な情報等を確認すること。
次のステップは?
我々は、もちろん読者がPredictの威力を完全に確信していて、購入する準備ができていることを望んでいます!
もしそうであれば、以下へ注文してください
電話:06-6232-3350 (SETソフトウェア(株)関西システム本部ニューラルワークス製品販売担当)
Eメール:ann@setsw.co.jp
ガイド『使い始めにあたって(Getting Started Guide)』によって、Predictとその強力な機能についてより多くを学ぶことができます。
読者はWindowsのスタートメニューから使い始めにあたってを直接開くことができます。すべてのプログラム-> NeuralWare -> NeuralWorks -> Predict -> Getting Started Guide。
『使い始めにあたって(Getting Started Guide)』には、異なる種類のモデルやデータ(定性データを含むデータ)についての追加のチュートリアルがあります。信用リスク管理に関連した一連のモデル開発の練習問題があります。
読者自身のデータでPredictを用いることを推奨します。我々は、読者がごくわずかな労力でExcelスプレッドシートにデータをインポートして、ほんの数分で基礎モデルを作ることができると確信しています。そして、あなたがデモ版の規制による問題点を感じるようになったとき、我々は読者がPredict製品版に移行するのをお手伝いする準備をしています。
最後に、Predictに関する質問がある場合や、あなた自身の問題においてどのようにモデルを構築すべきかについてのご相談がございましたら、ニューラルウェア製品サポートにお問い合わせください;
電話:06-6232-3350 (SETソフトウェア(株)関西システム本部ニューラルワークス製品製品サポート担当)
Eメール:ann@setsw.co.jp
成功への道標を読んで頂きありがとうございました。そして、我々は読者自身のモデル解析プロジェクトをお助けできる機会を楽しみにしています。
用語集
以下の用語は、ニューラルコンピューティングにおいて多用されます。
R値-ピアソンRとしても知られています。2つの変数間の線形関係の測定基準で、-1.0から+1.0の範囲の値を取ります。完全な逆相関関係は-1.0、相関性がまったくない場合は0、完璧な相関関係は+1.0で示されます。
過学習-過学習はモデルの学習でできるマッピング関数が学習セットに合いすぎてしまうときに起こります。過学習したモデルは、学習セットには無い新しいデータにうまく適応できないので、汎化性を持ちません。
学習-繰り返し過去データのレコードをニューラル・ネットワークに通し、学習ルールに基き、結合の重み及びネットワークの他のパラメータを変える処理。
Predictでは、モデル用データを使ってネットワークを学習する際、目標値とネットワーク予測値の差を最小にするためにニューラルネットワークの重みが繰り返し調節され、プロセシング・エレメントが加えられます。学習済みのネットワークもまた、学習を特徴づけます。
学習セット-ニューラル・ネットワークの学習に使用される、過去データの部分集合。(重みを調節させ、またいくつかのケースではプロセシング・エレメントを追加させます。)
学習ルール-学習中にモデルを数学的に改修するためのアルゴリズム。
過去データ-適用領域から集められた、モデルの構築に使われるデータ。通常、データは入力変数の後に出力変数(複数)が続くレコード群として行をなしてまとめられています。過去データは学習、テスト、及び確認セットに分けられます。学習及びテストセットはモデルの構築に使われるモデルデータと呼ばれます。ニューラルネットワークはこのデータを入力変数と出力変数の関係を学習すること(すなわち入力セットから出力セットへ写像する関数を作ること)に使います。真の確認セットはモデルデータと完全に異なっていて、独立にモデルの性能を評価するために用いられます。
雑音-データのクリーンさ、または一貫性の程度。入力データの雑音は通常測定の誤差から起こります。雑音は利用可能な入力から予測できないかあるいは入力にかかわらず本質的に予測不能である、目標値における誤差とも言えます。様々なタイプのデータについて典型的な雑音レベルを以下に挙げます。:数学関数から生成されるデータはクリーンなデータです; 行動に関するデータは一般に“一般的な”雑音データです; 証券データ(株価や利率等)は非常に雑音があります。
信頼区間 (%)-この区間は指定された信頼度に対応する範囲内[目標値±信頼区間]に予測結果を出す頻度を定めます。
正確度 (%)-目標値に対するユーザーが指定する許容値内にある予測結果の割合。
線形相関値-R値の項目を参照してください。
相関係数-R値の項目を参照してください。
テストセット-ネットワーク構造の組み立てや過学習を避けるためにニューラルネットワークの学習中に利用される過去データの部分集合です。学習中、定期的にネットワークがテストセットのデータで実行され、その性能が得点化されます。この得点はニューラル・ネットワーク自体が組み立てられているとき候補となる隠れノード間の選択と、いつネットワークの学習を終了するか決定するのに使用されます。(テストセット及び確認セットの違いについての詳細説明はニューラルワークスPredictユーザーガイドの「学習、テスト、及び確認セット」の章を参照してください)。
テスト-過去データにある入力を使って、ニューラル・ネットワークを実行し、過去データの出力(目標値)とネットワーク出力を比較して正確さを評価すること。目標値に関係している入力を含むどんなデータセットを使っても、ニューラルネットワークをテストすることができ、様々な測定基準の表が作られ、評価することができます。Predictのモデルが学習中のとき、定期的に学習は遮断され、そのときのモデルはテストセットでテストされます。
Net-R-内部スケール変換された目標値と生のネットワーク出力の線形相関。
ネットワーク出力-生のネットワークの出力とも呼ばれます。過去(問題領域)データの測定単位に対応する変換が実施される前のニューラルネットワークの出力。ネットワーク出力値は-1~1、または0~1の範囲にあります。ネットワーク出力は測定単位に変換されて予測値が生成されます。
ニューラルコンピューティング-情報(データレコードによる学習)によって適合されていく、プロセシング・エレメントと呼ばれる多くの単一ユニットによって構成されるネットワークの学問。ニューラルコンピューティングは機械学習の分岐のひとつであり、経験的なデータからのモデル化手法です。
入力変数-モデルのための入力変数。ニューラルネットワークモデルの出力は入力された変数の非線形関数です。入力変数はその関数の中での独立変数です。
汎化-モデルの学習に使われたデータと異なる入力データを使う時、適切な出力結果を出すモデルの能力。ニューラル・ネットワークモデルに対して、ニューラル・ネットワークが学習した過去レコード(入出力両方の値を含む)から外挿されることで作られます。うまく汎化していないモデルはしばしば学習データに対してモデルが過学習となっています。
平均絶対誤差 (Avg. Abs)-予測結果とそれに対する目標値との絶対誤差の平均。
平均二乗(RMS)誤差-学習中のネットワーク精度の測定基準。目標値及び対応する予測出力との平均二乗誤差の平方根。
目標値-過去データ中にあり、ある入力変数例に対し実際に記録された値。ネットワークが予測しようとする値。
モデリングデータ-ニューラルネットワークモデルを構築することに使われる過去データの部分集合。これは学習セットとテストセットを含みます。
モデル-一般的に、モデルはシステムを理解しあるいはコントロールするための数学的な表現です。ニューラルコンピューティングの文脈では、モデルの構築は中核となるニューラル・ネットワークを定義し、学習するだけでなく出力または入力値に基づいた出力を算出するために、関連した前後の処理段階すべてを行うことを指します。
予測出力-適用領域の測定単位に変換された後のニューラル・ネットワークの出力。(ネットワーク出力と目標値の項目を参照してください)。
弊社では、データ分析プロジェクトにまつわる様々なご相談に、過去20年以上に渡るプロジェクト経験に基づき、ご支援しています。
社内セミナーの企画等、お気軽にご相談いただければ幸いです。
この記事が気に入ったらサポートをしてみませんか?