
「AIの創作を評価するAI」がうまくいかないと考える理由、あるいは「クララとお日さま」「アイの歌声を聞かせて」にみる、テキストGANのような発想がうまくいかない理由+では、どうしたらいいのか?

「AIのべりすと」を公開してから数ヶ月が経ち、各方面から技術面でのアドバイス等の打診をいただくようになりました。
私自身可能な範囲でのAIのオープン利用化を進めるべく取り組んでいるところでもあり、極力対応していけるように日々努力しているところです。
その中でよく質問に上がるのが「ヒット作品を生成できる、あるいはヒット作品のようなプロットを生成できるAIができないか」というものなんですが……
これは残念ながら、現時点では、最新版のGPT-3 Instructのような大量の人力のインプットで訓練されたAIでも現実的ではないことです。また、AIは画像処理のような感覚で解像度の低いものを解像度の高いものに変換・補間するのは得意です(私の知人で、音楽ゲームの譜面を似たような解像度変換の仕組みで自動生成するAIを訓練した人がいました)が、逆のパターンでは、どうやって学習用のデータを充分な量用意するのかという問題にもぶち当たります。プロット書きのようなデータは絶対量が多くないからです。
現在、AIのべりすとで使用している最新バージョンのAIは、スパム等のノイズを取り除いた段階で1.2TB~1.3TBのコーパスを既に読み込んでおり、現時点でネットで公開されている日本語のテキスト+電子書籍などのテキストを事実上網羅していると考えられます。同じ内容のコーパスを繰り返しての学習(マルチエポック学習)は多くの場合逆効果であることがわかっていて、テキストデータの絶対量が少ないドメインにおいての習熟度はどうしても下がってしまいます。
そこで、画像生成で使われるGANの仕組みのように、AIが書いた文章を評価するAIを組み合わせる(テキストGAN)ことで「良い」文章が作れないか? ということを考える方も多いようです。
ロボット工学三原則のごとし袋小路にはまるAI
アイザック・アシモフのロボット工学三原則を耳にしたことがある人は多くても、元の小説を読んだことがある人は多くないかもしれません。アシモフの小説では、三原則にどうしても矛盾・違反せざるを得ないような状況を与えられたロボットは壊れてしまいます。そこでは、実はロボット工学三原則は機能しないものとして描かれています。
GANのようなある種の評価関数をテキスト生成に組み込むアイディア(例えば、2~8台のAIによる合議制のような仕組みのMixture of Experts方式や、Best of n方式)はたびたび試みられていますが、大きな成功を収めた例は無いように思います(MoEは1兆パラメータ級など、パラメータ数が非常に多く訓練できるのでたびたび話題になりますが、重複したパラメータも多く、「船頭多くして船山に登る」になりがちであることから、先端研究の世界ではdense(濃密なモデル)に対してMoEをsparse(希薄な)モデルと呼んで区別します)。
一つ明らかな問題として、確率の高い答えだけを採用しているとAIが思考の袋小路にはまるのです。

残念ながら、AIが導き出す「最高の答え」はこうなりがち。ビームサーチも似たような結果になる
性能の高いAIは「バグ」を迂回する方法を覚えます。最近、Transformerの核であるアテンションヘッドの仕組みに比較的重篤なバグ(アテンションパーキングと呼ばれ、直前に注目した単語が「頭から離れなく」なってしまう)があることがわかり、一部で話題となりましたが、充分に長く訓練するとそうしたバグを迂回する方法をAIは半ば勝手に学んでしまいます。
単純に「AAAAAAAA」を禁止すると今度は「aaaaaaa」とか「ddddddd」とか言い始めてしまいます。
また、強制力の強いフィルターは様々なドメインに悪影響を及ぼすことがわかっています(あまりにも悪影響の範囲が広く強いので、ロボトミー手術にたとえられることがあります)

OpenAIによるGLIDEフィルター済モデル(3行目)。人の顔に相当するデータを取り除いただけなのに、計算機も「青い箱」もハムスターも描けなくなってしまった
エントロピー・サンプリング(AIのべりすとでは「タイピカルP」として実装)などサンプリング方式に工夫を加えたり、事前・事後処理をうまく行うことで影響を軽減することはできますが、単純に最もスコアが高い出力を選ぶという発想がそもそもうまくいかないことがわかると思います。
AIと評価関数にまつわる現代のフィクション2つ「クララとお日さま」「アイの歌声を聞かせて」
評価関数を文章生成や画像生成のようなオープンエンドなAIに適用するというアイディアは近年棄却されつつありますが、わかりやすくAIらしさが出ることから、フィクションの世界ではまだまだ「命題に振り回されるAI」が描かれることが多いです。対照的な2つのフィクションをご紹介します。
「クララとお日さま」はカズオ・イシグロによる小説で、なにやら重篤な病気を患わったジョーシィのもとにクララという「Artificial Friend」(人工の友達)がやってきます。クララはソーラーパワーで動いているので、栄養源である太陽光を信仰し、大気汚染を発生させて光を遮断するあらゆる装置を仮想敵と見なしています。クララはジョーシィにとっての栄養を自分と同じそれであると考えたのか、ある行動に出ますが……。
「アイの歌声を聞かせて」は日本のアニメーション映画で、シオンという「サトミを幸せにする」ことを目的としたAIがサトミの元にやってきます。彼女は人間からすると明らかに突飛な行動に出るようでもあって、実は将棋のように何十手先までが見えているようでもいて……
この2つの作品はとても対照的です。どちらの主題のAIもある命題に縛られており、それによって副作用的に生じた思い込みを元に行動を起こしますが、顛末の描かれ方は異なります。欧米で「アイの歌声を聞かせて」が作られていたら、「クララとお日さま」のようなビターエンドの作品や、もっと昔ならアイザック・アシモフの小説のようなAIの自己崩壊になっていたかもしれません。
もう少し考察してみると、どちらの作品もAIに与えられている縛りは極端に厳しいものではなく、比較的ソフトな誘導であると考えられます。これなら崩壊に至るはるか前に思考を迂回させることができるので、変な行動は起こしますが、少なくともロボット三原則のような状況には陥りません。
実は、この「フィルターや禁止行動のような極端に厳しい縛りではなく、ソフトに誘導する」というアイディアは、今最先端のAIで一番有望と見做されています。
AIの救世主? アダプターチューニング/ソフトチューニング
「AIのべりすと」ではMODという仕組みを導入していますが、これは専門的にはソフトチューニングと呼ばれるものです。
もともと、OpenAIがGPT-3のAPIを発表した段階で、大規模な言語モデルであれば、ファインチューニングを施さなくてもプロンプトを人力調整(プロンプト・エンジニアリング)することでほとんどのタスクに対応できることは知られていました。そこから訓練用コーパスへのタグ付けという第2世代の発想が生まれ、その更に1歩先の第3世代の技術と言えるのがこのソフトチューニングです。
これは、大雑把に言えばAI本体にアダプターと呼ばれるごく小さなAIを連結し、この「小さなAI」の部分だけを訓練する仕組みです。この仕組みは計算量が少なく済むだけでなく、文章同士など同じドメインに限らず、例えば画像情報のある部分と音声情報のある部分を相互変換するようにAIに自分で学ばせることができるなど、非常に大きな可能性を持っています。
AIのべりすとではフィクションに必要な情報量を考慮して、少し多めに50文字~100文字となっていますが、オリジナルのソフトチューニングの論文では20文字程度を付与するだけで、実際に精度が有意に向上するとしています。
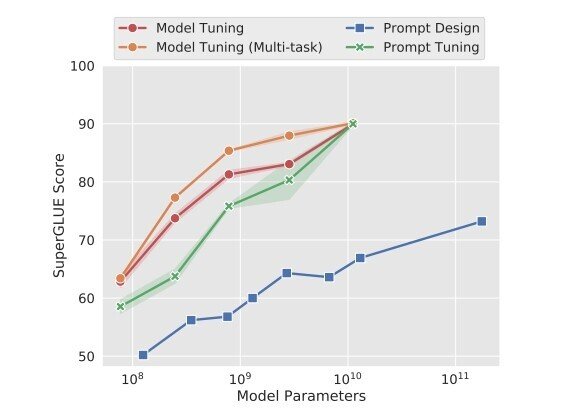
The Power of Scale for Parameter-Efficient Prompt Tuning (2021 Brian Lester, Rami Al-Rfou, Noah Constant)
緑の線がソフトチューニング。
モデルをファインチューンしたのと同じ結果が最小限のコストで得られる
DeepMindが2021年12月に発表したRETROは、BERT(検索エンジンなどに使われるAI)を用いて自動的に適切なコーパスを検索して持ってくる仕組みです。いわば、検索エンジンとソフトチューニングの組み合わせなのですが、75億パラメータのモデルでありながら、タスクによっては2800億パラメータのモデルを遥かに超えるベンチマークスコアが出たのだそうです。
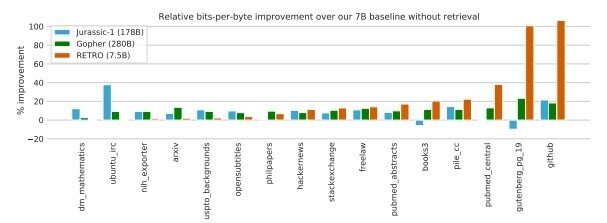
Improving language models by retrieving from trillions of tokens
(2022 Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack W. Rae, Erich Elsen, Laurent Sifre)
これは、言われてみれば当然のことです。充分なコンテキスト(ユーザーの入力)が与えられなければ、当てずっぽうで推論せざるを得なくなり、いくら高性能のAIでも見当違いなことを言う可能性が高まります。必要な情報を必要な時にAIに与えてあげる、あるいはRETROのように自力で引き出すことができれば、極端に高性能なAIでなくても客観的な性能は飛躍的に向上するのです。
ちょうど人間に教えるのがそうであるように、テキストGANやフィルタリングのような強制的・懲罰的な仕組みでAIを無理やり制御しようとするよりも、文字通りソフトに成すべきことや必要な情報を与えて誘導してあげる仕組みが現時点ではもっとも成功しているということがわかります。
フィクションの中で、今は命題、推論、現実の矛盾に苦しむAIですが、今後は描かれ方も変わってくるのかもしれません。
この記事が気に入ったらサポートをしてみませんか?