
mysql5.7でgeometry型を試す

概要
mysql.5.7.12(AWS aurora)で、近傍検索を試したのでその手順をまとめます。大枠以下のような流れです。
1) データを用意する
国土交通省のページから、住所と緯度経度情報のデータをダウンロードする
2) テーブルを作成し、データを流し込む
ダウンロードしたデータをテーブルにimportできるような形に整形する。
3) 近傍検索を試す。
特定の位置から、近い住所を検索する。
環境
AWS aurora
mysql> SELECT VERSION();
+-----------+
| VERSION() |
+-----------+
| 5.7.12 |
+-----------+
1) データを用意する
以下のページから、位置参照情報を取得していきます。

このページから市区町村単位を押して次へ進みます。

県と、市区町村を選択します。ここでは、とりあえず試せれば良いので八王子にしました。特に意味はありません。データ量が必要なら市区町村全域をチェックすれば良いです。 全国&&市区町村を一回で取る方法は提供されてなかった。 47回やらずに済む方法が知りたい・・・

次に進むとこのような画面になります。ここで、レベル(大字・町丁目)になっている項目を選択してダウンロードします。同意してダウンロードすると、以下のようなデータが取得できます。
"都道府県コード","都道府県名","市区町村コード","市区町村名","大字町丁目コード","大字町丁目名","緯度","経度","原典資料コード","大字・字・丁目区分コード"
"13","東京都","13201","八王子市","132010001000","宇津貫町","35.617579","139.335315","0","1"
"13","東京都","13201","八王子市","132010002002","兵衛二丁目","35.623214","139.334553","0","3"
"13","東京都","13201","八王子市","132010003000","上柚木","35.623189","139.368880","0","1"
"13","東京都","13201","八王子市","132010004002","上柚木二丁目","35.619540","139.370093","0","3"
"13","東京都","13201","八王子市","132010005005","南大沢五丁目","35.611379","139.371016","0","3"
"13","東京都","13201","八王子市","132010004003","上柚木三丁目","35.616890","139.371494","0","3"
"13","東京都","13201","八王子市","132010006002","南陽台二丁目","35.633140","139.377550","0","3"
ファイルがShift-jisになっていてmysqlへimportした時に文字化けしてしまいす。nkfコマンドでUTF-8に変換します(mysqlをsjisで運用してない限り)
nkf -w --overwrite 13201_2018.csv
2) スキーマ作成 + 整形データの読み込み
データベース(test)と、位置情報を格納するテーブル(geo_test)を以下のようにして作成します。
CREATE DATABASE test CHARACTER SET utf8mb4;CREATE TABLE `geo_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`prefecture` varchar(255) NOT NULL,
`city` varchar(255) NOT NULL,
`address` varchar(255) NOT NULL,
`location` geometry SRID 4326 NOT NULL,
PRIMARY KEY (`id`),
SPATIAL KEY `location` (`location`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4
緯度と経度の情報を保存するカラムはlocationとし、typeにgeometryとします。検索用インデックスはSPATIAL KEYでつけます。インデックスの定義方法は、大枠3通りあるのでこちらを参照してください
次に、ダウンロードしたデータから必要な部分だけを抽出し、MySQLへインポートできる形式に変更します。今回は、都道府県名、市区町村名、大字町丁目名、緯度、経度としました。
cat 13201_2018.csv | awk -F, '{print "NULL,"$2","$4","$6",POINT("$8" "$7")"}' | sed 's/\"//g' > geo_test.csv
要点は以下の通りです。
- id auto_incrementのために先頭はNULLとする
- 緯度、経度は、POINT(geometryのデータ形式の1種)では経度 緯度の順番で書く必要があるので逆にしている
- 後述するデータ読み込み時の関数でPOINTにダブルクォーテーションが入っているとエラーになるので、sedで削除
このコマンドを実行すると、以下のようなデータに整形できます。
NULL,都道府県名,市区町村名,大字町丁目名,POINT(経度 緯度)
NULL,東京都,八王子市,宇津貫町,POINT(139.335315 35.617579)
NULL,東京都,八王子市,兵衛二丁目,POINT(139.334553 35.623214)
NULL,東京都,八王子市,上柚木,POINT(139.368880 35.623189)
NULL,東京都,八王子市,上柚木二丁目,POINT(139.370093 35.619540)
NULL,東京都,八王子市,南大沢五丁目,POINT(139.371016 35.611379)
NULL,東京都,八王子市,上柚木三丁目,POINT(139.371494 35.616890)
NULL,東京都,八王子市,南陽台二丁目,POINT(139.377550 35.633140)
NULL,東京都,八王子市,下柚木,POINT(139.374757 35.630028)
NULL,東京都,八王子市,南陽台一丁目,POINT(139.372870 35.633801)
NULL,東京都,八王子市,長沼町,POINT(139.367759 35.642169)
NULL,東京都,八王子市,高倉町,POINT(139.366721 35.666115)
NULL,東京都,八王子市,南大沢四丁目,POINT(139.374672 35.607974)
NULL,東京都,八王子市,下恩方町,POINT(139.251052 35.665693)
データの整形ができたら作成したスキーマにimportします。 ここではLOAD DATA INFILEを使用します。
LOAD DATA LOCAL INFILE '/Users/あなたの環境/Downloads/13201-12.0b/geo_test.csv'
INTO TABLE geo_test
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@col1, @col2, @col3, @col4, @col5)
SET
id = @col1,
prefecture = @col2,
city = @col3,
address = @col4,
location = GeomFromText(@col5, 4326);要点は以下の通り。 POINT(経度 緯度)は文字列なので、そのままではimportできません。従って、GeomFromTextを使って文字列からgeometry型として扱えるように変換してあげる必要があります。
FIELDS TERMINATED BY ',' : フィールドをカンマ区切りで読み込む
LINES TERMINATED BY '\n' : 一行を改行単位として読み込む
IGNORE 1 LINES : 最初の一行(ラベル)を無視する
GeomFromText : テキストをgeometry型として扱える形式に変換する。
このimportクエリですが、auroraでそのまま実行しようとすると、権限が無いと言われてしまうので、クエリ実行時に以下のようにlocal-infileオプションでDB名を指定します。そのまま実行しようとすると、権限が無いと言われてしまうので、クエリ実行時に以下のようにlocal-infileオプションでDB名を指定します。
mysql -uroot -h 127.0.0.1 -P 3306 -p --local-infile test_db -e "use test_db; LOAD DATA INFILE ~~~~~";
ここまでで近傍検索を行うまでの準備が整いました。次に実際にクエリを叩いて、検索してみます。
3) 近傍検索を試してみる
八王子駅から、近い町を10件取得してみることにします。 八王子駅の緯度と経度が知りたい場合は、google mapで八王子駅と検索するとurlに緯度と経度が表示されます。

対象の緯度経度が139.3366642 35.6556157なので、以下のようなクエリを発行します。
SELECT address, GLength(GeomFromText(
CONCAT('LineString(139.3366642 35.6556157 , ',
X(location),
' ',
Y(location),
')'
)
)) as distance
FROM geo_test
ORDER BY distance limit 10;
微妙にややこしいように見えますが、やっていることは以下の通り。
1) LineStringで、駅とそれぞれの町の緯度経度とを線で繋ぐ
2) GeomFromTextで、この情報をgeometry型として扱う。(そのためにCONCATで連結して文字列にしている)
3) GLengthで引いた線の距離を求める(度数)
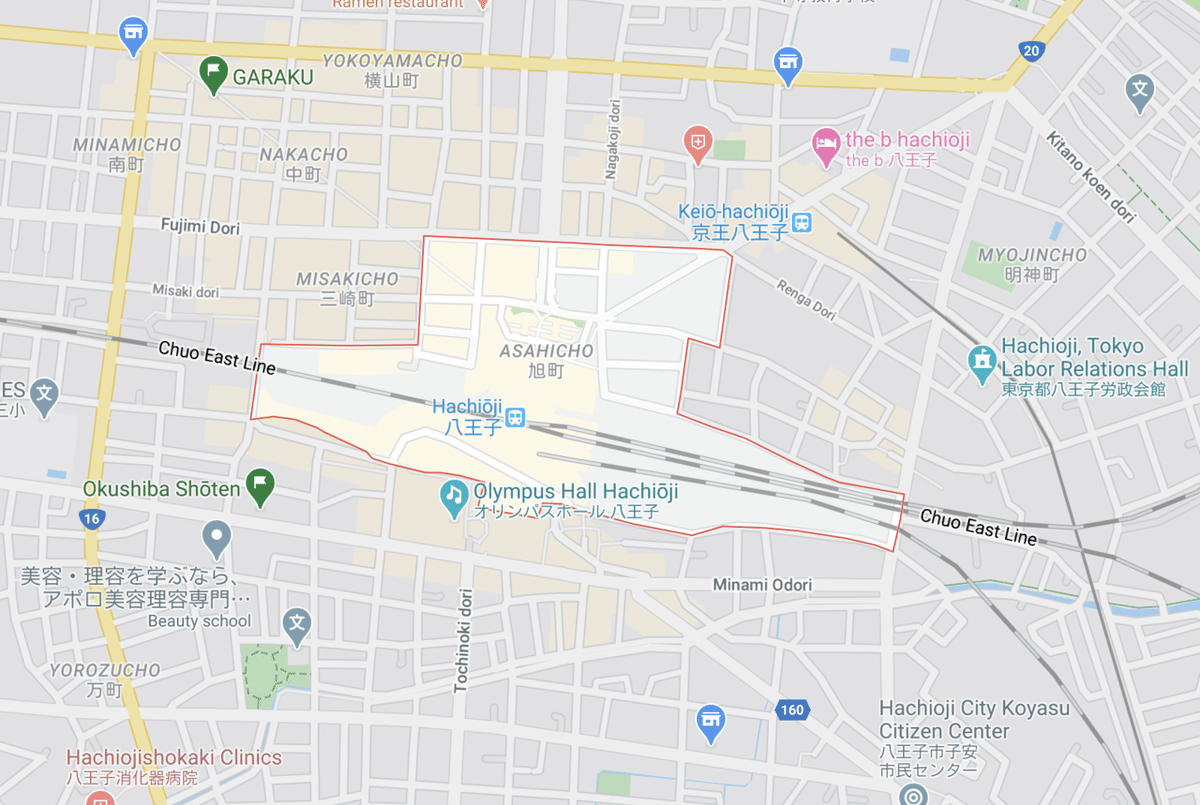
これで取得した駅から近い町名は以下の通りです。
+--------------------+-----------------------+
| address | distance |
+--------------------+-----------------------+
| 旭町 | 0.0015329260680070121 |
| 三崎町 | 0.0015843982233049484 |
| 子安町四丁目 | 0.001750589537839614 |
| 中町 | 0.002821891268284681 |
| 寺町 | 0.0038315604823689242 |
| 東町 | 0.003958128943076597 |
| 横山町 | 0.004201306907381681 |
| 南町 | 0.004658425971299623 |
| 万町 | 0.005305957154931144 |
| 子安町三丁目 | 0.006243589250579919 |
+--------------------+-----------------------+
10 rows in set, 4 warnings (0.04 sec)ちなみに旭町をgoogle mapで検索してみると以下の通りで、一番近いことが視覚的にわかります。
度数を距離(メートル)で取得したい場合は、ST_distance_Sphereを使用します。GLengthを使用した場合よりも完結に書くことができます。
SELECT address,
St_distance_sphere(St_geomfromtext('POINT(139.3366642 35.6556157)', 4326)
,
location) AS distance
FROM geo_test
ORDER BY distance
LIMIT 10; 出力は以下の通りでGLengthとは完全に出力が同じでは無いですが、(おおよそ)近い順で取得することができました(ロジックベースで、この誤差が理解できてる方がいらっしゃたらご教示いただけると幸いです) ちなみに手元の環境下ではこちらの関数を使用した方がパフォーマンスが良かったです。
+--------------------+--------------------+
| address | distance |
+--------------------+--------------------+
| 旭町 | 139.78886827539063 |
| 三崎町 | 173.67738429995845 |
| 子安町四丁目 | 194.62264565871595 |
| 中町 | 311.61798032840323 |
| 寺町 | 349.26939477609636 |
| 東町 | 397.0128373700228 |
| 南町 | 460.7985185186269 |
| 横山町 | 466.78516045613105 |
| 万町 | 531.6100457592022 |
| 明神町三丁目 | 621.130091401851 |
+--------------------+--------------------+
10 rows in set (0.01 sec)
参考リンク
LineString
[NOTE] RDS vs Aurora パフォーマンス
auroraではR-treeをB-treeにマッピングすることによって、indexのパフォーマンスを改善している。 現用RDSを使用していてspatial indexのチューニング必要な場合は、auroraを検討しても良いかもしれない
Auroraのgeospatial indexesは、MySQL 5.7よりもselect-only(1秒当たりの読み込み回数)ワークロードで10倍以上、write-only(1秒当たりの書き込み回数)で20倍以上優れています。具体的には、サイズが1 GB未満のデータセットでSysbenchを使用して、AuroraとAmazon RDS for MySQL 5.7をdb.r3.8xlargeインスタンスを用いて計測しました。select-onlyのテストでは、2,000クライアントとST_EQUALSクエリを使用しました。write-onlyテストでは、4,000のクライアントを使用しました。
この記事が気に入ったらサポートをしてみませんか?