
2014年から稼働しているSolrをアップグレードした話

この記事は、NAVITIME JAPAN Advent Calendar 2020、4日目の記事です。
こんにちは。見習いスパルタ人1号です。ナビタイムジャパンで地点検索基盤の開発を担当しています。
当社では地点検索に利用する検索エンジンとして主に Apache Solr を利用していますが、2014年に Solr を採用して以降、マイナーバージョンの更新はあったもののメジャーバージョンのアップグレードがなされていない状態でした。
長年アップグレードしたくともなかなか取りかかれない状況でしたが、今年度に Solr 6系 にアップグレードを行いました。今回はその経験と、アップグレードから得られた知見について書いていこうと思います。
難しいことは特にしていないため、いきなりの飛躍は難しい…! という方の参考になれば幸いです。
忙しい人のための知見まとめ
・開発フローもアップグレードして効率化する
・「やるべきこと」を積み重ねれば難しくはない
・セオリーの積み重ねで圧倒的な改善ができる
・ShingleFilterには気をつけよう
Why Solr6?
本記事を公開している2020年12月現在、Solrの最新版は Solr 8.7.0 です。なのに何故、Solr 6 に移行したのでしょうか。そこには2つ理由がありました。
1. スコア計算
Solr 6 を利用する最大の理由はスコア計算ロジックにありました。今回アップグレードしたSolrには約1000万件の地点情報が投入されています。 検索技術勉強会での発表 でも解説されている通り、当社では一般的な検索指標とは別に有名度と距離によって検索結果を調整しています。そのため、schema.xmlの変更だけでは互換性を維持できないことが分かっていました。

公式ドキュメント でも周知されている通り、Solr6 からはマッチングスコア計算に Okapi BM25 をデフォルトで利用するようになりました。過去に NTTドコモ様がSolr勉強会で報告 されているように、Okapi BM25 ではマッチングスコアの値に大きな変更が発生します。そのため一旦は旧来のスコア計算手法である ClassicSimilarity を明示的に利用し、Solr6 で安定稼働を確認してから Okapi BM25 をベースにしたチューニングを施し、その後でより新しいSolr にアップグレードする戦略を立てました。
2. 開発フローの見直し
2つ目の理由として、開発フローの見直しが必要でした。2014年に Solr を採用した時よりも Solr の利用範囲が広がり、開発効率の悪い部分が多々発生していました。
当社では施設や駅などのマスタデータに対してコンバータプログラムで処理してから Solr にデータを投入していますが、検索用に部分文字列を生成するロジック(※)は複数のリポジトリにコピペされているなど、検索改善の取り組みを全体に波及させることが難しい状態となっていました。
※「東京」を「とうky」でヒットさせるような処理は Solr だけではなかなか実現できないため、データコンバータでの処理を行っています。

当社ではオンプレ環境とクラウド環境で Solr を運用していますが、大まかには以下のような構成となっています。参照系はオンプレ環境では物理マシン上で Solr を稼働させており、クラウド環境では k8s を利用してコンテナ化しています。

対応内容の詳細は後述しますが、アップグレードを契機として開発フローを見直し、開発効率を上げた状態でアップグレードのノウハウを蓄積したいというモチベーションを持って対応を進めました。
開発フローもアップグレードして効率化する
前述の通り、Solr に関連する開発では非効率な部分が多々発生していました。発生していた課題を大きく分けると、3つに分かれます。
データ投入に関わるコードベースが古く、メンテナンスしにくい
データコンバータは主に Java / Kotlin / Python で作られていますが、特にPython 製コンバータの設計が古くメンテナンスしにくい状態となっていました。上述したように、コピペされたコードが複数のリポジトリに散在しているような状況もありました。
設定ファイル更新とデータ投入コンバータの更新が分かれていない
主に Java / Kotlin 製コンバータで顕著でしたが、少しスキーマ設定を変更したいような場合でも逐一ビルドが必要となっており、開発速度が低下する要因となっていました。
開発に実機が必要で、開発環境のポータビリティが低い
独自コンポーネントを利用している箇所があったり、構築手順が明文化されていなかったりすることで実機でしか Solr を起動できず、開発者の手元で実験や開発ができない状態でした。
これらの問題を解決するべく、以下の方針で改善を行いつつ、アップグレードを実施しました。
1. データ投入に関わるコアなコードをメンテナンスしやすくする
同じような処理はライブラリ化し、コピペでの拡散を抑止するとともに開発効率を上げることを意識しました。Python が得意なエンジニアのレビューを受けつつ、メンテナビリティとポータビリティの高いライブラリを実装することを目指しました。
Poetry を利用することで、パッケージングと CLI ツールの作成が非常に楽になりました。また、Click が CLI ツールの作成において強力なツールとなっています。
以下のようなコードで簡単にCLIツールの追加ができ、テストも簡単に実装することができます。
# pyproject.toml
[tool.poetry.scripts]
sample-cli = "ntjsample.cli.sample_cli:main# ntjsample/cli/sample_cli.py
from typing import Collection
from click import command, argument, option, version_option
from . import __VERSION__
@command()
@argument('args', nargs=-1)
@option('-t', '--timeout', default=1800, type=int)
@version_option(__VERSION__)
def main(
args: Collection[str],
timeout: int,
) -> None:
try:
some_func(args, timeout)
except Exception as err:
LOGGER.error(str(err))
exit(1)# tests/cli/test_sample_cli.py
from unittest.mock import ANY, call
from click.testing import CliRunner
from ntjsample.cli.sample_cli import main
PKG = 'ntjsample.cli.sample_cli'
def test_fails(mocker):
some = mocker.patch(f'{PKG}.some_func', side_effect=RuntimeError)
result = CliRunner().invoke(main, [
's1',
's2',
'-t',
'600',
])
assert result.exit_code == 1
some.assert_called_once_with(
['s1', 's2'],
600
) 2. 設定ファイル更新の分離で安全性とベロシティを上げる
Solr6 への移行を契機に、Schema API / Config API を積極的に利用することにしました。これまではXMLファイルを設置することで設定を更新していましたが、リロード忘れが障害に発展したこともあるため、これらのAPIの採用により必ず変更がロードされる状態を作り出すことに成功しました。また、ビルドを不要にして開発速度を上げることも意識しています。
3. 開発環境のポータビリティを上げる
コンテナ技術の駆使と構築手順のコード化により、開発者の手元でもSolrを起動可能な状態を目指しました。
実際に運用されている環境では異なる部分がありますが、ローカルでの開発環境は以下のようなコンテナ構成をとり、各モジュールの動きを確認していきました。

データコンバータについてはデータセットの大きさから、今回はローカルに設置することを諦めましたが、いずれチャレンジしたいところです。
「やるべきこと」を積み重ねれば難しくはない
上記の方針は一見すると難しそうに見えますが、一つ一つの対応を丁寧に、やるべきことを積み重ねていけば大変ではあるものの難易度の高いものではなかったというのが実感です。
大きな変更を伴うメジャーバージョンアップグレードしようとなると特別なことをしなければならないような気がしてしまいますが、課題を分割していけば一つ一つの対応は決して難しくもなく、特別でもないものが大半でした。
課題を進めるにあたって意識したことは以下の4点です。
1. 自動化すべきところは自動化する
手作業はついつい横着したくなるものです。横着することでコード化やドキュメント化から漏れる処理が発生し、運用フローが複雑になり属人化しがちになります。これを防ぐため、可能な限り自動化、コード化を進めました。
今回自動化したものは以下になります。
1. Solr4の設定ファイル(XML)をSchema API / Config APIで送信する形式に近いYAMLファイルに変換する
2. YAMLファイルを読み込んでSolrにSchema API / Config APIで送信する
3. docker-compose で Solr / Envoy / Prometheus / Grafana を起動する
4. 旧Solrと新Solrの検索差分チェック
当社では施設情報以外に駅検索などでもSolrを利用していますが、1〜3の処理を自動化することで他のリポジトリでも容易に、Solrについて最低限の知識のあるチームメンバーなら誰でもマイグレーションができるようになっています。
2. 冪等性をなるべく確保する
YAML->Schema API にわざわざ変換している理由にも関わるのですが、Schema API ではフィールドタイプ等の追加と更新は別の操作となります。当社ではマスタデータからダンプしたデータを検索する関係で全更新している例がほとんどなため、Upsertしても大きな問題はないことから、自前のUpsert機能を持たせています。
# upsert.py (擬似コードです. 実際のコードではエラーハンドリングをしています)
def ensure_field_type(
basepath: str,
field_type: FieldType,
):
endpoint = f"{basepath}/schema/fieldtypes/{field_type.name}"
url_params = {
'wt': 'json'
}
field_type = requests.get(endpoint, params=url_params).json()
if field_type['responseHeader']['status'] == 404:
action = 'add-field-type'
else:
action = 'replace-field-type'
send_data = {
action: field_type.todict()
}
posted = _post_schema(basepath, core, send_data)この結果、処理が冪等になり、移行検証においてサーバの状態をあまり気にせず作業することができるようになりました。
3. コンテナ技術を駆使する
開発環境を docker-compose で構築できるようにしたことで、開発者の手元での検証が容易になったことは先に述べました。コンテナ利用は様々な恩恵がありますが、その中でも特に大きなメリットは「各モジュールの最小構成がわかる」「k8s化する際の指針となる」の2点でしょう。
当社では運用コストの関係上、データコンバータとSolrマスタサーバが同じインスタンスに設置されています。しかし、開発環境をコンテナ化するのであればこの2つは別のコンテナに設置すべきであり、設計思想も「同じインスタンス上に存在することを前提としない」という意識を自然と持つことができます。そのため、各サブシステムをなるべく疎結合にするモチベーションが高まりました。
「どこが疎結合にできるか」を見極める上でもコンテナ化による開発環境構築は大事だと実感しています。
また、 昨年度のアドベントカレンダーでも紹介した参照系のk8s化 においても威力を発揮し、コンテナの分割粒度は docker-compose と大きく変えることなく Solr6 への移行ができました。構築やコンテナ周りでは手戻りによりインフラチームに手間をかけさせてしまうことがありがちでしたが、事前にある程度実運用を想定しながら開発できたおかげでオーバーヘッドがかなり改善された(と信じています)
4. 可視化する
Solr6からは Prometheus Exporter が使えるようになり、Prometheus / Grafana による可視化が可能になりました。リクエスト数や平均レスポンスタイムは今までも取得していましたが、Solr自体のメトリクスからGCやキャッシュの利用状況なども取得できるようになり、実環境でどのように負荷がかかっているのかより見やすくなりました。
これにより、一台あたりの処理能力などが正確に見積もれるようになり、より適切なインスタンスタイプ選択とコスト削減ができるようになりました。

セオリーの積み重ねで圧倒的な改善ができる
上記の方針で3月から開発を始め、10月にオンプレミス環境とクラウド環境の両方で切り替えが完了しました。その間も継続的な検索改善は進めており、Solrアップグレード以外の業務が完全に止まった期間は最初期の設計段階と実際の切り替え作業前後以外ではありませんでした。
※当社では利用用途ごとにクラスタが分かれており、合計7クラスタを置き換えています。
詰まった点としては独自コンポーネントを利用していた箇所ですが、幸い組み込み機能の組み合わせで実現できることが分かり、当該機能を利用しているAPIサーバの改修を行うことで独自コンポーネントへの依存をなくすことができました。
7月までは上述の部分を除けば順調に進んでいたのですが、ロングラン試験をしていたところレスポンス速度が従来より100msほど悪化する問題があり、この解消に1ヶ月ほどを要しました。
ちょうど ZOZOテクノロジーズ様のブログ でも取り上げられていましたが、当社でもタイムスタンプをもとにした絞り込みをしており、調査の結果この処理が大きなボトルネックとなっていることが判明しました。そのため、当社でも時刻の丸め込み処理を入れることで高速化できました。
当該ブログは8月に公開されていますが、この記事が出た頃にはこの問題は無事に解決していたため「Luceneベースであれば一般的に効くチューニングなのだな」と感じました。当社の場合、絞り込み対象のフィールドではTrieDateField を利用していたため、丸め込みで高速化できるのは確かに理に適っています。
他にもクエリキャッシュなどの見直しを行い、最終的に検索APIの平均レスポンスタイムが200msから50msまで削減されました。また、1台あたりの処理能力も大きく向上し、サーバ台数を元々の4割ほどに削減することができました。
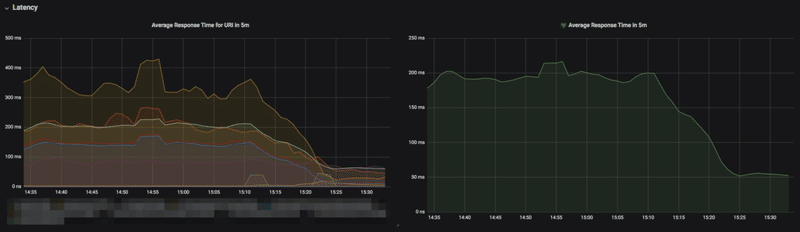
一つ一つの対応はセオリー通りですが、積み重ねることで大きな成果を出すことができることが示せたのではないかと思っています。開発フローを大幅に効率化したことで新規のSolrを6または8で素早く構築できるようになり、チームの生産性が大幅に上がりました。
それでも落とし穴はある
ここまでは良かった点を述べてきましたが、反省点もありました。一番の反省点は、Luceneのバグ修正による挙動変更に気付かず過負荷を招いてしまったことです。
Lucene のバグ修正が入り、 ShingleFilter を利用している箇所において正しく Shingle が生成されるようになったことでマッチさせる対象が増加し、長めのフリーワード入力においてFullGC+タイムアウトを起こしてしまいました。ミドルウェアのアップグレードに際しては機能差分だけを見るのではなく、「重くなりがちな操作」についても確認すべきであるという教訓を得ました。
Solr6.5.0以前をご利用の方で、Solr6.5.1以降にアップグレードされる方はお気をつけください。
最終的な成果とまとめ
Solrアップグレードにより、組織としては以下の恩恵が得られました。
・検索APIの高速化(200ms→50ms)
・サーバ台数の削減(約60%減)
・開発効率の向上(実機が不要な場面が増加)
・開発者のモチベーション向上(アップグレードの前例があるため、小さいデータセットなら容易にアップグレード可能)
半年ほどかけてアップグレードを完遂しましたが、開発効率を上げたことで新規の構築案件などがスムーズに進んでおり、比較的早期に投資を回収できそうな状態です。また、恒久的なコスト削減もできました。
アップグレードだけを目的とするのではなく、アップグレードを契機に開発フローをアップグレードすることで全体的な開発効率を上げていくという考え方は幅広く応用可能かと思いますので、参考にしていただければ幸いです。