
[冒頭だけ無料公開] Pythonでクラウドファンディングのデータ分析をしてみよう

Techpitで販売中の学習コンテンツの冒頭無料部分を記載します。
はじめに
本教材(私が制作したもの)はプログラミング言語の1つであるPythonを使ってクラウドファンディングのデータ分析を行っていきます。データ分析の一連の流れを習得していただくことを本教材の一番の目的としています。具体的にはデータ分析に必要なツールの導入、ツールの基本的な使い方、実際のデータを使って数値を可視化、それに基づいて考察を行うという流れを掴んでいただきます。
現在、データがどんどん自由に手に入る時代となってきています。データ分析の基礎をマスターして自分が望む通りに有効活用できると素晴らしいですよね。
今回はクラウドファンディングサービスの1つであるKICKSTARTERのデータを活用します。クラウドファンディング?KICKSTARTER?という方は、まずはKICKSTARTERとはどんなサービスかを見てみましょう。
参考)KICKSTARTER
クラウドファンディングは、ある人が自分で立ち上げたいプロジェクトを企画紹介し、そのプロジェクトに興味ある人がそのプロジェクトにお金の支援をできるサービスです。KICKSTARTERは世界最大のクラウドファンディングサービスと言われています。日本発のサービスではReadyforやCAMPFIREが有名です。
KICKSTARTERのデータには、どのサービスにどんな人がいつどれくらいの金額を支援したかが格納されています。まだ分析していないので、どんな結果が得られるかわかりません。
しかし「こんなサービスが人気があるんだ」とか「こんなサービスはこういった層の人たちに支援してもらえやすいんだ」などが分析によって判明すれば、数字の羅列はとても有益な情報に変化します。ぜひデータ分析の基本を学習して、データを有効活用できる力を身につけてみてください。
学習内容
ブラウザ上でPythonを実行する環境であるGoogle Colaboratoryの使い方を学びます。
データ分析の前段階であるデータの取り込み、データクレンジングを学びます。
データがどのようなものであるかを知るための、集計方法、整形方法、グラフ化方法を学びます。
データから何が言えるかを考えていく考察ステップを学びます。
受講における必要条件
Pythonの基礎知識が必要です。Pythonを一度も触ったことがない方は、まずはProgate等で学習することをおススメします。
この教材の対象者
Excelでグラフ化やデータ分析のようなことをしたことはあるが、さらにpythonでデータ分析してみたい方
pythonはどんなものか知っていて、これからデータ分析に活用してみたいという方
分析に興味はあるが、なにから始めたらよいかわからない方
機械学習やディープラーニングを勉強する前に、まずはPythonでビックデータの取り扱いに慣れたい方
学ばないこと
本教材はデータ分析のおおまかな流れ(データ取り込みから可視化まで)を把握することを一番の目的としています。そのため統計学の基礎知識に関してはあまり触れていません。また機械学習手法であるランダムフォレストやSVR、ディープラーニングなどは対象範囲外となります。
データ分析後のアウトプットのイメージをつかもう
最終的には下記動画のように、数値データを作成してデータをグラフ化して可視化しながら、データから何が言えるのかを考察していきます。
目次
【1章】 分析の元となるデータを取り込んでみよう
分析に必要なpythonのライブラリを導入し、実際に活用するデータを取り込んで行きます。
【2章】 データをきれいにしよう(データクレンジング)
世の中のデータはきれいでないことがよくあります。
ところどころ欠損している部分があったり、分かりづらかったりするデータをきれいに整えていきます。
【3章】 分析に役立ちそうな新しいカラムを作成しよう
現状のデータセットから、分析に役立ちそうな新しい情報を考え、新たにカラムを追加していきます。
【4章】 分析してみよう
分析のゴールを意識しながら、データセットから様々なグラフを作成して可視化していきます。
【5章】 考察してみよう
分析結果をまとめ、そこから何が言えるのか?また分析結果から新たな課題を設定していきます。
【6章】 新たな課題を分析してみよう
考察の結果、新たに設定された課題に取り組んでいきます。
【おまけ】
分析に使えるPythonコードをまとめています。※※※中略します※※※
中略部分もTechpitで無料サンプルとして閲覧できます。
※※※中略します※※※
データクレンジング その1(カラム名変更、カラム削除、欠損データ処理)
このパートでは「1章:分析の元となるデータを取り込んでみよう」で取り込んだKICKSTARTERのデータに対して、データクレンジングを行っていきます。
本章のゴール
本章では、データをグラフ化して理解を深めながらデータクレンジングを行っていきます。

データクレンジングの工程は少し長くなるので、いくつかのパートに分けて進めていきます。それでは早速、1章で作成したanalytics_01.ipynbを開いてデータクレンジングを始めていきましょう。
本パートの流れ
カラム名を理解する
不要なカラムを削除する
カラム名の変更
欠損データの確認
欠損データをどう処理すべきか考える
欠損部分に値を代入する
1. カラム名を理解する
まずは対象のデータセットを確認するため下記コードを実行します。
df.head()すると下記画像のように出力されます。

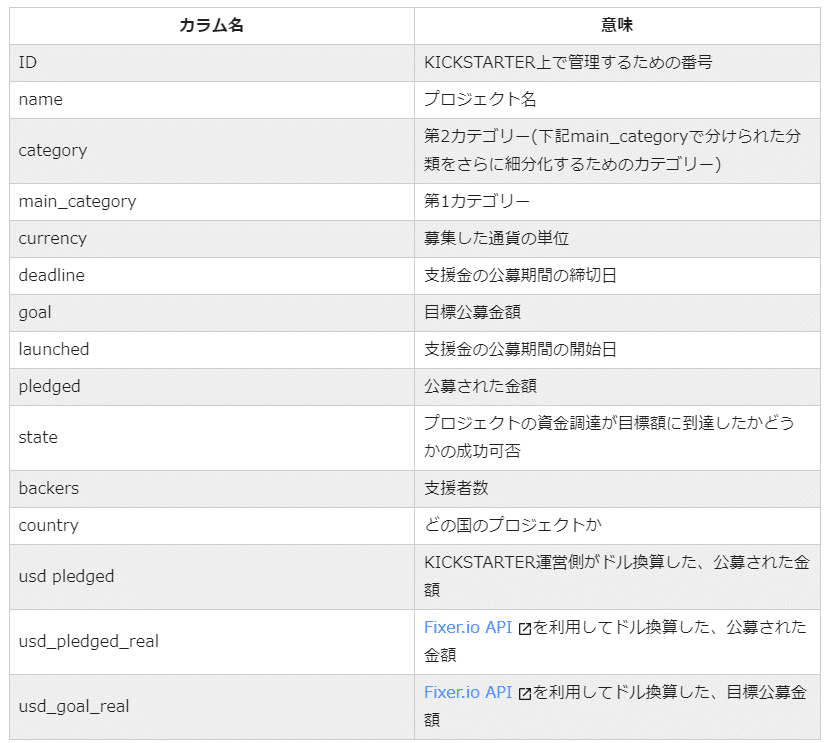
データ分析者本人がデータの意味をしっかりと理解していないと、適切なデータクリーニングができません。まずはこのデータの列(カラムと呼ばれます)の名前の意味を理解していきましょう。Kaggleでは、データの大まかな説明やカラム名の意味は「Description」に記載されているケースが多いです。
Google翻訳などを利用して解釈した結果は下記のようになります。
参考:Fixer.io API
2. 不要なカラムを削除する
今回のデータ分析のゴールは「クラウドファンディングでの資金調達成功プロジェクトの特徴、もしくは資金調達失敗プロジェクトの特徴を掴む」ことです。このゴールに対して、不要なデータは削除してしまいましょう。例えば下記のようなカラムは不要です。
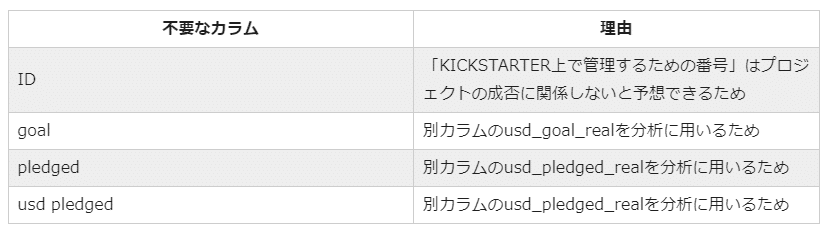
カラムの削除は以下のコードを用います。
新データの変数名 = 旧データの変数名.drop(['不要なカラム名1', '不要なカラム名2', '不要なカラム名3', ・・・], axis=1)行名を指定して行を削除したい場合は、オプションとしてaxis=0を指定します。カラム名を指定して列を削除したい場合は、オプションとしてaxis=1を指定します。
※何も指定しなければデフォルトでaxis=0が適用されます。
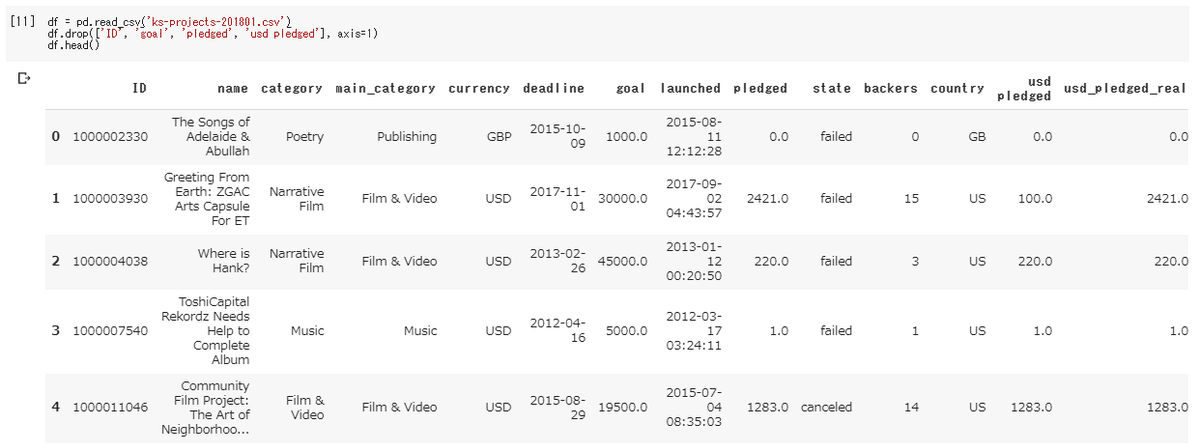
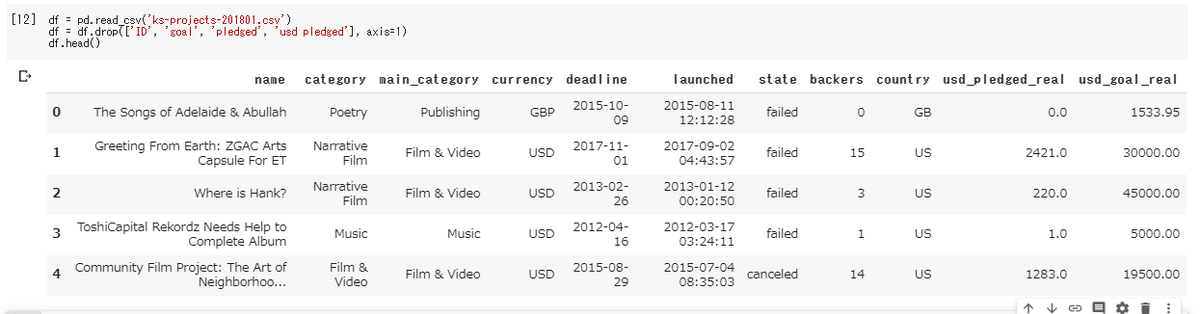
それではID、goal、pledged、pledgedの4つのカラムを削除し、新たに生成されたデータをdfという変数に再格納するには、下記コードを実行します。
df = df.drop(['ID', 'goal', 'pledged', 'pledged'], axis=1)問題なく指定したカラムが削除されているか確認してみましょう。
df.head()下記画像のように表示されれば成功です。しっかりとID、goal、pledged、pledgedの4つのカラムが削除されていることが確認できます。

補足:データ更新時の注意点
df.drop(['ID', 'goal', 'pledged', 'pledged'], axis=1)を実行してもカラムを削除した結果が表示されるだけで、dfの中身は変化しません。
df = df.drop(['ID', 'goal', 'pledged', 'pledged'], axis=1)と再代入することで初めてdfが更新されます。
また再代入しなくてもdropメソッドにinplace=Trueを指定してdf.drop(['ID', 'goal', 'pledged', 'pledged'], axis=1, inplace=True)と実行すればdfの値は更新されます。
3. カラム名の変更
次に、カラム名が英語だとイメージが湧きにくいので、カラム名を日本語に変更します。カラムの変更は以下のコードを用います。
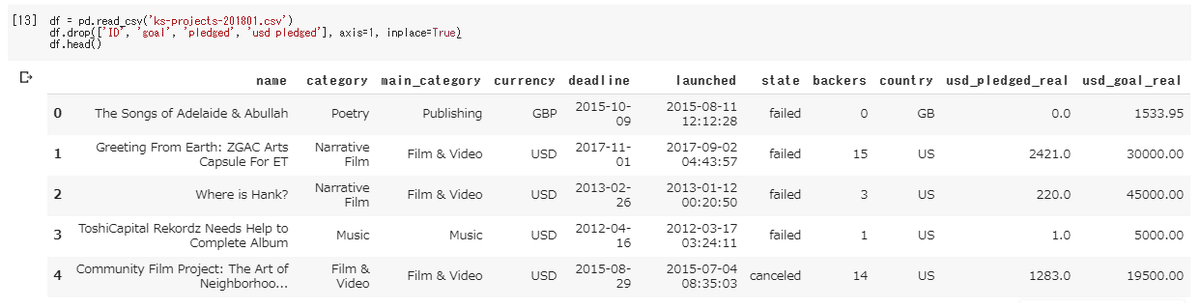
新データの変数名 = 旧データの変数名.rename(columns = {'変更前カラム名1': '変更後カラム名1', '変更前カラム名2': '変更後カラム名2', ・・・})カラム名をすべて日本語に変更し、新たに生成されたデータをdfという変数に再格納するには下記コードを実行します。
df = df.rename(columns = {'name': 'PJ名', 'category': '第2カテゴリー', 'main_category': '第1カテゴリー', 'currency': '通貨', 'deadline': '締切日', 'launched': '開始日', 'state': '成否', 'backers': '支援者数', 'country': '国', 'usd_pledged_real': '支援額', 'usd_goal_real': '目標額'})問題なくカラム名が日本語に変更されているか確認してみましょう。
df.head()下記画像のように表示されれば成功です。しっかりとカラム名が日本語に変換できていることが確認できます。

補足:データ更新時の注意点
先程のカラム削除と同様、df..rename(columns = {'変更前カラム名1': '変更後カラム名1', '変更前カラム名2': '変更後カラム名2', ・・・})を実行してもdfは更新されません。下記2通りの方法でdfを更新できます。
df = df.rename(columns = {'変更前カラム名1': '変更後カラム名1', '変更前カラム名2': '変更後カラム名2', ・・・})と再代入する
df.rename(columns = {'変更前カラム名1': '変更後カラム名1', '変更前カラム名2': '変更後カラム名2', ・・・}, inplace=True)とオプションでinplace=Trueを指定する
4. 欠損データの確認
データ分析で使用しているデータセットの中には、一部データが入っておらず空白となっている可能性もあります。小さなデータセットであれば目で確認できますが、大きなデータセットであればデータの抜け漏れの確認は大変です。
そんな時、便利なメソッドがあります。infoメソッドで各カラムに格納されているデータ数が確認できます。早速実行してみましょう。
df.info()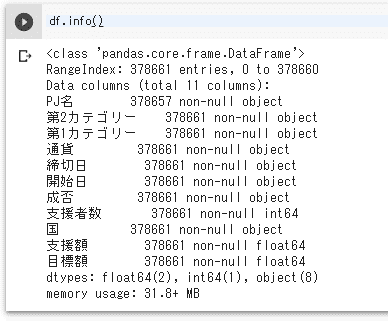
上記画像の表示結果は、PJ名カラムに378657件のデータが格納されており、それ以外のカラムには378,661件のデータが格納されているという意味です。現在使用しているデータセットは何行だったでしょうか?
「1-1 KICKSTARTERのデータを取り込んでみよう」の最後に調べましたが、378661行です。

つまり、PJ名カラムに4件(378661 - 378657 = 4)のデータが欠損しているということになります。では、その欠損しているデータがどのようなデータか確認してみましょう。df['カラム名']で指定したカラムの情報のみを取得できます。試しにPJ名カラムを取得してみましょう。
df['PJ名']すると下記画像のように0から始まる行番号と、PJ名カラムに格納されている様々なプロジェクト名が確認できます。
※行番号はインデックスと呼ばれます。インデックスが3の時、そのデータは4行目のデータであることを示しています。

この中で欠損しているデータを探していきます。isnullメソッドはデータが欠損している場合Trueが返り、データが存在している場合Falseが返ります。df['PJ名']に対してisnullメソッドを実行してみましょう。下記のようにコーディングして実行します。
df['PJ名'].isnull()すると下記画像のようにインデックスとTrue or Falseが表示されます。

この中で欠損していることを示すTrueの行のみを表示させたい場合、下記コードを実行します。
df[df['PJ名'].isnull()]すると下記画像のようにPJ名カラムにデータが入っていない4行のみ表示されます。
※NaNはデータが入っていないことを意味しています。

5. 欠損データをどう処理すべきか考える
欠損データを確認できました。では、以下のいずれの処理をすべきでしょうか?
欠損部分に何らかの値を代入する
欠損している行をまるごと削除する
データ分析者本人が、データの性質やデータ分析のゴールを加味して考えます。データ分析のゴールは「クラウドファンディングでの資金調達成功プロジェクトの特徴、もしくは資金調達失敗プロジェクトの特徴を掴む」です。
今回の場合、PJ名カラムにデータが入っていない4行は、PJ名以外のデータはしっかりと入っていました。そのため、この4行はデータ分析をする上で十分に活用できるだろうと推測できます。したがって「欠損部分に何らかの値を代入する」という方針でデータクレンジングを行うことにします。
この時点でデータクレンジングの判断が間違っていても構いません。データクレンジングとデータ分析を繰り返して試行錯誤しながら進めていくのが通常です。
6. 欠損部分に値を代入する
欠損部分に値を代入するにはfillnaメソッドが便利です。下記のコードを実行することで欠損部分にno_nameという文字列データを代入できます。早速実行してみましょう。
df['PJ名'].fillna('no_name')下記画像のように欠損部分にno_nameという文字列データを代入した結果のPJ名カラムが表示されます。

df['PJ名'].fillna('no_name')を実行してもdfは更新されません。
それでは欠損部分にno_nameという文字列データを代入したPJ名カラムをdfのPJ名カラムに代入してみましょう。
df['PJ名'] = df['PJ名'].fillna('no_name')これでPJ名カラムの欠損部分にno_nameという文字列データが入ったはずです。実際に入っているか確認してみましょう。df.loc[インデックス番号配列]によって指定したインデックスの行が表示できます。先ほどPJ名カラムの欠損が確認できたのはインデックス166851, 307234, 309991, 338931でした。これらを表示して確認してみましょう。
df.loc[[166851, 307234, 309991, 338931]]
しっかりとPJ名にno_nameと入力されていることが確認できます。さらにinfoメソッドを使って、現状のdfには欠損が存在していないか、念の為確認しておきましょう。さらにinfoメソッドを使って、現状のdfには欠損が存在していないか、念の為確認しておきましょう。
df.info()
上記画像のように表示され、各カラムに378661件のデータが存在していることが確認できます。これで欠損データに対するデータクレンジングが完了しました。引き続き次のパートでもデータクレンジングを行っていきます。
Techpitのサイトでは、もう少し先まで無料閲覧できます。Pythonによるデータ分析手法にご興味ある方は是非お試しください。
この記事が気に入ったらサポートをしてみませんか?