
Jupyter で公共交通データを可視化する

こんにちは、ふた月です。
ナビタイムジャパンで主にサーバーサイドのシステム開発や公共交通データの運用改善を担当しています。
今回は公共交通データの運用改善を進める中で、学習や調査向けのデータ可視化に Jupyter を使用した事例を紹介します。
Jupyter とは
Jupyter はインタラクティブにプログラミングやデータ分析を行うための Web アプリケーションです。Python で利用されることが多いですが、数十のプログラミング言語に対応しています。JupyterLab や Visual Studio Code を利用してローカル環境で利用する他、 GCP、 Azure といったクラウド環境上でも動作環境が提供されています。機械学習でよく用いられている Google Colaboratory にも Jupyter が利用されています。
向き合いたい課題
当社では経路探索や案内情報の提供のために、様々な独自フォーマットのデータが運用されています。データそれぞれに仕様書や可視化ツールが整備されているため、仕様の把握や不具合の調査を実施することは可能です。しかし、下記のような課題がありました。
複数の情報を組み合わせる場合、データ単体の仕様だけではなく経路探索等のアルゴリズムを(時に深く)理解する必要がある
データの不具合により可視化ツールを利用できない場合、別の方法で情報を取得する必要がある
なぜ Jupyter なのか
私が以前からプロトタイピングツールとして利用していたという点も影響していますが、社内の課題解決へのアプローチとして利用するようになったのは下記のような理由があります。
独自フォーマットで作成されている公共交通データの Python 製パーサーが既に開発されている
豊富な Python ライブラリを利用し、手軽に可視化することができる
データ取得の手順をコードとして残すことができる
インタラクティブにデータの取得手順を再現することができる
Jupyter での可視化例
Jupyter を利用し、簡単な可視化をしてみます。今回は渋谷駅の出口情報をテーブルと地図上に表示してみようと思います。
まずは情報を取得します。確認のために取得したデータから駅名、出口の名称をそれぞれ表示していますが、正しく取得できていそうです。

次に出口の情報をテーブルとして表示してみます。テーブルの表示には Pandas という数値計算ライブラリを使用しています。

最後に渋谷駅の出口を地図上にプロットしてみます。地図の表示には Folium という地理情報ライブラリを使用しています。 OpenStreetMap 上にアイコンをプロットするようにコードを記述しています。


事例
ここからは実際に取り組んでいる施策について一部を紹介します。
仕様の理解をサポートする仕組み
公共交通データを扱う上で、データの仕様以外に、経路探索等のロジックについても理解する必要があります。
前者は主に公共交通データを開発、運用するチームで管理されていますが、後者は経路探索等のアルゴリズムを開発するチームで管理されています。
公共交通データの仕様を深く理解する上でどちらの知識も必要になりますが、チームの垣根を越境した理解が必要となるため、両方を理解しているのは一部のメンバーのみでした。
この状況を改善し、多くの開発者が仕様を理解できるようにするため、取得したい情報ごとに Jupyter のファイルを作成する施策を進めています。例えば、上記例のように駅の出口情報の一覧を取得する、ある路線のIC運賃一覧取得する、といった手順がまとめられています。
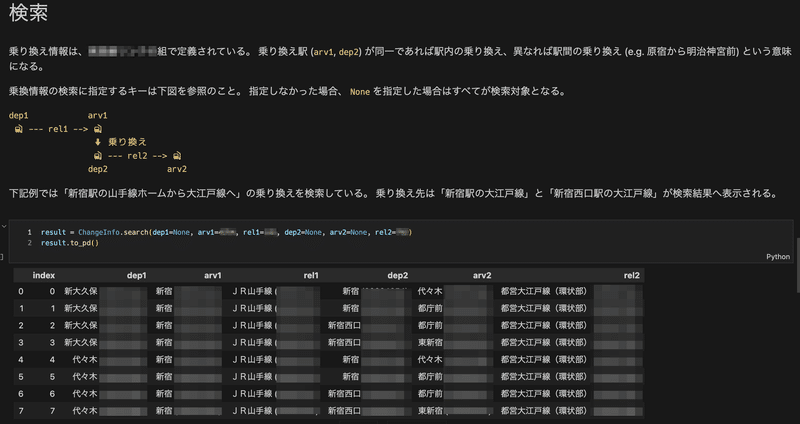
データ不具合調査を再現する仕組み
不具合の調査をする際に、再現の手順を記録したい場合があります。作業の手順やデータの内容を順序立てて記録することができるため、他のメンバーへの共有が容易になります。
使用するデータを変更すれば他のデータバージョンでの再現を確認することができるため、同様の不具合が発生した際の調査に再利用することができます。
さいごに
公共交通システムの運用改善施策のひとつとして、 Jupyter を使用した可視化への取り組みを紹介しました。
インタラクティブにコードを実行することができ、その共有、再現や可視化が手軽に行えることは仕様の理解や不具合の調査に有用でした。
逆に、現状は実際の仕様書やプロダクトコードとは別に管理されている仕組みであるため、仕様理解のための情報が複数のリポジトリへ分散してしまうデメリットがあります。今後は情報の分散を防ぎ、一元化する仕組みづくりにも着手していきたいと思います。