
【1-11】Rで必要なベクトルとdata.frameについて

Rで医療統計を行う場合ExcelでデータをとりRで読み込んで使うといった方法がほとんどだと思います。EZRやRコマンダーで統計を行うときは気にしなくてもいいのですが、RやRStudioで統計を行うときは「ベクトル」や「データフレーム(data.frame)」といった知識があると理解が進みやすいです。今回はベクトルとdata.frameについて解説していきます。
ベクトルとは?
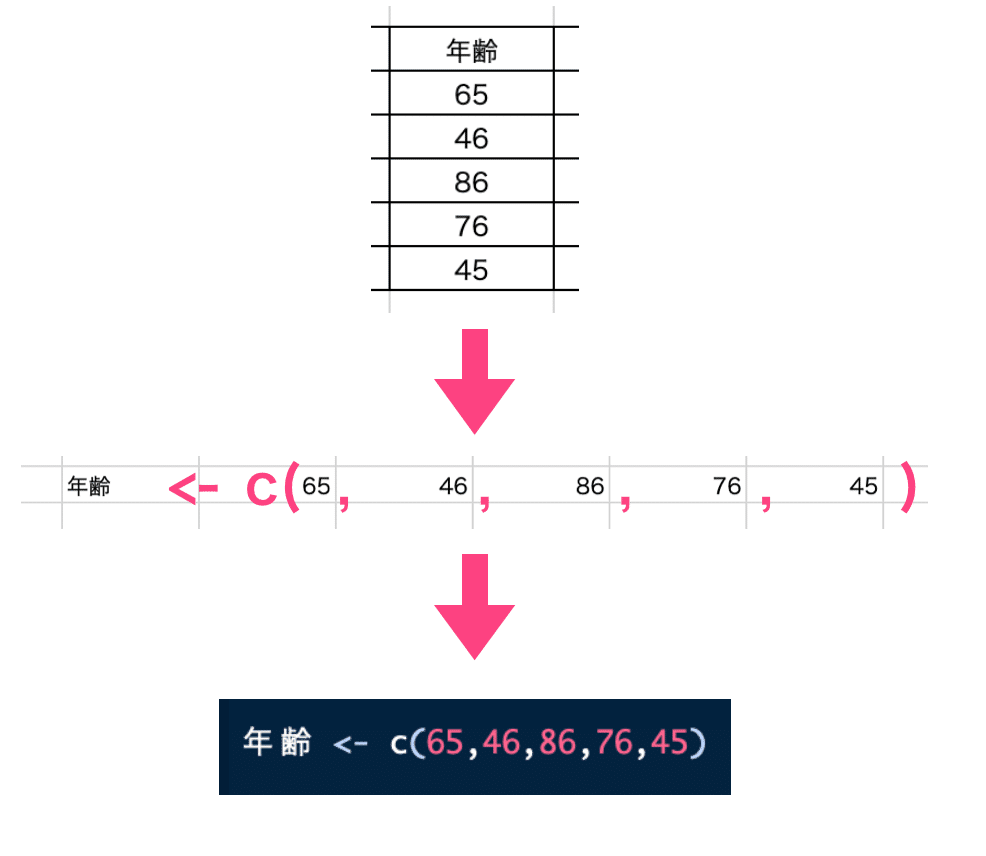
ベクトルは複数のデータの集まり(1行)になります。プログラミングでは横に書きますが、上図のように縦に並べるイメージを持つと良いです。プログラムの初心者はここがつまづきやすいかもしれません(Excelでは1人1人のデータを入力するので横のイメージ)。
x1 <- 1
x2 <- c(65, 46, 86, 76, 45)
x1 + 1 #計算できる
x2 + 1 #これも計算できる
x3 <- c(39, 21, NA, 20, 15) #間に空欄を入れるときはNAをつける
x4 <- c("おはよう", "こんにちは", "こんばんは") #文字もいける
x3
x4

ベクトルの中の要素を取り出す
ベクトルの中から○番目の値を取り出すときは大括弧[ ]を使います。
ちなみに1始まりです。pythonなど他の言語では0始まりなことも多いので注意してください。
変数の後に空欄を入れずに[ ]をつけます。
x2[1] #65が出るはず
x2[3] #86が出るはず
x2[6] #6番目なんてないけど・・・
x2[-1] #-の場合、○番目の値を取り除くという意味になります
data.frameとは?
簡単にいうとExcelの表みたいな形式です。行(横)×列(縦)の形式になっています。上に変数名がきて、データを下に重ねていきます。
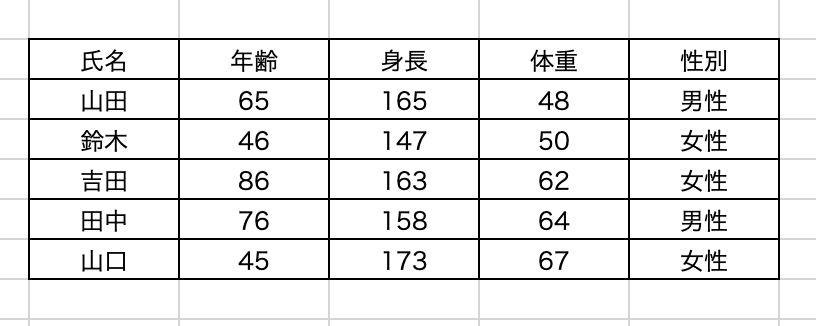
そしてdata.frameはベクトルの集合体とも言えます。
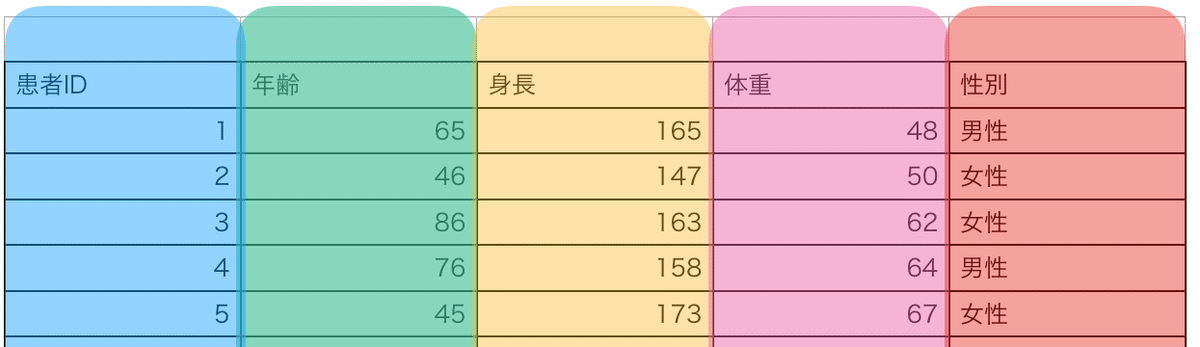
EZRやRコマンダーを使う方はエクセルのデータを読み込んでいると思いますが、これもdata.frameになります。
data.frameの読み込み
data.frameはExcelやcsvなどのファイルを読み込むことが多く、直接打ち込むことは少ないと思いますが、最初なので手打ちで作成してみます。data.frameを作成するにはdata.frame関数かdplyrパッケージのtibble関数を使うことが多いです。他にももっと大容量のファイルを読み込むときに使う関数もありますが、ここでは割愛します。
data.frame関数に直接打ち込む

#data.frame関数で手打ちする場合
data.frame(
氏名 = c("山田", "鈴木", "吉田", "田中", "山口")
)
#下のように書いてもいいが、初心者は,や()の位置を間違えてエラーを出しやすい
data.frame(氏名 = c("山田", "鈴木", "吉田", "田中", "山口"))
#2列になるときは1列目の終わりに,をつける
data.frame(
氏名 = c("山田", "鈴木", "吉田", "田中", "山口"),
年齢 = c(65, 46, 86, 76, 45)
)
#次は本番。data1という名前で作ってみる
data <-
data.frame(
氏名 = c("山田", "鈴木", "吉田", "田中", "山口"),
年齢 = c(65, 46, 86, 76, 45),
身長 = c(165, 147, 163, 158, 173),
体重 = c(48, 50, 62, 64, 67),
性別 = c("男性", "女性", "女性", "男性", "女性")
)
dataベクトルを作ってdata.frame関数で繋げる
#先にベクトルを作ってdata.frame関数で繋げる場合
氏名 <- c("山田", "鈴木", "吉田", "田中", "山口")
年齢 <- c(65, 46, 86, 76, 45)
身長 <- c(165, 147, 163, 158, 173)
体重 <- c(48, 50, 62, 64, 67)
性別 <- c("男性", "女性", "女性", "男性", "女性")
#data.frame関数で繋げる
#既にベクトルを作っているときは = をつけない場合、ベクトルの変数名がそのまま列名となる。
data2 <- data.frame(氏名, 年齢, 身長, 体重, 性別)
#dataと同じ結果になるはず
data2この方法は1つ注意点があります。以下のコードを実行してみてください。
#ベクトルを更新する
年齢 <- c(65, 46, 86, 76, 10000)
#data2を確認してみる
data2結果を見ても年齢のところが更新されていません。この理由はわかるでしょうか?プログラムは実施した順番に実行されます。data2を作ったのは年齢を更新する前です。前に行ったdata2 <- data.frame(氏名, 年齢, 身長, 体重, 性別) ですが、これは…
正しい解釈
data2という変数名にdata.frameを作って!
1行目は氏名という列名で値は(その時点の)氏名の値を使って
2行目は年齢という列名で値は(その時点の)年齢の値を使って
間違った解釈
1行目は氏名というベクトルのデータを使って。ベクトルが更新されたらそのまま反映して(2列目以降も同様・・・)
#もう一度data.frame関数を実行してみる
data2 <- data.frame(氏名, 年齢, 身長, 体重, 性別)
data2data2という変数を作ってしまったら、先に作ったベクトルたちとは全く別のものとして扱われます。値が変わって反映させたいときは改めて実行しなおしましょう。
dplyr::tibble()を使う
次はdplyrパッケージのtibble関数を使う場合です。tidyverseパッケージを読み込むとdplyrパッケージも同時に読み込むのでtidyverseパッケージを使います。もしパッケージの話でつまづいたら、過去の記事を参照してください。
#tibble関数を使う場合
#pacmanパッケージをインストールしていない場合はインストール
#インストール済みなら下の1行は行わなくてOK
if (!require("pacman")) install.packages("pacman")
#tidyverseパッケージを読み込むとtibble関数が使えるようになる
pacman::p_load(tidyverse) #pacman::p_load(dplyr)でもOK
#あとはdata.frameがtibbleになるだけで他は同じ。
data3 <-
tibble(
氏名 = c("山田", "鈴木", "吉田", "田中", "山口"),
年齢 = c(65, 46, 86, 76, 45),
身長 = c(165, 147, 163, 158, 173),
体重 = c(48, 50, 62, 64, 67),
性別 = c("男性", "女性", "女性", "男性", "女性")
)
data3data.frameの値の取り出し
data.frameから値を取り出すには複数の方法があります。
$を使う
data.frame型の変数名の後に$をつけるとその変数をベクトルとして抽出することができます。$はよく出てきます。
#$を使う
data$年齢
#計算もできる。年齢-5をしてみる
data$年齢 - 5[[]]を使う
他にも大括弧[[ ]]で挟む方法もあります。
この方法は"変数名"とするか列番号を指定するかで抽出できます。
#[[ ]]を使う #大括弧2つで挟む
data[[2]] #2列目という意味→年齢の列
data[[“年齢”]] #直接列名を打ち込むことも可。そのときは" "で挟むこの方法のメリットは列番号で指定できることと、変数名を文字型として指定できることです。下のvarは好きな名前でいいのですが、よくvariableの略でvarという変数名を使うことがあるようです。こうしておくと、もし年齢でなく身長で同じことをしたい時に var <- "身長" とさえ実行すれば下のプログラムはvarのままでいちいち書き直さなくても済む事です(プログラムが長くなれば長くなるほど、同じ作業を繰り返せば繰り返すほど恩恵を受ける)。
#こういったことができる
var <- "年齢"
data[[var]]
var <- "身長"
data[[var]]
#$ではエラーが出る
data$vardplyr::pull()を使う
もう一つ方法としてdplyrパッケージのpull()を使う方法です。
pull(data.frameの変数名, "列名or列番号")という形で表現され、data.frameでなくベクトルとして抽出されます。
#dplyr::pull()を使う
dplyr::pull(data12) #どのdata.frameかを選び,で区切って列番号を入れる
dplyr::pull(data1”身長”) #列番号ではなく列名でもOKその際は" "で挟む
#tidyverseパッケージを既に読み込んでいるときはdplyr::は無しでも大丈夫data.frameのデータの概要を掴む
data.frameですが、データの概要を知る関数もあります。
str()
str()はデータの構造を整理してくれます。データの行数・列数、各列名の型やfactor型の水準などを見ることができます。
str(data)
summary()
summary()は各列の代表値を見ることができます。
Min.:最小値
1st Qu:第一四分位(下位25%)
Median:中央値
Mean:平均値
3rd Qu:第三四分位(上位25%)
Max.:最大値
Na's:欠損値(NA)の数(なければ表示されない)
summary(data)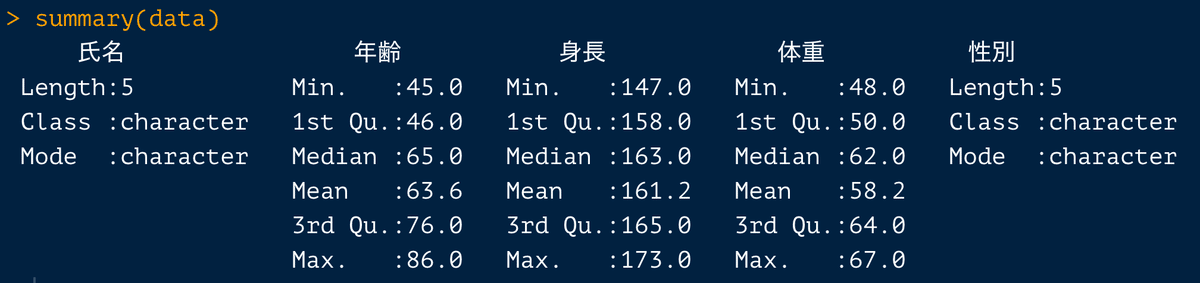
問題
dataの身長と体重の列を使ってBMIを計算してください。
BMIは体重(kg) / (身長(m))^2です。
data <-
data.frame(
氏名 = c("山田", "鈴木", "吉田", "田中", "山口"),
年齢 = c(65, 46, 86, 76, 45),
身長 = c(165, 147, 163, 158, 173),
体重 = c(48, 50, 62, 64, 67),
性別 = c("男性", "女性", "女性", "男性", "女性")
)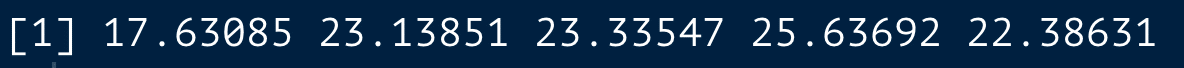
まとめ
今回はベクトルとdata .frameの話をしました。
Excelのデータを分析するときにはどれも必要な操作になりますが、少しずつ慣れてみてください。