
【Python】SDK for Python3を使ってみた。

Evernote SDK for Python3
今回は下記の記事を参考にしました。実行環境はMacで行っています。
下準備
pip install evernote3==1.25.14pip install oauth2上記2つをインストールします。
本スクリプト
from datetime import datetime, timezone, timedelta
# Evernote SDK for Python 3 を使う
from evernote.api.client import EvernoteClient
from evernote.edam.notestore.ttypes import NoteFilter, NotesMetadataResultSpec
#CSVを作成するための記述
import os
import csv
os.chdir(r"/Users/**************/Downloads")
print(f'CSVファイルのダウンロード先:{os.getcwd()}')
values = []
# evernote.api.client.EvernoteClient を初期化
client = EvernoteClient(
token = '******************************************', # アクセストークンを指定
sandbox = False # Sandbox ではなく Production 環境を使う場合は明示的に False を指定
)
# evernote.api.client.Store を取得
store = client.get_note_store()
# ノートブック evernote.edam.type.ttypes.Notebook のリストを取得
notebook_list = store.listNotebooks()
print(f'ノートブックの数: {len(notebook_list)}')
# evernote.edam.type.ttypes.Notebook を取り出す
for notebook in notebook_list:
notebook_name = notebook.name
# 取得するノートの条件を指定
filter = NoteFilter()
filter.notebookGuid = notebook.guid # ノートブックの GUID を指定
# NoteMetadata に含めるフィールドを設定
spec = NotesMetadataResultSpec()
spec.includeTitle = True
spec.includeCreated = True
spec.includeAttributes = True
# ノートのメタデータのリスト evernote.edam.notestore.ttypes.NotesMetadataList を取得
notes_metadata_list = store.findNotesMetadata(
filter,
0, # offset 条件にヒットした一覧から取得したいインデックス位置を指定
1, # maxNotes 取得するノート数の最大値。今回は最大で1つだけ取得する
spec)
#空の配列にノートブック名とノート数を書き込む
print(f' {notebook_name} ({notes_metadata_list.totalNotes})')
values.append([notebook_name, notes_metadata_list.totalNotes])
with open('Evernote_API.csv', 'w') as file:
writer = csv.writer(file, lineterminator='\n')
writer.writerows(values)
file.close()呼び出し回数が多いとエラーが出る
呼び出し回数が多いと下記のエラーがでます。
EDAMSystemException: EDAMSystemException(message=None, errorCode=19, rateLimitDuration=2544)
2544 / 60 = 42.4(分)!?
40分くらい呼び出しを制限されてしまいます。
# ノートのメタデータのリスト evernote.edam.notestore.ttypes.NotesMetadataList を取得
notes_metadata_list = store.findNotesMetadata(
filter,
0, # offset 条件にヒットした一覧から取得したいインデックス位置を指定
len(notebook), # maxNotes ノート数分取得する
spec)自分の場合は10年ほど前からEvernoteを使っているヘビーユーザーなので総ノート数は、12,500ほど。ノートブックタイトルを取得するだけで精一杯でした。250回くらいループするとエラーが出てしまいます。
This exception is thrown by EDAM procedures when a call fails as a result of a problem in the service that could not be changed through caller action. errorCode: The numeric code indicating the type of error that occurred. must be one of the values of EDAMErrorCode. message: This may contain additional information about the error rateLimitDuration: Indicates the minimum number of seconds that an application should expect subsequent API calls for this user to fail. The application should not retry API requests for the user until at least this many seconds have passed. Present only when errorCode is RATE_LIMIT_REACHED,
この例外は、呼び出し元の操作によって変更できなかったサービスの問題の結果として呼び出しが失敗したときに、EDAM手続きによってスローされます。発生したエラーの種類を示す数値コード。EDAMErrorCodeの値のいずれかでなければならない。message: これはエラーに関する追加情報を含むことができる rateLimitDuration: アプリケーションが、このユーザーに対する後続のAPI呼び出しが失敗することを予期すべき最小の秒数を示す。アプリケーションは、少なくともこの秒数が経過するまでは、このユーザーに対するAPIリクエストを再試行しないようにする必要があります。errorCode が RATE_LIMIT_REACHED のときのみ存在する。
今後の課題として
noteIDなどユニークな値もしくは、タイトルを引数で渡して、特定のノート内容を取得することが出来ないのか?調べる
負荷を分散するようなプログラムが書けないか調べる
ノートブック内のノートのリストを取得するには?

ノートをエクスポートする
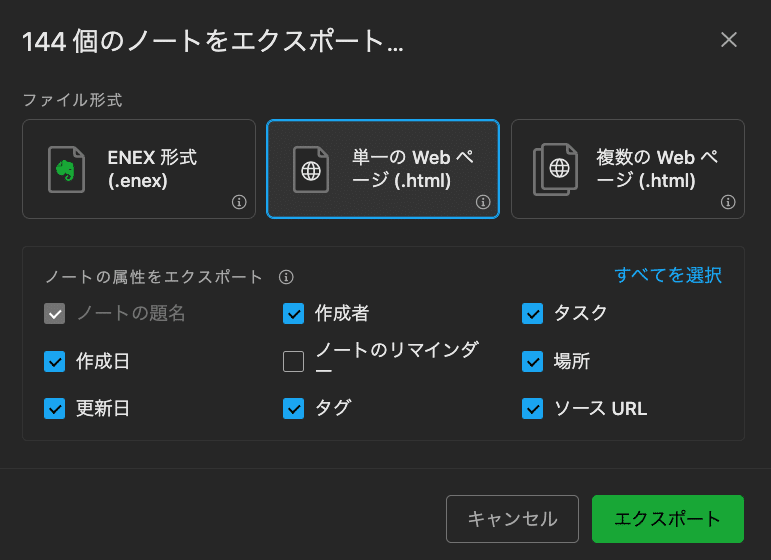
csvでエクスポート出来ればいいんですけどね.....。
上述したように250回前後でエラーが起きてしまうため、ローカルにhtmlファイル形式でデータをダウンロードして、そのファイルからタイトルや投稿日時を取得する方法へ改めました。
ウエブページをスクレイピングでタイトルと投稿日時を取得します。
import os
import csv
os.chdir(r"/Users/********/Downloads/")
print(f'取得先フォルダ: {os.getcwd()}')
values = []
from bs4 import BeautifulSoup
with open('001_ロゴデザイン.html', encoding='utf-8') as file:
html = file.read()
soup = BeautifulSoup(html, 'html.parser')
elems_title = soup.find_all("meta",attrs={"itemprop":"title"})
elems_time = soup.find_all("meta",attrs={"itemprop":"created"})
print(f'全ノート数: {len(elems_title)}')
title = ['ノート名']
time = ['投稿日時 (グリニッジ標準時)'] #投稿日時が日本の場合は、9時間差
for elem_title ,elem_time in zip (elems_title, elems_time):
title.append(elem_title["content"])
time.append(elem_time["content"])
values = [list(e) for e in zip(title, time)]
with open('Evernote_note_contents.csv', 'w') as file:
writer = csv.writer(file, lineterminator='\n')
writer.writerows(values)
file.close()こういう書き方があるよと教わって書いたコード。
意味を理解して使っていないため、理解をするのが当面の目標
この記事が気に入ったらサポートをしてみませんか?