
Tsurugi 1.0.0-BETA4 について

βリリースについては、概ね月一ぐらいの間隔で刻んでだす、という方針です。
が、今回については、タフな ブロッカーがタイミングよく enbug したという事情もあり、リリース間隔が空いて、通常想定よりも一ヶ月遅れという運びになっています。
先にキャリーできる issue であればキャリーしてしまって、とりあえず可能なものだけも順次リリース、が本来の「刻んで出す」という方針ではあるのですが、コードフリーズの直前でブロッカーを検出するという流れが3週ほど続いたということもあり、まぁなかなかそうも行きませんでした。
さて、リリースノートにあるとおり、β4 はほぼ bug 回収がメインのリリースです。
feature についても新規 のものはあるにはありますが、新規機能というよりは既存機能の修正や、本来あるべきものがなかったのでち ゃんと追加した、というものがおおいです。
目玉機能の追加、というよりも、必要な修正に淡々と対応します、 ということになります。
▽リリースノート
https://github.com/project-tsurugi/tsurugidb/discussions/41
GAに向けて、β2以降は専ら「安定性=バグ回収」を目的とするリリースになるので、とくにパフォーマンス向上には作業優先度は振っていません。
現在のフェーズではある程度パフォーマンスが維持できればよい、というスタンスで臨んでいます。
開発方針としては、パフォーマンス<SQL拡張<安定性 の優先度を取っています。なお、パフォーマンスについては次々のフェーズに改良が(可能であれば)入ると思います。
とはいえ、大幅に劣化は許容できないので、どの程度のパフォーマンスの変化なのかを見てみます。
パフォーマンスについては、基準としてβ2・β3・β4についてそれぞれ実行日として
β2:2023/11/19
β3:2024/1/28
β4:2024/4/10
を取っています。
バッチ処理はCost-Accounting処理で、データサイズはlarge10で、書籍のベンチマークを実行しています。詳細はTsurugi本の「4.6 サンプルベンチマークの実行と評価」を参照してください。
まず、大きな前提として、β2からβ4に至って、大量のバグフィクスを行っており、それに伴い内部の実装についてもそれ相応に修正を入れています。
このため、Tsurugiの開発側では、そもそも比べることに意味があるのか?という意見もあります。一方、基本のアーキテクチャは変わっていないので、パフォーマンス特性に大きな影響はないとはいえ、ユーザベースで見た場合は、現実にどの程度の影響があるのか?は気になるところでしょう。
また、どうしても開発的には近視眼的に見てしまうという点は否めないので、その立ち位置への自省は必要です。もちろん、これだけの実装期間が開いたパフォーマンス比較では、その違いを実装ベースへ還元することはほとんど意味がない(よって比較の意味がない)、という意見は説得性があります。その点にはご留意ください。
その上で、まずバッチ処理です。

概ね10%程度劣化しています。
原因はcommit wait周りのバグ回収やSQL系の処理・通信制御系の細かい修正によるものかと思われます。どれも安定化に優先してコードを改修しています。
つぎにバッチとオンラインの混合です。

概ね、バッチ単独からバッチとオンラインの混合による、バッチの劣化は10%を切るレベルで収まっています。β1の時が112%程度ですので、総じてTsurugiとしてはバッチの、オンラインとの混在実行時の劣化は10%程度が一つの目安になるのではないかと思われます。
オンラインのみの実行と、混合実行によるオンライン実行の遅延の劣化です。

概ね100-110%の間ぐらいの劣化ということになるかと思います。ワークロードによっては向上するところもありますが、基本は変わっていません。
バッチ処理については以上です。これらの実行は原則バッチ側はLTX、オンライン側はOCC→LTXで実行されています。
次にOCCのパフォーマンスをSQLレイヤーからベンチマークします。
単純なベンチマークとして、単一テーブルへのInsert(upsert)を比較します。
β2のTPSを基準にしているので100%以下が劣化になります。
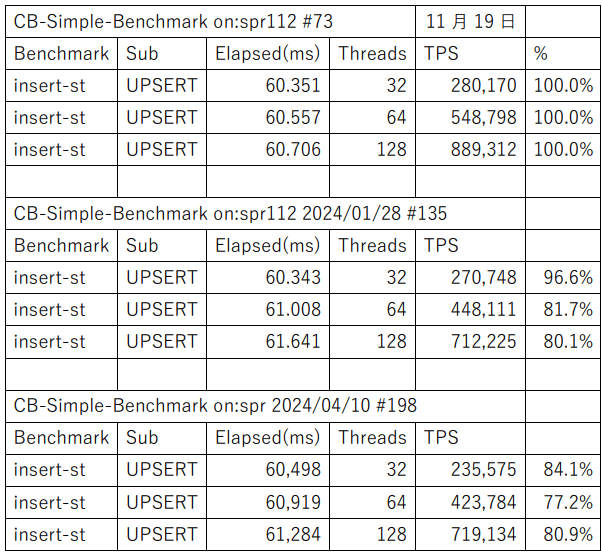
β2からβ4へは概ね、20%程度の劣化です。単純な比較は出来ませんが、バッチ(LTX)よりも顕著には見えます。
現時点では、LTX側はバグの回収が進みつつ、多少のパフォーマンス・ロスが認められます。OCCについても劣化が認められますが、劣化の度合がLTXよりも顕著なのは、単純にワークロードへの処理あたりのターンアラウンドがOCCの方が相対的に短いためとも考えられます。
が、そもそも別々の原因ということもありうるので、現時点では判断つきかねます。前述のようにかなりのバク回収を行っているため、単純な原因に還元するのはもう少し時間がかかると思われます。
ここで、それでは、上位は切り離した下位のCCレイヤーでの実行はどうなのか?ということで、上記のInsertの結果に対して、YCSBでの結果の変遷を見てみます。SQLの実行が概ねread-modify-writeであることより比較対象ワークロードはAを採用しています。
そもそも、SQLでのInsert実行とYCSBでの実行は内容に違いありすぎて、比較の対象にならないという意見もあるかと思いますが、ここではInsert実行のCCレイヤーでの実行オペレーションが比較的単純なread/writeに還元されるため、シンプルなread/writeの実行という観点から、大雑把な目安としての比較を行います。

SQLの実行結果とは逆に、概ねβ2→β4でかなりのパフォーマンスの向上になっています。こちらはコードの整理含めて、大分よい結果が出たということでしょう。
CCレイヤーでの単純なread/writeでの実行については一連のβでは劣化は認められないので、おそらくOCC/LTXの実行計画実行時のread/writeでも同様に劣化は発生してないとみる方が妥当かと思われます。
OCCでのSQL実行でのInsertとYSCB-Aとのスループットの差は、数字上は10倍程度(β4の32-128コア)になります。CCレイヤーがかなり改善されているので、全体として上位レイヤーでの劣化として見るという見方は最初の仮説としては妥当でしょう。これはこれから状況に応じて判断していきます。
まとめ:
上位レイヤーの劣化については、Tsurugi本に記述している当初の見通しの通りで、SQLとKVSとのパフォーマンス・ギャップが明確になりつつある、とみる方が妥当だろうと個人的には見ています。が、実際にこれがあたるかどうかはこれから調査に入ります。
仮に、ギャップが先鋭化している、ということであれば、ギャップが4-5倍から10倍程度に乖離している可能性もあり(これもSQLのinsertとYCSBのスループット(TPS)の比較なのであまり参考にはなりませんが・・・)、この場合は現在開発ロードマップに明示されていない、KVSインターフェースの強化の開発優先度があがる可能性があります。
なお、基本特性は変わっていないように見えるので、OCCとLTXの利用ついては、まずはOCCで実行し、abortが上がるようであればLTXで、またバッチ処理のようなそもそも重たい処理はLTXで、という戦略に変更はないでしょう。
次世代高速RDB 劔"Tsurugi"は、オープンソースで公開中です。
従来のRDBに比べて書き込み性能に強く、In-memory/many-coreで性能がスケール(特にcore数に応じてスケール)するため、高い処理性能を発揮し、世界最速レベルの性能を有しています。
劔"Tsurugi"を使用する際のサポートも開始しまし、様々な企業様より問い合わせやPoCの申し込みをいただいています。
劔"Tsurugi"に関する詳細やお問い合わせは、下記をご覧ください。
https://www.tsurugidb.com/about.html
この記事が気に入ったらサポートをしてみませんか?