
【初心者向け】Pythonでスクレイピングする環境を作る④ requestsでデータを取得してみる

Naruhikoです。
環境はうまく構築できたでしょうか。
いつでも Python を始められますね。
今回から、Python のプログラムを組んでいきます。
少しずつ進めていきたいと思います。
crawler.py の作成
では、Python のコードを書いていくファイルを用意しましょう。
VSCode の左にディレクトリが表示されています。
作成している「crawler」ディレクトリを右クリックし
「New File」をクリックします。
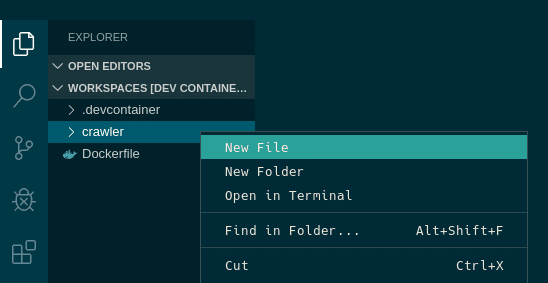
新しいファイルが出来るので、ファイル名を「crawler.py」にしましょう。
ファイルが作成されて、コードエリアに表示されました。

文字を表示する
ということで、これからコードを書いていきます。
とりあえず・・・例のやつをしましょうか。
print("Hello world!")
これをコードエリアに入力して保存します。
保存は、[Ctrl] + s でできます。
そして下にコンソールがありますので、コマンドを入力してみましょう。
root@e973f742a9b6:/workspaces/Workspaces# cd crawler
root@e973f742a9b6:/workspaces/Workspaces/crawler# python crawler.py
Hello world!例のものが表示されましたね。
きちんと Python が動いていることを確認しました。
ライブラリをインポートする
今回のスクレイピングに必要なライブラリをインポートしましょう。
・requests
・bs4
でしたね。
インポートは簡単です。
# インポート
import requests
# ライブラリの中のクラスをインポート
from bs4 import BeautifulSoupと最初に記述します。
from 文は、一つのライブラリの中のクラスを使いたいときなどに使用します。
例えば、flask というライブラリはたくさんのクラスを持っており
それぞれ使い分けたりします。
from flask import Flask, render_template, request, logging, Response, redirect, flashこれらは全て flask ライブラリの中に内包されています。
複数インポートする場合は、続けて記述します。
# 続けて記述
import requests
from bs4 import BeautifulSoup
# カンマを入れると連続して記述可能
import requests, bs4PEP8 というコーディング規約に従うのならば、
カンマを使わないほうがいいです。
さらに PEP8 に従うのなら、順番も考えていきます。
1.標準ライブラリ
2.サードパーティに関連するもの
3.ローカルな アプリケーション/ライブラリ に特有のもの
request も bs4 もサードパーティなので、2番目のグループに記述します。
# 標準ライブラリ
import os
import sys
# サードパーティ製
import requests
from bs4 import BeautifulSoup
# ローカル
import localmoduleこんな感じですね。
ここまでで crawler.py の中はこうなりました。
import requests
from bs4 import BeautifulSoup
print("Hello world!")
requests してみる
では、google のコードを取得してみましょう。
まずは、変数に url を入れておきます。
url = "https://www.google.com"requests の get を使ってデータを取得し、resp という変数に代入します。
今回は例で resp としましたが、変数名は変更しても大丈夫です。
resp = requests.get(url)取得したデータをアウトプットしてみましょう。
print(resp.text)こんなコードになりました。
import requests
from bs4 import BeautifulSoup
# urlを代入
url = "https://www.google.com"
# データ取得
resp = requests.get(url)
print(resp.text)<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="ja"><head><meta content="世界中のあらゆる情報を検索するためのツールを提供しています。さまざまな検索機能を活用して、お探しの情報を見つけてください。" name="description"><meta content="noodp" name="robots"><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content="/images/branding/googleg/1x/googleg_standard_color_128d
詳細\x22,\x22oskt\x22:\x22入力ツール\x22,\x22psrc\x22:\x22この検索キーワードは\\u003Ca href\x3d\\\x22/history\\\x22\\u003Eウェブ履歴\\u003C/a\\u003Eから削除されました\x22,\x22psrl\x22:\x22削除\x22,\x22sbit\x22:\x22画像で検索\x22,\x22srch\x22:\x22Google 検索\x22},\x22ovr\x22:{},\x22pq\x22:\x22\x22,\x22refpd\x22:true,\x22refspre\x22:true,\x22rfs\x22:[],\x22sbpl\x22:16,\x22sbpr\x22:16,\x22scd\x22:10,\x22stok\x22:\x22wFC-34XxRXPQbfOgvrQ3FyISpto\x22,\x22uhde\x22:false}}';google.pmc=JSON.parse(pmc);})();</script> </body></html>
量が多かったので、途中を省略しましたが、データは取得できていました。
requests の取得がうまく行かなくてエラーになる場合
しかし、もし取得先が遅かったり、反応がなかったらどうでしょうか。
もしかしたら url が間違ってるのかもしれません。
その場合はエラーになります。
import requests
from bs4 import BeautifulSoup
# urlを代入
url = "https://www.googleaaaaaaaaaaaaaa.com"
# データ取得
resp = requests.get(url)
print(resp.text)
これは url が存在しないので、エラーになってしまいます。
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='www.google.coma', port=443): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection object at 0x7fe7b22499d0>: Failed to establish a new connection: [Errno -2] Name or service not known'))
エラーになったときに走らせたい処理がある場合は
try - except という処理を入れるようにします。
import requests
from bs4 import BeautifulSoup
try:
# urlを代入
url = "https://www.googleaaaaaaaaaaaaaa.com"
# データ取得
resp = requests.get(url)
print(resp.text)
except:
print("取得できませんでした")
root@e973f742a9b6:/workspaces/Workspaces/crawler# python crawler.py
取得できませんでしたpython では、インデントが重要になってきます。
try - except の中の行は、頭に4つの空白を入れています。
これは、if 文や for 文などもそうですが、こうしてインデントを作ることによってブロックですよと認識しています。
このインデントは同じ数であれば何個でも問題ありません。
数さえ同じであれば機能します。
しかし、PEP8のコーディング規約を基本にするのであれば
空白4つを守ってください。
Beautiful soup で整形
さらに、この中のタグを使っていろいろ取得したいので
bs4(Beautiful soup) を使います。
これは要素を抽出してくれるすぐれものです。
soup = BeautifulSoup(resp.text, "html.parser")
print(soup.title)
抽出した要素の title タグを取得する例です。
root@e973f742a9b6:/workspaces/Workspaces/crawler# python crawler.py
<title>Google</title>
このようにして、タグ指定などすることが可能です。
さらに、タグ内のみを抽出するのなら、
soup = BeautifulSoup(resp.text, "html.parser")
title = soup.title
print(title.get_text())
と、get_text メソッドでタグの内容を取得できます。
root@e973f742a9b6:/workspaces/Workspaces/crawler# python crawler.py
Google
たくさんタグがあるのなら、find_all メソットで取得します。
import requests
from bs4 import BeautifulSoup
try:
# urlを代入
url = "https://www.yahoo.co.jp/"
# データ取得
resp = requests.get(url)
soup = BeautifulSoup(resp.text, "html.parser")
tags = soup.find_all("a")
print(tags)
except:
print("取得できませんでした")
Yahoo のサイトから a タグの中身を取得するコードです。
tags 変数に a タグをリスト形式で代入します。
root@e973f742a9b6:/workspaces/Workspaces/crawler# python crawler.py
[<a href="https://www.yahoo-help.jp/"><nobr>ヘルプ</nobr></a>, <a href="https://www.yahoo-help.jp/app/answers/detail/p/533/a_id/43883">Internet Explorerの互換表示について</a>, <a href="https://2020.yahoo.co.jp/player/olympic/">五輪代表選手が続々決定 競技別一覧でチェック</a>, <a href="https://rdsig.yahoo.co.jp/movies/academy/ytop/film/RV=1/RU=aHR0cHM6Ly9hY2FkZW15LnlhaG9vLmNvLmpwL2ZpbG0v">アカデミー賞関連の名作映画を無料配信中</a>, <a href="https://news.yahoo.co.jp/pickup/6350635">第4便帰国 1人が新型肺炎陽性<img alt="写真" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconPhoto_150713.gif" width="16"/><img alt="NEW" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconNew_150713.gif" width="30"/></a>, <a href="https://news.yahoo.co.jp/pickup/6350634">肺炎 待機期間なぜ食い違い<img alt="写真" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconPhoto_150713.gif" width="16"/><img alt="NEW" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconNew_150713.gif" width="30"/></a>, <a href="https://news.yahoo.co.jp/pickup/6350631">配偶者の子連れ去り 国を提訴へ<img alt="写真" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconPhoto_150713.gif" width="16"/></a>, <a href="https://news.yahoo.co.jp/pickup/6350636">兵士が銃乱射し死者多数 タイ<img alt="写真" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconPhoto_150713.gif" width="16"/><img alt="NEW" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconNew_150713.gif" width="30"/></a>, <a href="https://news.yahoo.co.jp/pickup/6350627">サ行言えない子 早めの対処を<img alt="写真" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconPhoto_150713.gif" width="16"/></a>, <a href="https://news.yahoo.co.jp/pickup/6350632">池江 白血病の発覚から1年<img alt="写真" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconPhoto_150713.gif" width="16"/><img alt="NEW" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconNew_150713.gif" width="30"/></a>, <a href="https://news.yahoo.co.jp/pickup/6350623">桃田骨折 復帰プランが白紙に<img alt="写真" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconPhoto_150713.gif" width="16"/></a>, <a href="https://news.yahoo.co.jp/pickup/6350622">GENERATIONS中務 同棲報道<img alt="写真" border="0" height="12" src="//s.yimg.jp/images/top/sp/cgrade/iconPhoto_150713.gif" width="16"/></a>, <a href="https://news.yahoo.co.jp/topics/top-picks?date=20200208&mc=f&mp=f">もっと見る</a>, <a href="https://news.yahoo.co.jp/fc">記事一覧</a>, <a href="https://headlines.yahoo.co.jp/hl?a=20200208-00000051-mai-soci.view-000"><img alt="ひな壇飾りお目見え" border="0" height="120" src="https://lpt.c.yimg.jp/im_sigg0sHmD5l5IvBky1YYF9FSCQ---x300-y300/amd/20200208-00000051-mai-000-view.jpg" width="88"/></a>, <a href="https://headlines.yahoo.co.jp/hl?a=20200208-00000051-mai-soci.view-000">ひな壇飾りお目見え</a>, <a href="https://shopping.yahoo.co.jp/?sc_e=ytc">ショッピング</a>, <a href="https://auctions.yahoo.co.jp">ヤフオク!</a>, <a href="https://lohaco.jp/?bk=t&sc_e=j_as_ya_tc_n&iscr=1">LOHACO</a>, <a href="https://travel.yahoo.co.jp/?sc_e=ytsl">トラベル</a>, <a href="https://rdsig.yahoo.co.jp/travel_kanko/yjtop_cont/RV=1/RU=aHR0cHM6Ly93d3cuaWt5dS5jb20vaWtDby5hc2h4P2Nvc2lkPWlrMDEwMDAyJnN1cmw9JTJG">一休.com</a>, <a href="https://rdsig.yahoo.co.jp/reservation/yjtop_cont/RV=1/RU=aHR0cHM6Ly9yZXN0YXVyYW50LmlreXUuY29tL3JzQ29zaXRlLmFzcD9Db3NObz0xMDAwMDE3NSZDb3NVcmw9">一休.comレストラン</a>, <a href="https://news.yahoo.co.jp/">ニュース</a>, <a href="https://weather.yahoo.co.jp/weather/">天気・災害</a>, <a href="https://sports.yahoo.co.jp/">スポーツナビ</a>, <a href="https://finance.yahoo.co.jp/">ファイナンス</a>, <a href="https://tv.yahoo.co.jp/">テレビ</a>, <a href="https://gyao.yahoo.co.jp/">GYAO!</a>, <a href="https://games.yahoo.co.jp/">ゲーム</a>, <a href="http://yahoo-mbga.jp/?_ref=aff%3Dysm001">Yahoo!モバゲー</a>, <a href="https://map.yahoo.co.jp/">地図</a>, <a href="https://transit.yahoo.co.jp/">路線情報</a>, <a href="https://retty.me/?utm_y_pc_top">Retty</a>, <a href="https://realestate.yahoo.co.jp/">不動産</a>, <a href="https://carview.yahoo.co.jp/">自動車</a>, <a href="https://trilltrill.jp/">TRILL</a>, <a href="https://rdsig.yahoo.co.jp/partner/from_ytop/pc/list1/RV=1/RU=aHR0cHM6Ly9wYXJ0bmVyLnlhaG9vLmNvLmpwLw--">パートナー</a>, <a href="https://services.yahoo.co.jp/?mode=pc">>>サービス一覧</a>, <a href="https://login.yahoo.co.jp/config/login?.src=www&.done=https://www.yahoo.co.jp">ログイン</a>, <a href="https://account.edit.yahoo.co.jp/registration?.src=www&.done=https%3A%2f%2fwww.yahoo.co.jp">新規取得</a>, <a href="https://accounts.yahoo.co.jp/profile?.src=www&.done=https%3A%2f%2fwww.yahoo.co.jp%2F"><img alt="登録情報" border="0" height="16" src="//s.yimg.jp/images/top/sp/cgrade/info_btn-140325.gif" width="47"/></a>, <a href="https://mail.yahoo.co.jp/"><img align="absmiddle" alt="Yahoo!メール" border="0" height="16" src="//s.yimg.jp/images/top/sp/cgrade/iconMail.gif" width="16"/>メール</a>, <a href="https://mail.yahoo.co.jp/promo/">メールアドレスを取得</a>, <a href="https://calendar.yahoo.co.jp/">カレンダー</a>, <a href="https://calendar.yahoo.co.jp/info/guide/">カレンダーを活用</a>, <a href="https://points.yahoo.co.jp/" title="ポイントを確認">ポイントを確認</a>, <a href="https://lh.login.yahoo.co.jp/" title="ログイン履歴を確認">ログイン履歴を確認</a>, <a href="https://about.yahoo.co.jp/">会社概要</a>, <a href="https://about.yahoo.co.jp/ir/">投資家情報</a>, <a href="https://about.yahoo.co.jp/csr/">社会的責任</a>, <a href="https://about.yahoo.co.jp/info/charter/">企業行動憲章</a>, <a href="https://marketing.yahoo.co.jp/">広告掲載について</a>, <a href="https://about.yahoo.co.jp/hr/">採用情報</a>, <a href="https://about.yahoo.co.jp/docs/info/terms/">利用規約</a>, <a href="https://about.yahoo.co.jp/docs/pr/disclaimer.html">免責事項</a>, <a href="https://about.yahoo.co.jp/info/mediastatement/">メディアステートメント</a>, <a href="https://privacy.yahoo.co.jp/">プライバシー</a>]リストとは、カンマ区切りで複数データを格納する形式です。
これをタグの中身だけ取得するには、for 文を活用します。
for tag in tags:
print(tag.get_text())tags 変数から取り出した内容を tag に代入し、そして get_text() によってタグ内の内容のみを取得します。
root@e973f742a9b6:/workspaces/Workspaces/crawler# python crawler.py
ヘルプ
Internet Explorerの互換表示について
五輪代表選手が続々決定 競技別一覧でチェック
アカデミー賞関連の名作映画を無料配信中
第4便帰国 1人が新型肺炎陽性
肺炎 待機期間なぜ食い違い
配偶者の子連れ去り 国を提訴へ
兵士が銃乱射し死者多数 タイ
サ行言えない子 早めの対処を
池江 白血病の発覚から1年
桃田骨折 復帰プランが白紙に
GENERATIONS中務 同棲報道
もっと見る
記事一覧
ひな壇飾りお目見え
ショッピング
ヤフオク!
LOHACO
トラベル
一休.com
一休.comレストラン
ニュース
天気・災害
スポーツナビ
ファイナンス
テレビ
GYAO!
ゲーム
Yahoo!モバゲー
地図
路線情報
Retty
不動産
自動車
TRILL
パートナー
>>サービス一覧
ログイン
新規取得
メール
メールアドレスを取得
カレンダー
カレンダーを活用
ポイントを確認
ログイン履歴を確認
会社概要
投資家情報
社会的責任
企業行動憲章
広告掲載について
採用情報
利用規約
免責事項
メディアステートメント
プライバシーうまくデータが取れるようになりましたね。
今回作成した最終コード
最後に、作成したコードを載せておきます。
import requests
from bs4 import BeautifulSoup
try:
# urlを代入
url = "https://www.yahoo.co.jp/"
# データ取得
resp = requests.get(url)
# 要素の抽出
soup = BeautifulSoup(resp.text, "html.parser")
tags = soup.find_all("a")
# タグ内テキスト
for tag in tags:
print(tag.get_text())
except:
print("取得できませんでした")次回は、google 検索をした結果を取得してみようと思います。
---
気に入っていただけたら、フォローや好きをお願いします!
連載目次
【初心者向け】Pythonでスクレイピングする環境を作る① はじめに
【初心者向け】Pythonでスクレイピングする環境を作る② Dockerの使い方
【初心者向け】Pythonでスクレイピングする環境を作る③ VSCodeでDocker環境を構築する
【初心者向け】Pythonでスクレイピングする環境を作る④ requestsでデータを取得してみる
【初心者向け】Pythonでスクレイピングする環境を作る⑤ Google検索をしてみる
【初心者向け】Pythonでスクレイピングする環境を作る⑥ スクレイピングでの注意事項
【初心者向け】Pythonでスクレイピングする環境を作る⑦ 検索結果のページのタイトルを取得する
【初心者向け】Pythonでスクレイピングする環境を作る⑧ クラスにまとめてみる
【初心者向け】Pythonでスクレイピングする環境を作る⑨ テストしてみる
【初心者向け】Pythonでスクレイピングする環境を作る⑩ crawler と scraper を分ける
ここから先は
¥ 100
この記事が気に入ったらチップで応援してみませんか?