
【3/4-3/10】生成AIツール/研究-Weeklyまとめ

今週のAIに関するツールや研究情報をまとめた記事です。
ツール
・shopifyのAIアシスタント @shopを使っての体験談
※あくまで1例で全てではないです。
- 最初に尋ねたことをすべて理解してくれたか? : No
- 機能が不足しているため、Web で購入を確定する必要があったか? : Yes
- 通常の検索よりも高速で、結果が良く、楽しいものだったか? : YesYesYes

・CLIPとChatGPTを使って、日本語で自分で撮った写真が検索できるようにした方
CLIPとChatGPTを使って、日本語で自分で撮った写真が検索できるようになった。便利。 pic.twitter.com/OUg1ww6gPl
— ミクミンP/Kazuhiro Sasao (@ksasao) March 4, 2023
・ChatGPT に Unity 上のオブジェクトを操作してもらえるようにした方
ChatGPT に Unity 上のオブジェクトを操作してもらえるようになった! pic.twitter.com/BHEHd1D4vM
— たるこす / Yusuke Furuta (@tarukosu) March 4, 2023
・【iPhoneの音声AIチャット(ChatGPT)】の設定方法紹介ツイート
【iPhoneの音声AIチャット(ChatGPT)】の設定方法を、以下ツリーで公開します❗️
— 旅人 (@Tomoto1234567) March 2, 2023
Siriより便利❗️(以下の動画参照)
iPhoneに「しつもん」と話しかけると自動でAIが立ち上がって「どうした?」と音声で聞いてくるので、質問を話すと、それに音声で答えます。AIの回答はテキストでメモ帳に自動保存❗️ pic.twitter.com/oZrF82lMUT
・NVIDIAのInstant NeRF VRのフローター消しゴムでVR空間の要素を消してる様子
Also the floater eraser in Instant NeRF VR is the most satisfying thing ever, 10/10 @NVIDIAAIDev #InstantNeRFVR #InstantNeRF #VR #AI pic.twitter.com/Nn7NvShuzB
— grade eterna (@gradeeterna) March 3, 2023
・ControlNetとGen1を比較する AI 実験
動画は3部構成
1. ControlNetによるVideo2Minecraft
2. Gen1によるMinecraft動画生成
3. 他Gen1による3Dレンダリングなど
一部詳細はスレッドにて)
ControlNetとGen1を比較する AI 実験
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 5, 2023
動画は3部構成
1. ControlNetによるVideo2Minecraft
2. Gen1によるMinecraft動画生成
3. 他Gen1による3Dレンダリングなど
一部詳細はスレッドにて) https://t.co/WiSvJFVA4K pic.twitter.com/YIWX6AIp5e
・アップデート:Auto-Photoshop-StableDiffusion-Plugin v1.2.0 ControlNetが追加
ワンクリックインストーラーなども
github: https://github.com/AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin…...
reddit: https://reddit.com/r/StableDiffusion/comments/11iuqhv/major_update_automatic1111_photoshop_stable/
Major update: Automatic1111 @Gradio Photoshop Stable Diffusion plugin V1.2.0, ControlNet, One Click Installer and More, Free and Open Source
— AK (@_akhaliq) March 5, 2023
github: https://t.co/eqCBQLZPF8
reddit: https://t.co/3JSQXdpqSM pic.twitter.com/bfLRXivLQb
・Heybot: Website to Chatbot
ウェブサイト/ブログをコーディングなしで数分でチャットボットに変換できる LPを読み込ませたり、FAQサイトを読み込ませて、シュッとチャットボット作ったりなど
※自分のOpenAI keyが必要
https://heybot.thesamur.ai/?ref=producthunt…
Heybot: Website to Chatbot
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 6, 2023
ウェブサイト/ブログをコーディングなしで数分でチャットボットに変換できる
LPを読み込ませたり、FAQサイトを読み込ませて、シュッとチャットボット作ったりなど
※自分のOpenAI keyが必要https://t.co/i1BZN7gvD3 pic.twitter.com/Dufx7makcq
・何この精密な深度マップ。目や髪や襟まで。
@clipdropappAPIによる深度マップ。 ControlNetでの使用例も
https://reddit.com/r/StableDiffusion/comments/11izkkl/using_clipdrop_api_to_create_depth_normal_for_use/

・開発者向け検索エンジン
github issueやstackoverflowなどの開発者向けソースから回答を生成 この、領域特化に引用ソースを限定して回答を生成するのは面白い かつ、添付画像のように、引用ソースの優先度を変更したり重み付けしたりは良い
https://phind.com/filters

・任意の 複数Web ページから独自の ChatGPT ボットを作成できるクローム拡張を開発中とのこと。
こンな感じの基礎技術の組み合わせで、既存企業のサイトボットをサクッと置き換えできてまいそうやけどな〜少なくともサイト内検索は置き換えよう
making an ai chrome extension👀
— James Pog (@jamescodez) March 6, 2023
lets you make your own ChatGPT bots from any webpages
here I make a bot from 3 blogs @stephsmithio @patrickc @rowancheung @LangChainAI@pinecone@OpenAI
inspired by @nutlope @mathemagic1an @ShaanVP @thesamparr @dharmesh pic.twitter.com/4R1ykaiHj3
・AI を利用した3D キャラクター作成ツールのパブリック ベータ版が公開
waitリスト:https://forms.office.com/Pages/ResponsePage.aspx?id=DQSIkWdsW0yxEjajBLZtrQAAAAAAAAAAAANAAUIQFilUNjNGM0NLUUhEUEkxVlRFTkw0OVA3NzlVNS4u
Exciting news! #ChatAvatar will be launching its public beta at the end of this month(hope so). We've been getting lots of questions lately about whether it can generate assets of movie or game quality. Why not give it a try and see for yourself? #AI #TextTo3D pic.twitter.com/qBQjIHHuUM
— Deemos Tech (@DeemosTech) March 6, 2023
・ChatGPTのAPI使ってChatGPTみたいに使えるオープンソースデモ
・前回と別デモ動画が回ってきたけど相変わらずすごいな
好きなアプリのスクリーンショット画像をアップすれば、編集可能なデザインに変換できる
https://uizard.io
Struggling to bring your ideas to life? 🤔
— uizard ✨ (@uizard) March 7, 2023
Take a screenshot of an app you like and use it as your base of inspiration. Completely personalise it to get your project kick started.
Try Uizard Screenshot now at https://t.co/ikYymOWtOv#uizard #uxui #ai #aitools #aipower pic.twitter.com/UekHJZ7jKb
・Yコンビネーター出身のパーソナル秘書サービス「Magic」
当初はtoC向けになんでも雑務をこなす(忘れ物を家に取りに帰るなどの細かいタスク含め)サービスだったけど、その後はtoB向けサービスへ転換。 今ではAIをフル活用したサービスメッセージを押し出している
https://getmagic.com

・モバイル Web 用の Poe が Android 向けに本日リリース
http://poe.comで入手可能
OpenAI の ChatGPT、Anthropic の Claude、およびその他のいくつかのボットをサポート

・Nerf + 生成AI を使用した3Dスキャンした街並みのスタイル変換
動画内のスタイル遷移: おもちゃの街 → 昼から夜 → 70 年代のシネマティック
ワークフロー: ドローン動画 → トレーニング & アニメーション化 by NeRF (Luma) → スタイル変換 by Gen1
🌉 Reskinning the iconic Painted Ladies in SF using Neural Radiance Fields + Generative AI
— Bilawal Sidhu (@bilawalsidhu) March 8, 2023
🖼 Styles: Toy City (Stylized) → Day-to-Night (Hybrid)→ 70s Cinematic (Photorealistic)
⚙ Workflow: Drone video → Train & Animate #NeRF (Luma) → Process in #Gen1 w/ style reference 📷 pic.twitter.com/ThtB2QADAW
・Stable Diffusionを使ってPhotoshopで画像編集するNextML社の新しいプラグインの映像が公開
画像編集が次の次元に来てる
— やまかず (@Yamkaz) March 8, 2023
Stable Diffusionを使ってPhotoshopで画像編集するNextML社の新しいプラグインの映像が公開されてる。拡大しきれないけど編集の境界線も違和感もほぼなくてやばいpic.twitter.com/20n1t7Abwz
・学習暗記アプリ「Monoxer」を提供している、教育スタートアップのモノグサさん確かに面白い
-AIが個々の学習者に合った学習計画の立案と管理、問題の自動生成、1日の出題数の自動調整を行い、記憶の定着を支援
-各塾で使われる問題集をAIに取り込み活用することで、問題の制作コストをゼロに抑え、各塾での導入が容易に。
-「理解は人に勝るものはない、定着こそがデジタルの出番」という考え方に基づき、理解の部分はタッチせずに、ひたすら定着の部分だけのデジタル化を促進。
-塾や予備校だけでなく、企業での研修や資格取得の対策などでも活用されている。
-モノグサは、暗記が必要な社会人の学びにも活用できる可能性があり、ポテンシャルが非常に高いと考えられている。
・すごいサービスだ お悩みにメカニカル仏が答えます

・NeRFをリアルタイム描画する #UE4 プラグインを開発中
https://youtu.be/GjpzMDur7UY
NeRFをリアルタイム描画する #UE4 プラグインを開発中🔥
— 空き家総研VRラボ -Akiya Research Institute,VRlab- (@Akiya_Souken_VR) March 8, 2023
RTX3070で60fps超で、VRAM消費が小さいことにご注目ください。
We are developing #UnrealEngine plugin for #NeRF real-time rendering.
Note that FPS is over 60 on RTX3070 and the VRAM consumption is very low.https://t.co/8ZRf1zHTJ0 pic.twitter.com/JCi6D8urBX
・GPT x マインドマップのWhimsical AI for Mind Maps
質問に対して代わりにブレストしてブロックを生成してくれる やってみたけど、いつも通り日本語は少し時間かかった
https://whimsical.com/ai-mind-maps
これ結構良かった
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 8, 2023
GPT x マインドマップのWhimsical AI for Mind Maps
質問に対して代わりにブレストしてブロックを生成してくれる
やってみたけど、いつも通り日本語は少し時間かかったhttps://t.co/ltKGDKASFa pic.twitter.com/k1xLNc6Uqw
・hubble ノーコードAIアプリ開発ツール
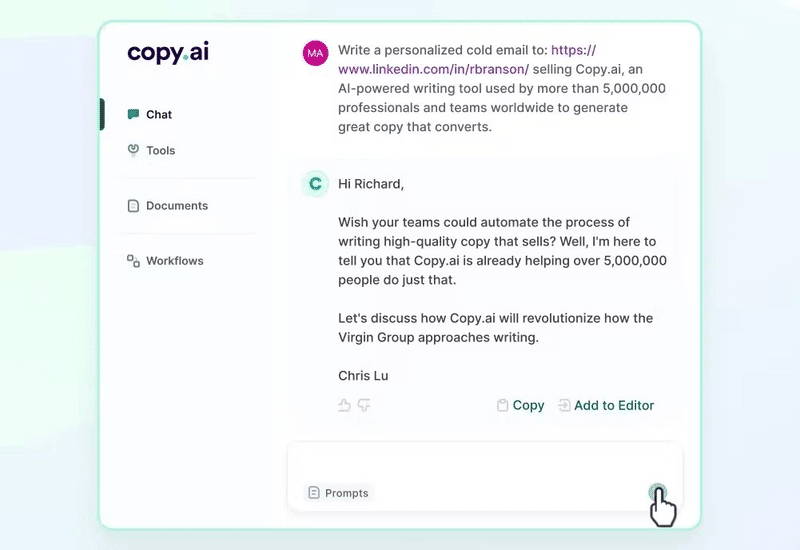
・Copy.aiがチャット機能も追加
ウェブを検索し、ソースを引用して様々な回答を生成
-リンクを貼り、ウェブサイト、YouTube動画、記事などを要約したり
-長編コンテンツをソーシャルメディアの投稿に変換したり
-企業、人物、トピックを調べたり
-ブレーンストーミングしたりなどなど https://app.copy.ai/projects/21143660?tool=chat&tab=results&ref=producthunt&sidebar=tools&text=write+a+short+product+hunt+comment+showing+love+for+Copy.ai%27s+new+chat+product
・D-IDがリアルなアバターと対面で話すことができる新しいWebアプリ「chat.D-ID」のベータ版を発表
chat.D-IDは、D-IDのテキスト動画生成とOpenAIのChatGPTを組み合わせ、より多くの人々がAIと会話できるようにしたサービス
・Brexは、CFOやそのチーム向けのAIツールを発表
企業の支出に関する適切な洞察を提供し、ビジネスに関する重要な問題にリアルタイムで回答することが可能となる。
新しいツールは、何百万もの取引からのデータを取り入れ、パフォーマンスや支出をベンチマークとして比較することができる。
・LlaMA 65BをA100 80GB(int8量子化)1台で。
少なくともGPT-3と同等とのこと。
Webui:
・AIとマッチングするサービス
これはまた色んな意味ですごいサービス。マッチングという軸だけでなく色々と展開が広がりそうな試み。
多分元redditはこれかな? https://reddit.com/r/androidapps/comments/11l3evo/i_made_tinder_but_with_ai_anime_girls/…
ダウンロードリンクはおそらくこれ https://play.google.com/store/apps/details?id=com.codecandy.waifu.hot.dates&pli=1

・一般ユーザーは詳細な呪文を書かないだろうから、こういう自動補間モデルやテンプレートや過去データをもとに、詠唱破棄や詠唱短縮が進みそう Teleprompter:プロンプトの自動補間ができるモデル -50,000 の最良のMidjourneyプロンプトで学習
-GPT3とリンクして出力をさらに絞り込みにより実現
-画像:High tech robotにプロンプトを自動拡張して生成した例(投稿者様のスレにもっとあります)
-サイト:http://teleprompter.olafblitz.repl.co
最高。一般ユーザーは詳細な呪文を書かないだろうから、こういう自動補間モデルやテンプレートや過去データをもとに、詠唱破棄や詠唱短縮が進みそう
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 9, 2023
Teleprompter:プロンプトの自動補間ができるモデル
-50,000 の最良のMidjourneyプロンプトで学習
-GPT3とリンクして出力をさらに絞り込みにより実現… https://t.co/vfH00O3NCl pic.twitter.com/orJaKIEBSR
・本命きた! MiroAI
-Mindmap Idea Generation: マインドマップを自動生成
-Summarize Sticky Notes: たくさんの付箋を1つにまとめる -テキストを書くだけでコードを作成
-Image Generation: テキストから画像を作成
-アイデアからユーザーストーリーを生成
など https://miro.com/ai/
本命きた!
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 9, 2023
MiroAI
-Mindmap Idea Generation: マインドマップを自動生成
-Summarize Sticky Notes: たくさんの付箋を1つにまとめる
-テキストを書くだけでコードを作成
-Image Generation: テキストから画像を作成
-アイデアからユーザーストーリーを生成
などhttps://t.co/aqdkV8Oo68 pic.twitter.com/1TZgBQkF9o
・Discordで、Clyde、AutoMod AI、Conversation Summaries、という3つの実験が開始。
また、Avatar Remix、Whiteboard with AI Previewという機能も紹介。 そして、Discord AI Incubatorが発表され開発者等が支援を受けられるとのこと。
各詳細は続)
・RIPビデオエディター
CGキャラクターを実写のシーンに自動でアニメーションさせ、照明や合成を行うAIツール by @WonderDynamics
アーリーアクセスリクエスト: https://wonderdynamics.com
RIP video editors.
— Rowan Cheung (@rowancheung) March 9, 2023
This AI tool automatically animates, lights, and composes CG characters into live-action scenes.
& Steven Spielberg is an advisor 👇 pic.twitter.com/cL44GTZ0en
・Cool Japan Diffusion 2.1.2 をリリース
- Picasso Diffusion ベースになって画質がかなり高くなった
- Picasso Diffusion よりもアニメ、マンガ、ゲームの表現能力が高い
デモ: https://huggingface.co/spaces/aipicasso/cool-japan-diffusion-latest-demo…
モデル: https://huggingface.co/aipicasso/cool-japan-diffusion-2-1-2

研究
・昨日オープンソースとして公開された Flan-UL2 とFlan-T5が比較できるデモ
レポ:http://huggingface.co/google/flan-ul2
スペース: https://huggingface.co/spaces/ybelkada/i-like-flan-ul2

・FLAN-UL2 20Bの@huggingfaceデモ
http://huggingface.co/google/flan-ul2

・セマンティックタイポグラフィ生成
単語の意味を踏まえたイラスト単語画像を自動生成できるらしい
論文: https://arxiv.org/abs/2303.01818
project: https://wordasimage.github.io/Word-As-Image-Page/
Word-As-Image for Semantic Typography
— AK (@_akhaliq) March 6, 2023
abs: https://t.co/WZJcC54oBG
project page: https://t.co/wGc6p7cpPZ pic.twitter.com/fgq7GALR9Q
・各企業等の言語モデルのパラメータ、概要、アクセス制限が一覧されてる https://crfm.stanford.edu/helm/latest/?models=1

・[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithm…
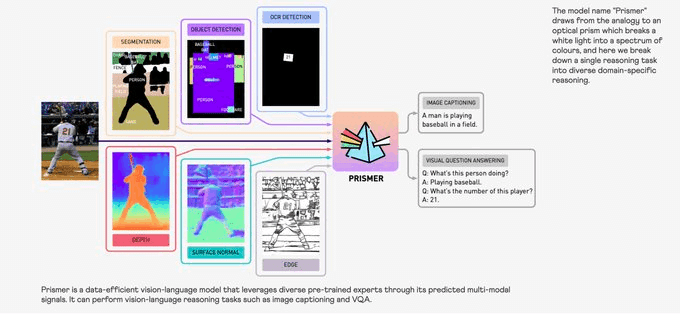
・Prismer: マルチモーダルエキスパートによる視覚言語モデル
異なるタスクに最適化されたエキスパートモデルのアンサンブルを活用して、データおよびパラメータ効率の良い視覚言語モデルを目指す。最大で2桁少ない学習データで、現在のsotaに近いfew shotの推論性能を達成。
論文: https://arxiv.org/abs/2303.02506
プロジェクト: https://shikun.io/projects/prismer…
github: https://github.com/NVlabs/prismer
・StyO:ワンショットで顔のスタイル変換
コードはまもなく
論文:https://arxiv.org/abs/2303.03231

・世界で最も話されている1,000の言語をサポートするAI言語モデルを構築目標の第一歩に当たる「Universal Speech Model(USM)」について
USMは、12,000万時間の音声と300以上の言語にまたがる280億の文に基づいてトレーニングされた20億個のパラメータを持つ、最先端の音声モデル。 YouTubeはすでにUSMを使用してキャプションを生成しており、英語、中国語、アムハラ語、セブアノ語、アッサム語などを含む言語を自動的に検出および翻訳をサポート
https://theverge.com/2023/3/6/23627788/google-1000-language-ai-universal-speech-model…
・Googleが5620億のパラメーターを持つ最大の持視覚言語モデルPaLM-Eを開発
5400億パラメーターのPaLM + 220億パラメーターのViT = 5620億パラメーターのPaLM-E ロボット工学、視覚、および言語にまたがる、汎用的なモデル
詳細はスレッドに続く)
サイト: https://palm-e.github.io
Googleが5620億のパラメーターを持つ最大の持視覚言語モデルPaLM-Eを開発
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 7, 2023
5400億パラメーターのPaLM + 220億パラメーターのViT = 5620億パラメーターのPaLM-E
ロボット工学、視覚、および言語にまたがる、汎用的なモデル
詳細はスレッドに続く)
サイト: https://t.co/64t8XP4lyZ https://t.co/0wdtGRwvAA pic.twitter.com/T3kSfynlVP
・GPTQ論文の手法でLLaMAのモデルを4ビット量子化で軽く
GPTQ論文の手法でLLaMAちゃんのモデルを4ビット量子化で軽くするやつ
— forasteran (@forasteran) March 6, 2023
RTX3090で動作検証w
とはいえLLaMA-13bを量子化するにはCPUメモリ32GB必要で、LLaMA-33bだと64GB以上必要
リークしたし
色んな方法で軽くしたの出回るまで時間の問題な気する🤭 https://t.co/zLQo9EvpKC
・思考の連鎖 (CoT) に関する論文まとめ
https://github.com/Timothyxxx/Chain-of-ThoughtsPapers

・テキスト、画像、3Dポイントクラウドの統合表現を学習するULIPのコードリリース来た!
事前学習済み視覚言語モデルを活用し、自動的に合成された少数のトリプレットを使用して、テキスト画像空間に整合する3D表現空間を学習する。 3Dバックボーンネットワークとして、任意の3Dアーキテクチャに簡単に統合できる。
https://github.com/salesforce/ULIP
テキスト、画像、3Dポイントクラウドの統合表現を学習するULIPのコードリリース来た!
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 7, 2023
事前学習済み視覚言語モデルを活用し、自動的に合成された少数のトリプレットを使用して、テキスト画像空間に整合する3D表現空間を学習する。 https://t.co/AJwksTIgiy… https://t.co/CWv5eq12uD pic.twitter.com/guhAMhcjxj
・GLIGEN :ControlNet x Latent Couple
CVPR 2023の #GLIGEN もまた面白い!
— forasteran (@forasteran) March 7, 2023
ControlNetとLatent Coupleを足したみたいな奴w
🤗[demo] https://t.co/STaVPmEkjG
🔧https://t.co/qn6gFkfum9
↓GLIGEN専用モデルが要るんで、SDの任意モデルで動かせるか不明だけどwebuiで動かしたいね
再学習が要るのかな?https://t.co/DRckr3HLbJ pic.twitter.com/9VBT1CYmXL
・Instagramの共同創業者が新たに立ち上げたニュースアグリゲーター「Artifact」を支える技術
-トップパブリッシャーの選定とユーザーの行動分析を組み合わせた独自の技術で記事の選択を行っており、クリックだけでなく閲覧時間やシェア数などの要素も考慮
-多くのニュースアプリが陥りがちな「フィルターバブル」に陥ることを避け、異なる視点からニュースを提供することを目指す
-将来的には、ユーザーが興味のあるコンテンツを発見し、他の人々と議論するための場所になることを望んでいる
・意思決定の基盤モデルに関しての、課題やツール、技術的背景の紹介
対話、自律走行、医療、教育、ロボット工学などの多様なアプリケーションで重要な、意思決定 x 基盤モデルに関して、プロンプト、最適制御、強化学習などの様々な方法を用いての最近のアプローチを検討し、共通の課題や未解決の問題について議論。
https://arxiv.org/abs/2303.04129

・BigScience ROOTSコーパス
1.6TBの複合多言語データセット
abs: https://arxiv.org/abs/2303.03915
・自分の声で外国語を話す
VALL-Eの拡張版のクロスリンガル音声合成のための言語モデルVALL-E Xを提案。 ゼロショットクロスリンガルテキストから音声合成およびゼロショット音声から音声への翻訳タスクに適用できる。 実験結果は、ソース言語の音声発話をプロンプトとして、ターゲット言語で高品質の音声を生成できることを示し、同時に未知の話者の声、感情、音響環境を保持できた。
論文: https://arxiv.org/abs/2303.03926
プロジェクト(デモなども): https://vallex-demo.github.io

・自然言語処理や視覚言語モデル周りの動向まとめ
技術者研究者寄りだけど、そうじゃない人も流れやまとめだけでも見てみるのオススメ
part1 https://speakerdeck.com/kyoun/deim-tutorial-part-1-nlp…
part2 https://speakerdeck.com/kyoun/deim-tutorial-part-2-vision-and-language?slide=6
・Visual ChatGPT: ビジュアル基盤モデルを使用した会話、描画、および編集
様々なビジュアル基盤モデルを組み込んだ Visual ChatGPT と呼ばれるシステムを構築
1) 言語だけでなく画像も送受信して、ユーザーが ChatGPT と対話できるように
2) 複数の AI のコラボレーションを必要とする複雑な視覚的な質問または視覚的な編集指示を提供
3)フィードバックを提供し、修正結果を求める https://arxiv.org/abs/2303.04671

・クロスアテンション制御を備えた実世界のビデオ編集のための新しいフレームワークであるVideo-P2P
元のポーズやシーンを最適に維持しながら、新しいキャラクターを生成するための現実世界のビデオでうまく機能
コードは後ほどリリース
abs: https://arxiv.org/abs/2303.04761
プロジェクト: https://video-p2p.github.io
Video-P2P: Video Editing with Cross-attention Control
— AK (@_akhaliq) March 9, 2023
Video-P2P works well on real-world videos for generating new characters while optimally preserving their original poses and scenes
abs: https://t.co/tmQ117b9kg
project page: https://t.co/8KBPCbsqm4 pic.twitter.com/xPTphofkKk
・プロンプトインジェクション対策について
・BingGPTっぽいやつ作るためのアイデア
・TRL + PEFTにより、24GB GPUを使用してRLHFで20B 言語モデルをチューニング可能に
トランスフォーマー言語モデルを強化学習できるTRLと、大規模言語モデルの下流タスクチューニングができるPEFTにより。
stepはスレッドに続く)
・ZoeDepthという深度推定のデモが公開
デモ:
・レイアウト指定画像生成のGLIGENがコード公開したそう
github: http://github.com/gligen/GLIGEN
Demo: http://huggingface.co/spaces/gligen/demo
・テキスト画像生成のためのGANのスケールアップ
- 1B パラメータ
- 0.13 秒で 512 ピクセルの出力を生成と推論時の処理速度が数桁速い
- 1600万画素を3.66秒で合成するなど、高精細な画像を合成することが可能
proj: https://mingukkang.github.io/GigaGAN/
abs: https://arxiv.org/abs/2303.05511

・3DGen: テクスチャメッシュ生成
単一のGPUで、高品質のテクスチャ付き/なしの3Dメッシュを数秒で条件付き/無条件に生成できる テクスチャ生成だけでなく、メッシュの品質に関しても、画像条件付き生成/無条件生成で先行研究を上回る
コードと学習済みモデルを後ほど
https://arxiv.org/abs/2303.05371

・LLMプロンプトパターンカタログ
ソフトウェア開発を自動化するためのプロンプトパターン
-アウトプットのカスタマイズ -プロンプト改善
-エラー識別
-入力セマンティクス
-コンテキストコントロール
-インタラクション
https://arxiv.org/abs/2302.11382

この記事が気に入ったらサポートをしてみませんか?