
Googleスプレッドシート SPLIT関数/TEXTJOIN関数 超応用例

Googleスプレッドシートの関数超応用例シリーズ、今回は SPLIT関数、TEXTJOIN関数をセットで取り上げます。
どちらも非常に使い勝手の良い関数ですが、この2つはそれぞれ学ぶよりもセットで覚えた方がより効率的です!是非活用できるようになりましょう。
前回は Googleスプレッドシートの行・列のグループ機能について書きました。
※グループ内へドラッグで行を移動させた時のクセのある挙動について書き漏れていたので追記しました。
追加部分↓
グループにグループ外の行をドラッグすると変なことになる
テキストを分割する SPLIT関数、テキストを連結するTEXTJOIN関数
普通に使ってる人も多いかと思いますが、この2つの関数を簡単に説明すると
SPLIT関数
区切り文字で テキストを分割して 配列にする関数
TEXTJOIN関数
区切り文字で 配列(セル範囲)を連結して一つのテキストにする関数
こんな仕様の関数です。
逆の動作となるんで、対になる関数と言ってよいかと思います。
まずはそれぞれの関数の基本動作を学んでいきましょう。
テキストを分割 SPLIT関数の基本
SPLIT関数はかなり便利なんで、使う機会も非常に多い関数です。しっかり理解しましょう!
SPLIT関数の基本(第1引数、第2引数)
SPLIT(テキスト, 区切り文字, [各文字での分割], [空のテキストを削除])
SPLIT関数は4つの引数をとります。
第1引数のテキスト、第2引数の区切り文字は必須で、第2引数で指定した区切り文字(文字列)で、第1引数のテキストを分割して複数セルに展開する関数です。
第1引数はセル参照とするケースが多いです。
分割された結果は、式を入れたセルから横方向(右)に展開されます。いわゆるスピルする関数ですね。
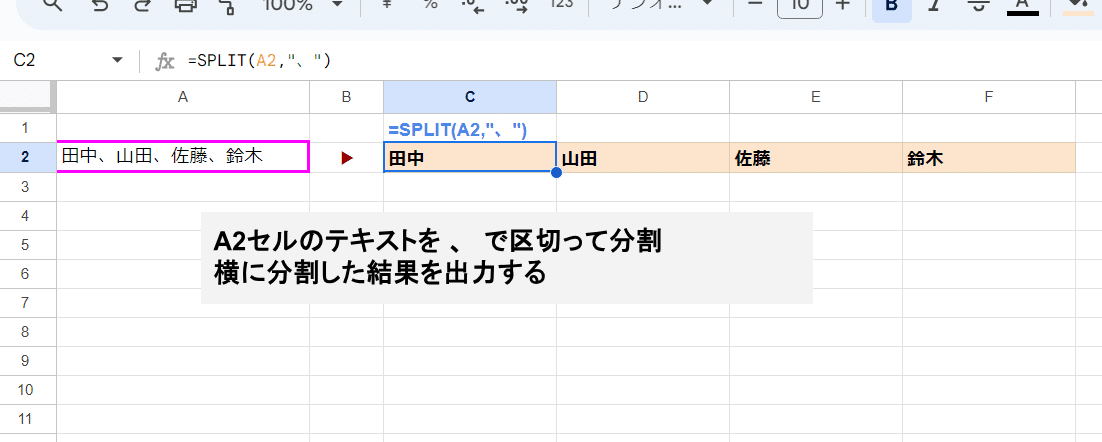
たとえば上の例だと、
第1引数
A2セルの「田中、山田、佐藤、鈴木」というテキスト
第2引数
"、"(文字列指定なので""で括る)
と指定しているので、田中、山田、佐藤、鈴木 を 、で区切った結果が式を入れた C2セルを起点に 横(右)方向に展開されています。
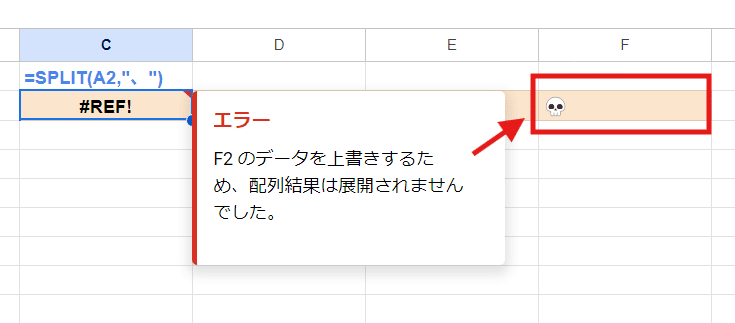
当たり前ですが、展開されるセル範囲に値が入っているとエラーになります。

また、第1引数が空の(空白セルを指定している)場合や、第2引数を省略、空、空文字とした場合もエラーとなります。
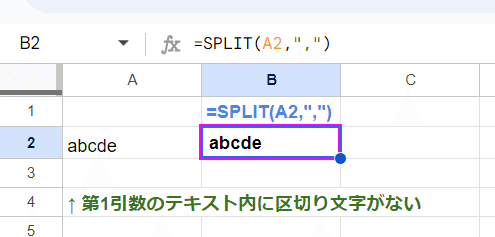
第1引数のテキスト内に 第2引数で指定した区切り文字が無い場合はエラーにはならず、そのまま第1引数が返ります。
SPLIT関数の基本 (第3引数FALSEで 文字列で区切る)
SPLIT関数では第2引数の区切り文字は、基本的には単文字(一文字)を想定しています。
その為、第2引数で 1文字以上の文字列を指定した場合は、一つの文字列としては扱われず、単文字を区切り文字として複数指定したと見なされます。
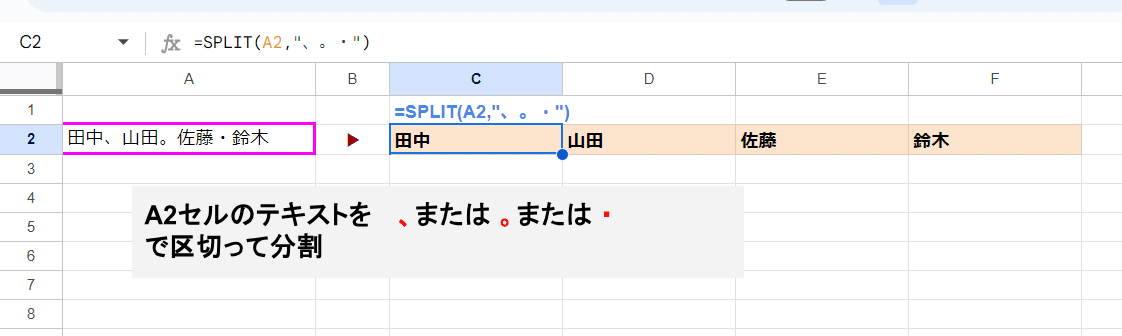
たとえば 上の画像のように
=SPLIT(A2,"、。・")
このように第2引数を "、。・" と指定した場合、これは
「、」 または 「。」 または「 ・」 で区切る
という指定になります。
その為、たとえば
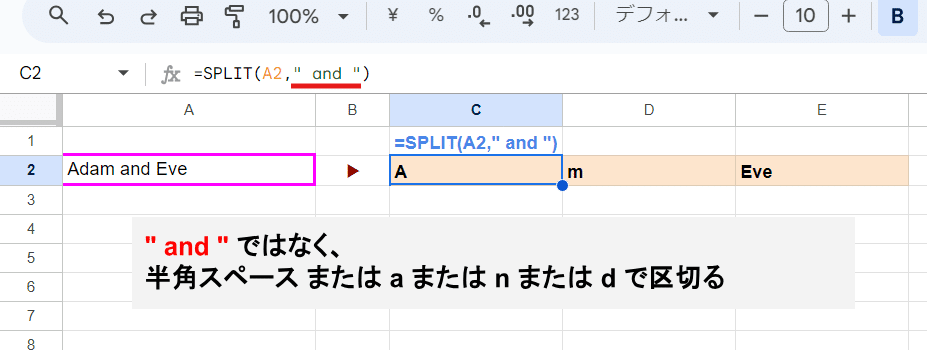
こんなケースで、 " and " という単語(文字列)で区切ろうと思って =SPLIT(A2," and ") としても、
半角スペース、a、n、d
で区切られてしまい上のような結果となります。
この第2引数が1文字以上の場合に「文字列」を区切り文字として扱えるように指定するのが 第3引数です。
各文字での分割 - [省略可 - デフォルトは TRUE] -
公式を見るとこのようになっているので、
第3引数をFALSE指定
▼
各文字で分割しない
▼
第2引数を 一つの文字列として扱う
ということですね。
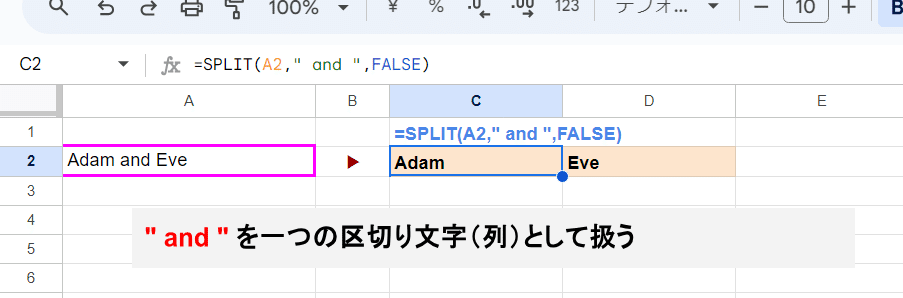
このように =SPLIT(A2," and ",FALSE) と 第3引数をFALSE指定することで、第2引数を一つの区切り文字列として指定して 分割できました~。
※ "and" だと 区切られた後の単語の前後に半角スペースが残ってしまうので " and " と前後にスペースを入れた指定をしています
ちなみに =SPLIT(A2," and ") だと第3引数省略で TRUE扱い(各文字で分割する)なんですが、
=SPLIT(A2," and ",) だと第3引数に空白を指定した(FALSE扱い)となります。
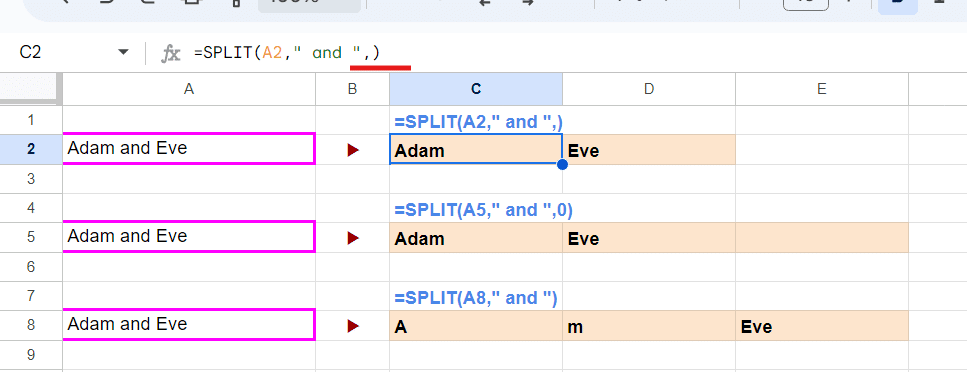
通常はきちんと FALSE を記述した方がわかりやすいので多用はおススメしませんが、一文字を争う数式勝負の時は 関数を短くするのに効果的です。(そんな勝負はないと思いますが・・・)
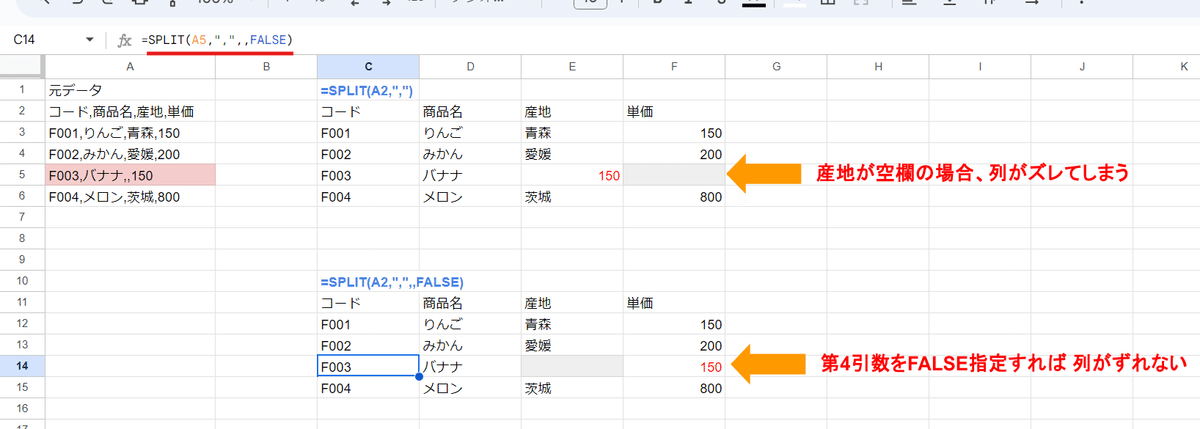
SPLIT関数の基本(第4引数で 空白セルを詰めない)
第4引数は
空のテキストを削除 - [省略可 - デフォルトは TRUE]
- SPLIT の結果から空のテキスト メッセージを削除するかどうかを指定します。デフォルトは TRUE で、連続する区切り文字を 1 つの区切り文字として扱います。FALSE にすると、連続する区切り文字の間に空のセルの値が追加されます。
公式ではこのような説明があります。
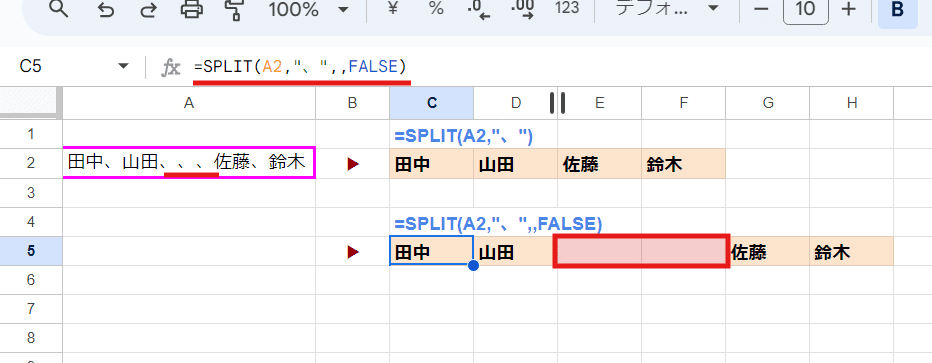
簡単に言えば、こんな感じで 第1引数のテキスト内で 区切り文字(、)が連続する箇所があった場合にその部分を空セルとして出力するかどうかの切り替えで、
第4引数を省略(または TRUE指定)
▶ 区切った後空白になるセルは無視される
第4引数を FALSE指定
▶ 区切った後空白になるセルも残す
このような違いがあります。
これは、カンマ区切りの CSVデータで 値無しのケースがある場合の 列のズレを防止する際に活用したり
次週触れますが、空の配列を生成する時に活用できます。
SPLIT関数の代替機能
Googleスプレッドシートには、SPLIT関数に類似する関数はありません。
ケースによっては MID関数や REGEXEXTRACT関数で代替できることもありますが、基本的には
セルを 分割したい ▶ SPLIT関数を使おう
という理解で良いです。
また、関数ではありませんが 「テキストを列に分割」という機能があり、これはSPLIT関数のようなことが出来ます。
使い方は 分割したい列を選択して、
データ > テキストを列に分割 をクリック
簡単ですね。
ただし、カンマ区切りなどの場合には、サクッと希望通りに分割されですが、特殊な区切り文字を指定したい場合は少し面倒です。
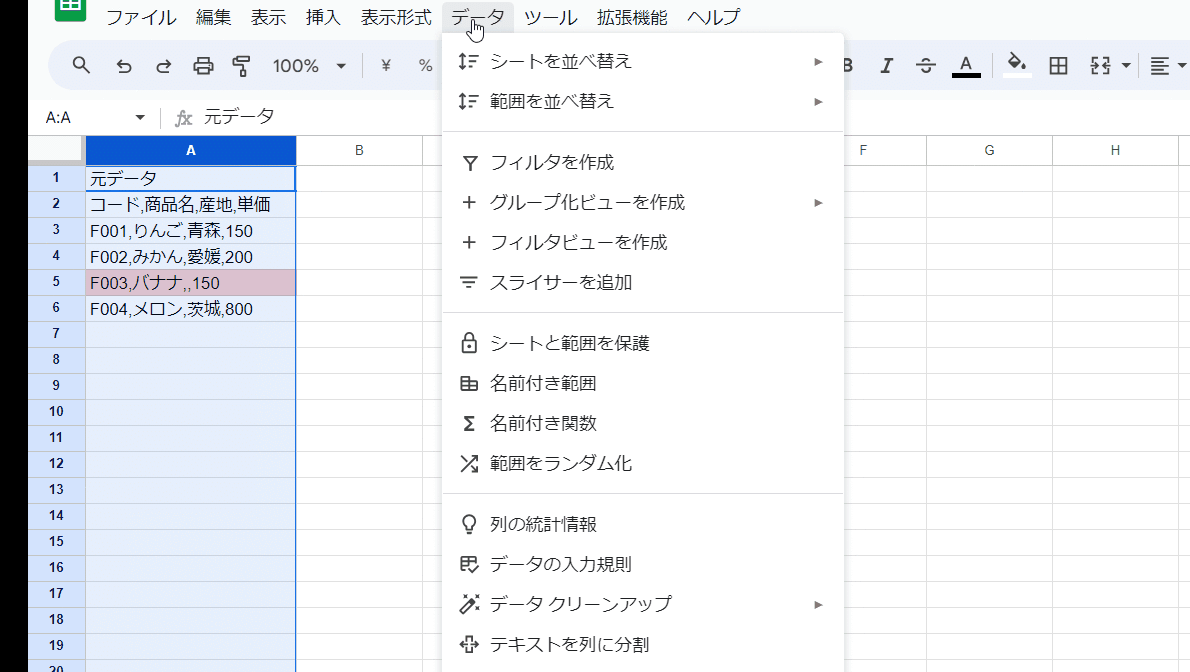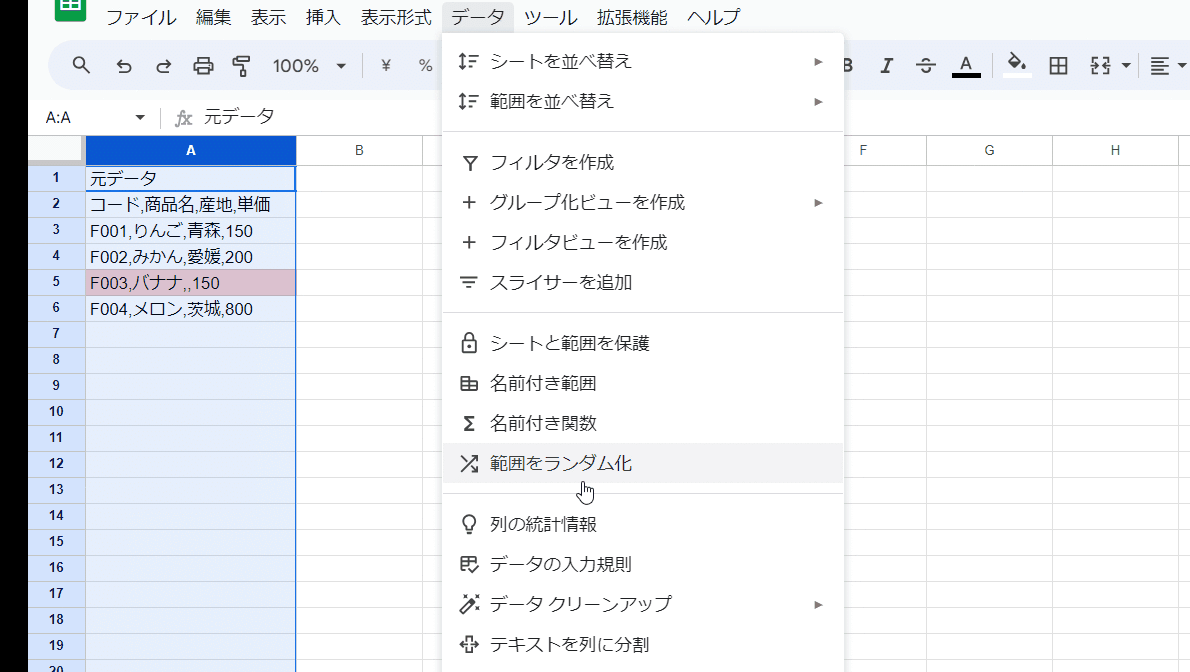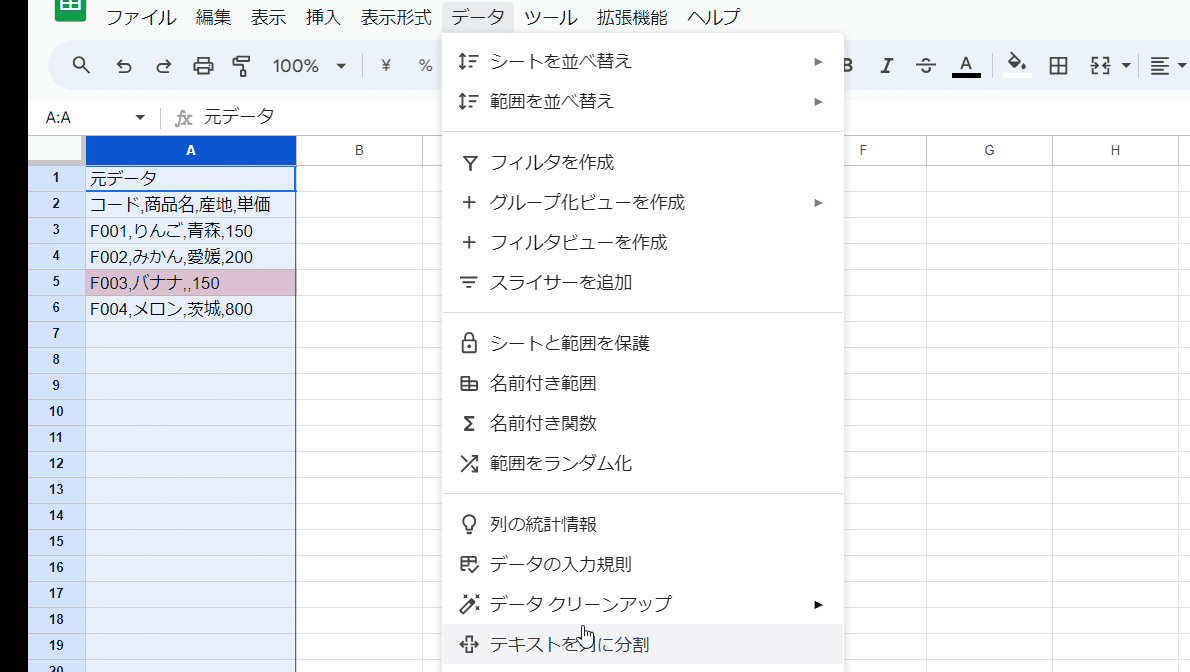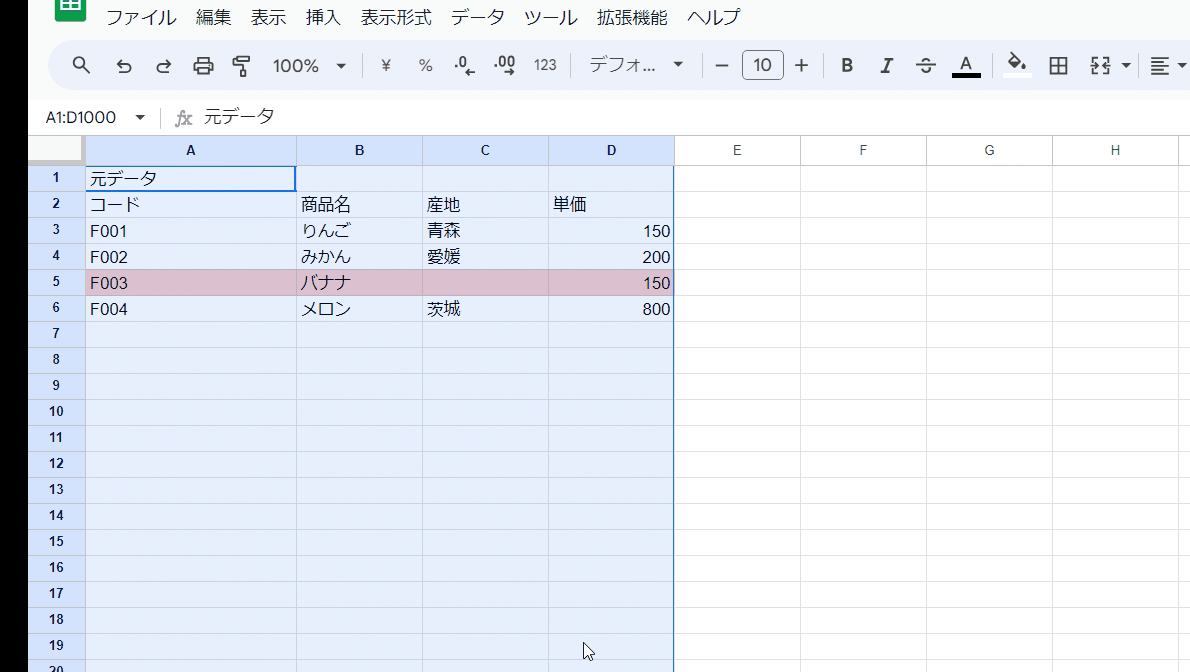
また、空白を無視するや複数の区切り文字指定など高度な条件設定は出来ません。
元データを破壊してしまうのも少し怖いですよね。
区切り文字による分割は、SPLIT関数を使うことをお勧めします。
Googleスプレッドシートの SPLIT関数と Excelの TEXTSPLIT関数
ちなみに Excelには SPLIT関数を改良したような TEXTSPLIT関数があります。
こちらは以前 noteで取り上げています。
=TEXTSPLIT(text,col_delimiter,[row_delimiter],[ignore_empty], [match_mode], [pad_with])
text ・・・分割するテキスト。通常はセル指定。
col_delimiter ・・・ 横(列方向)の区切り文字
row_delimiter ・・・ 縦(行方向)の区切り文字 (省略可)
ignore_empty ・・・ 空のセルを削除するか?
(TRUEで削除する、FALSEで削除しない。省略時は FALS)
match_mode ・・・ 大文字と小文字を区別するか?
( 0で区別する。 1で区別しない設定 省略時は 0)
pad_with ・・・ 空きセルを埋める文字。省略時は #N/A
このように引数が 6つもある関数なんで、これだけでも SPLIT関数とは互換性が無さそうって感じますよね。
Googleスプレッドシートの SPLIT関数と Excelの TEXTSPLIT関数ですが、ざっくり比較をまとめてみました。
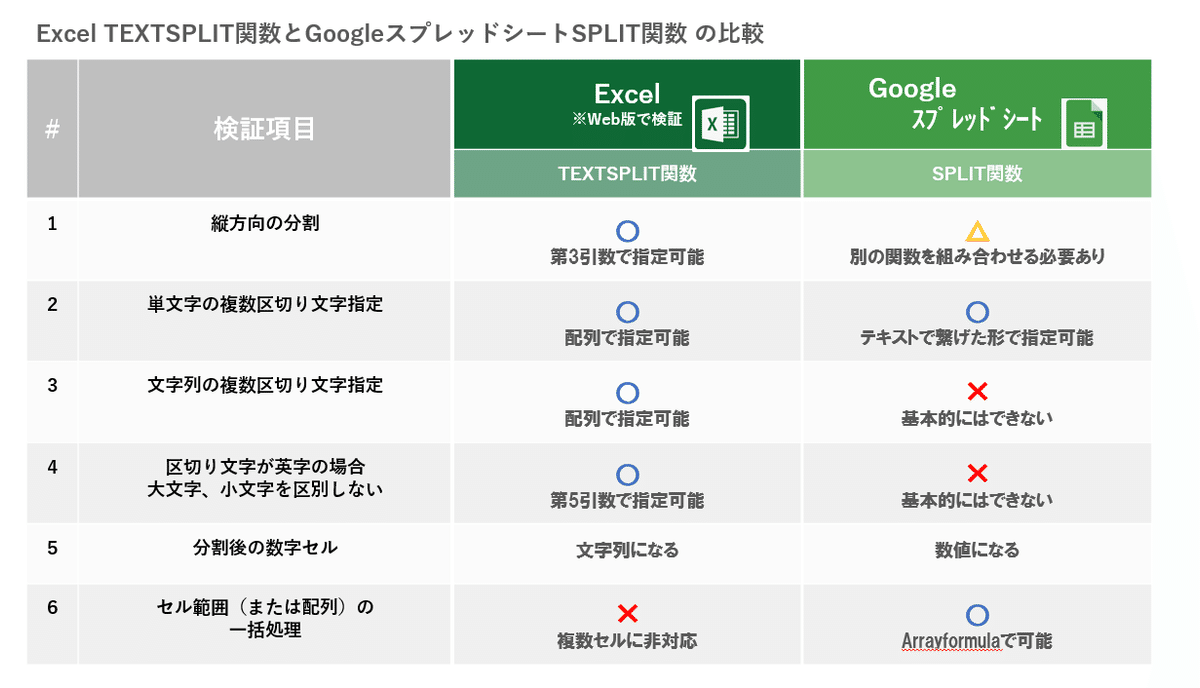
TEXTSPLIT関数は、横方向の区切り文字に加え、縦方向の区切り文字が指定できたり、区切り文字が配列指定であることから、複数の区切り文字列を指定できたり、 さすが後から出してきただけあって 機能マシマシって感じです。
これ以外にも ExcelのTEXTSPLITは 分割後の空白セルの無視は指定なしだとFALSE(無視しない)だったりと、細かい違いがあります。
また、分割後の数字セルの扱いも違っていて
GoogleスプレッドシートのSPLIT関数は強制的に結果に数字のみのセルがあった場合は数値化されますが、
ExcelのTEXSPLIT関数の場合は数字のみのセルも文字列となります。
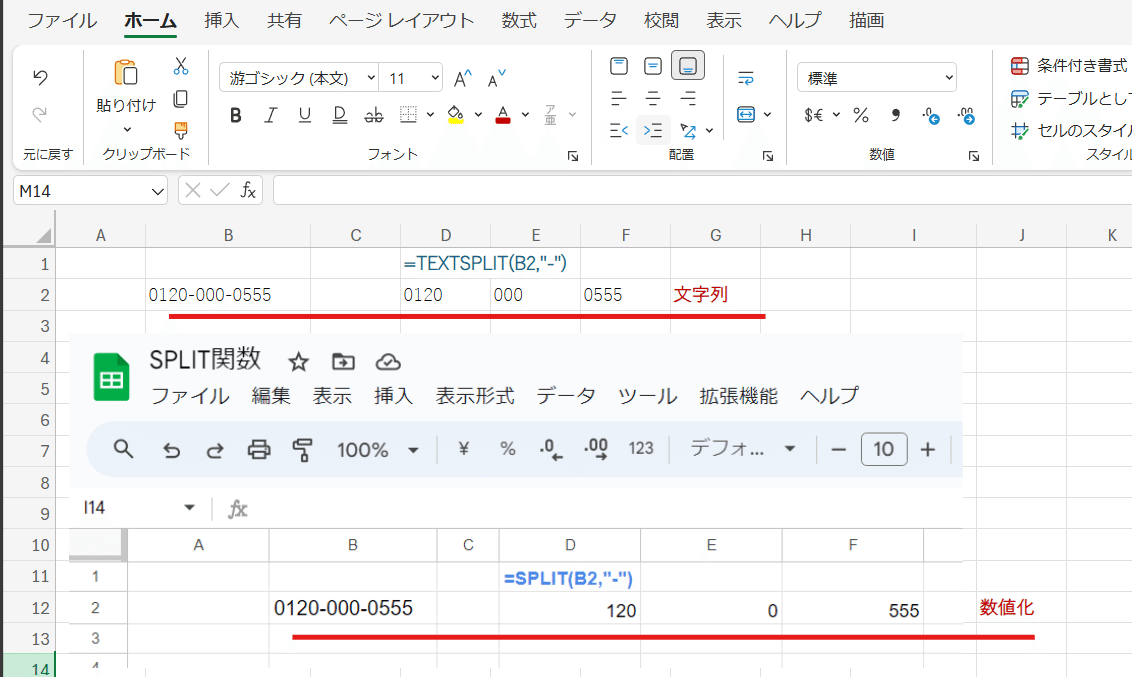
どっちが良いというのはありませんが、消えてしまう0を復活させる一手間よりは、文字列の数字を数値化する方が簡単なんだよなーと思うこともw
このように 色々利点の多いTEXTSPLIT関数ですが、一番下の比較項目 「セル範囲(または配列)の一括処理」が出来ません。これが結構痛い。
一方、SPLIT関数は ARRAYFORMUAL関数と組み合わせることで、1列の複数セルを対象に一括で分割することが可能です!
mir的にはここのポイントは結構大きいんで、一概に TEXTSPLITがSPLIT関数の上位互換とは言えないと考えます。
SPLIT関数 と ARRAYFORMULA関数
SPLIT関数の超便利ポイント、ARRAYFORMULAと組み合わせて 複数セルを一気に分割てきる。
この具体例をみていきましょう。
ARRAYFORMULAと組み合わせて一括分割
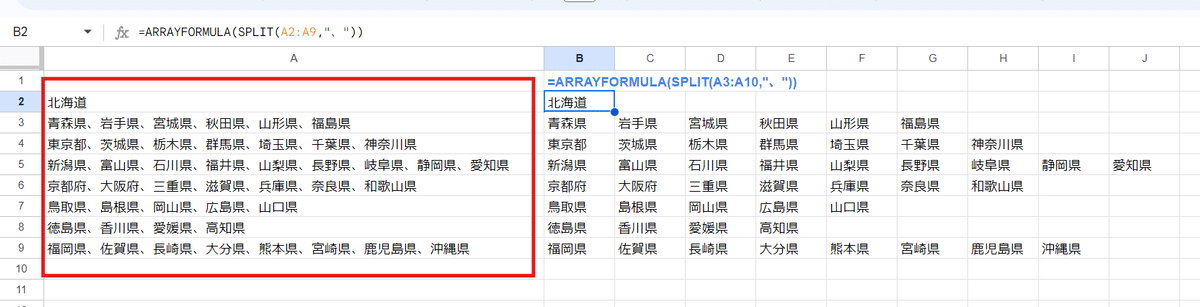
たとえば 上のようにエリアごとに都道府県が 、で区切られたデータが A2:A9 に入っていた場合、
=ARRAYFORMULA(SPLIT(A3:A10,"、"))
このように第1引数を セル範囲として、さらに外側にARRAYFORMULA関数を組み合わせることで、複数セルを一つの式で分割することが出来ます。
ARRAYFORMULAと組み合わせた際は、SPLIT関数の基本でも触れましたが、第1引数が空白(空のセル)だった時にエラーとなる点に注意が必要です。
つまり、Googleスプレッドシートでやりがちな、 A2:A のような範囲指定をした場合は
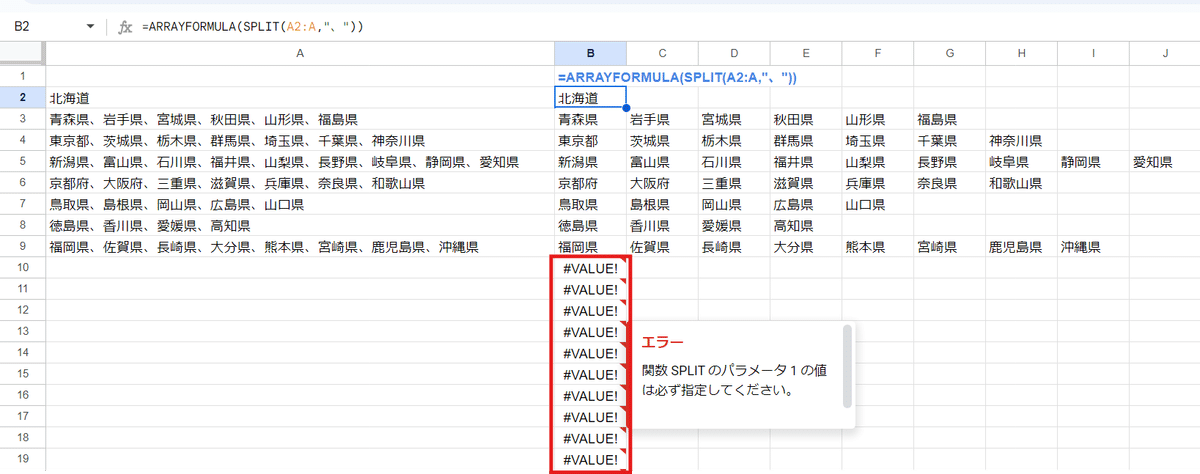
このようにデータが無い行は #VALUE!エラーを返してしまいます。
これを回避する為に、第1引数に空白セルを含む可能性がある場合は、
=ARRAYFORMULA(IFERROR(SPLIT(A2:A,"、")))
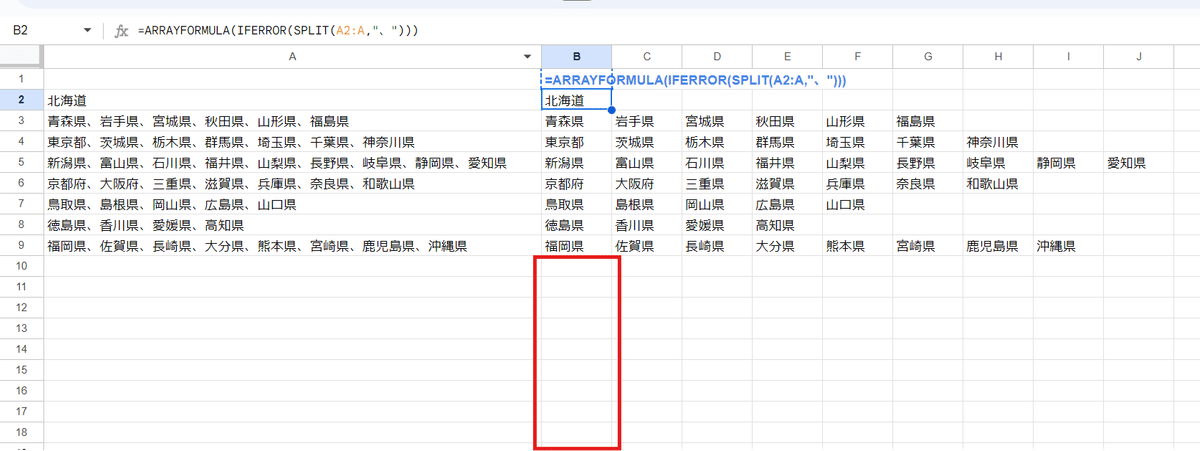
IFERROR関数を組み合わせて回避しましょう。
結果の配列は 長方形であることに注意
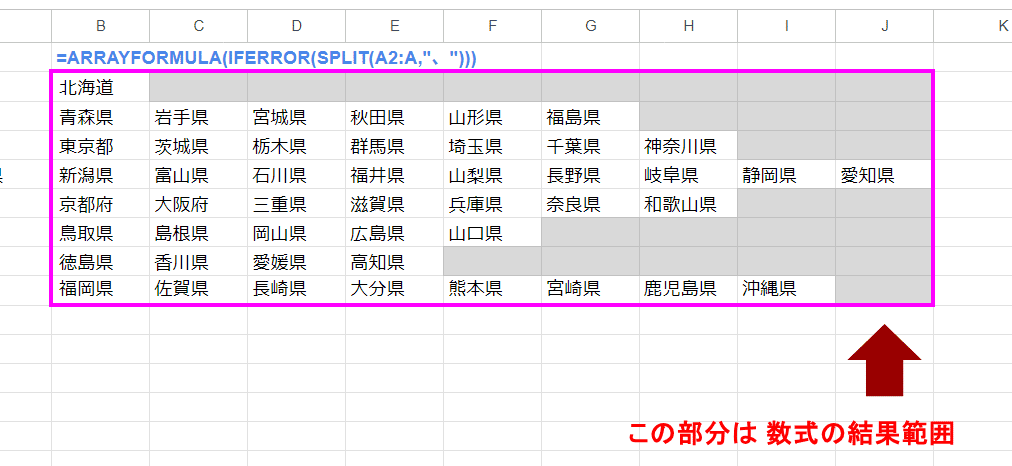
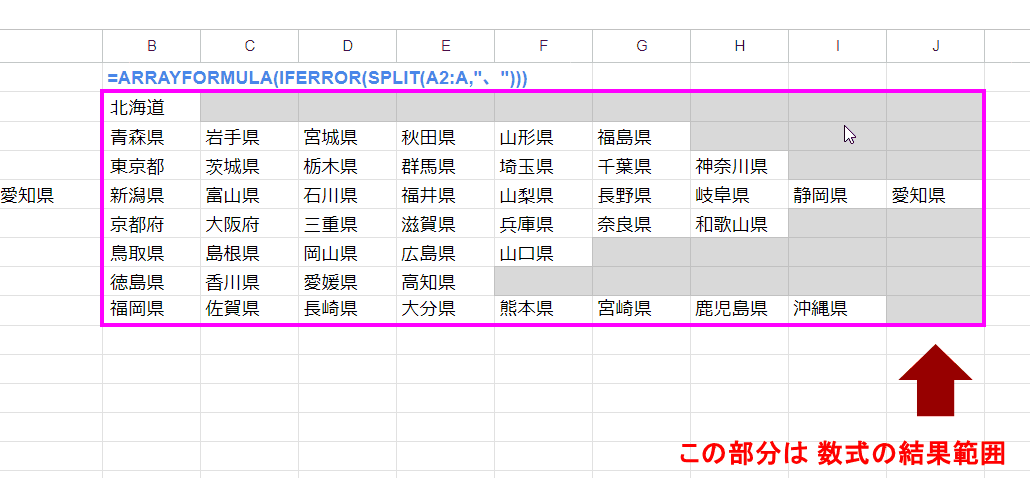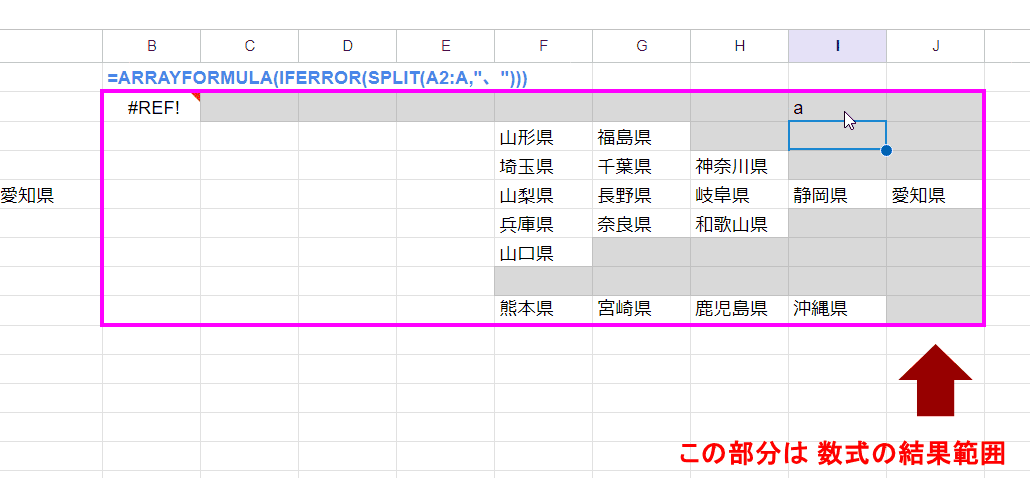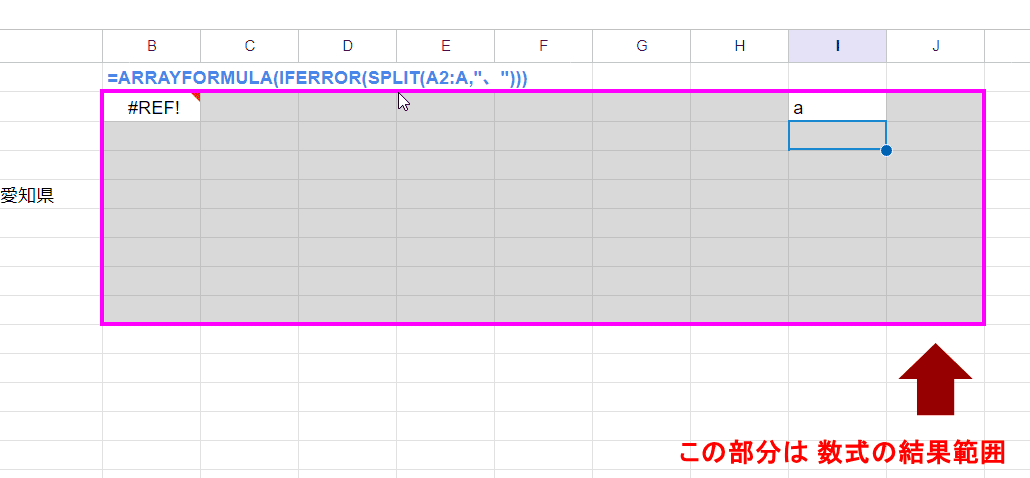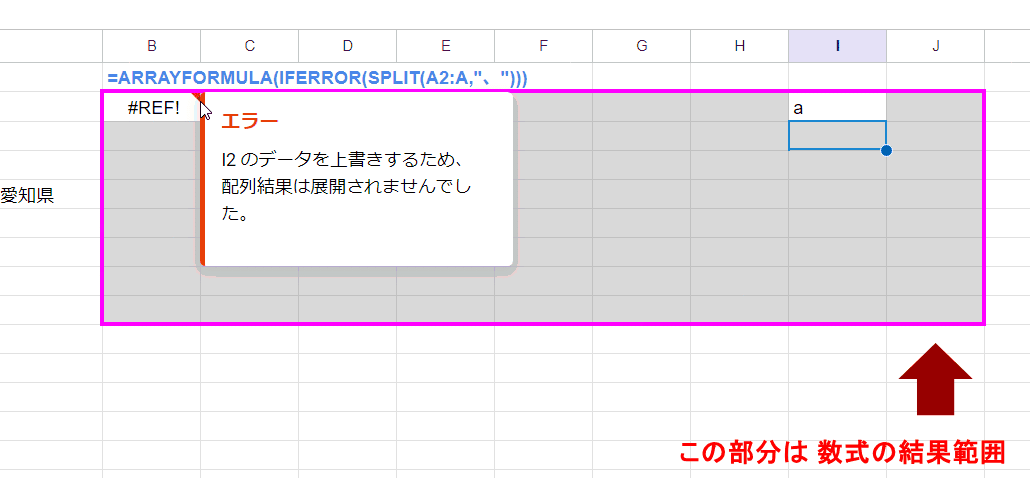
ARRAYFORMULA + SPLIT関数の結果は、このように行毎にサイズがバラバラとなっているように見えます。
一見、北海道の行(1行目)は C列~J列は 空なんで、数式の結果が入っていないセルのように見えますが、そうではありません。
シートに出力される配列は長方形になっているとイメージしていください。
上の場合は、最大数に分割された中部地方の 9を 列数とする 8行9列の B2:J9が数式の結果が出力された範囲となっています。
つまり、空いてるように見えるセルでも 手入力で値を入れてしまうと・・・
このように結果が展開できず、 #REF!エラーとなります。
複数列の範囲は基本的には ARRAYFORMULAで一括分割できない
ARRAYFORMULA + SPLIT関数で 複数セルの一括分割が出来ると書きましたが、基本的には第1引数に指定できるセル範囲は縦1列のデータだけです。
SPLIT関数は結果が横に展開する為、複数列(横並び)のセル範囲を第1引数に指定しても
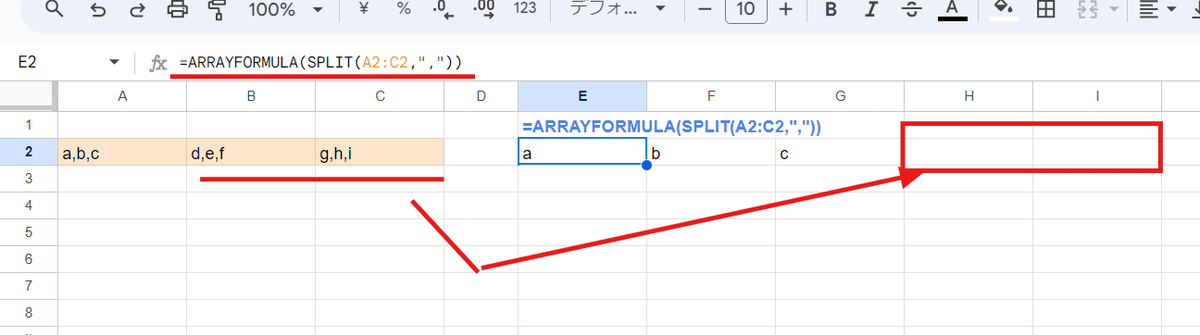
このように、先頭セル以外は SPLIT関数が効きません。
ただし、これは回避方法があります。これも次回、お題形式で触れたいと思います。
意外と第2引数でもスピルする
第1引数を範囲(配列)指定してスピらせるのが一般的ですが、実は第2引数の区切り文字も配列指定でスピらせることができます。
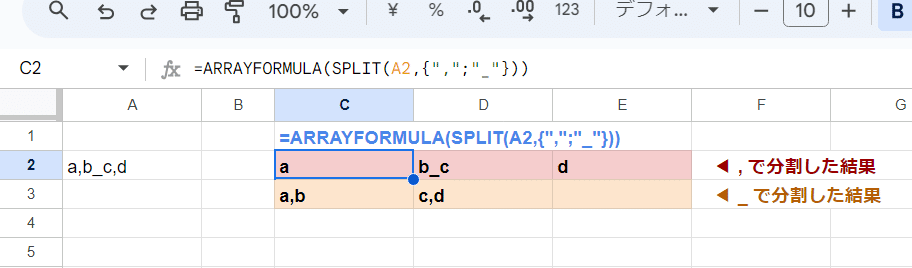
=ARRAYFORMULA(SPLIT(A2,{",";"_"}))
ポイントは 第2引数の区切り文字の配列は {",","_"} と横ではなく {",";"_"} と縦配列にすること。
先ほど触れた通り、結果の展開方向と重複するのはNGだからです。
この式では、1行目に , で区切った結果、2行目に _ で区切った結果が出力できていますね。
でも、ぶっちゃけこんな式を必要とするケースはほぼ無いですw 無駄知識ですが、気になる方は頭の片隅にでも入れておいてください。
ARRAYFORMULA関数については、少し前にnote 超応用例シリーズで詳しく取り上げています。
テキストを連結 TEXTJOIN関数の基本
続いて逆の処理である 区切り文字で複数のテキストを連結する TEXTJOIN関数を見ていきましょう。
TEXTJOIN関数の基本
TEXTJOIN(区切り文字, 空のセルを無視, テキスト1, [テキスト2, ...])
TEXTJOIN関数は、第1引数で区切り文字(連結文字)、第2引数で空のセルを無視するかどうかを指定して、第3引数以降のテキストを区切り文字を挟んで連結した 一つのテキストを結果として返します。
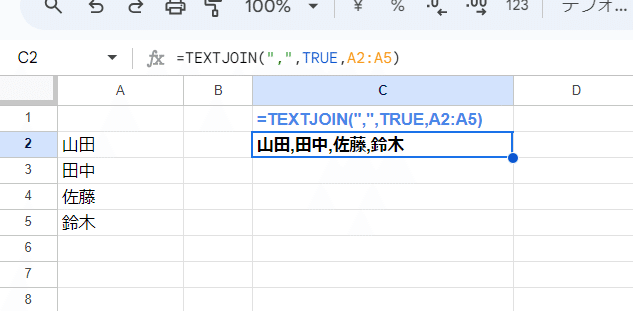
=TEXTJOIN(",",TRUE,A2:A5)
基本的には 第2引数は TRUE指定で、第3引数にはセル範囲を指定するケースが多いです。
上は A2:A5の人名が入ったセルを第3引数に指定して、"," で連結した例です。
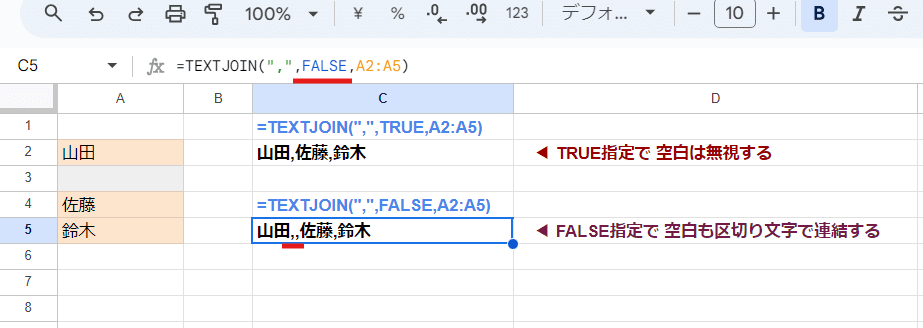
もし、第3引数で指定した範囲内に空白のあるセルを含む場合は、第2引数をFALSEとすると、その部分も区切り文字で連結した結果が返ります。
あとで再度SPLITする際など、たまーにこれを使うことがありますが、基本はTRUE指定だと思っておいてOK。
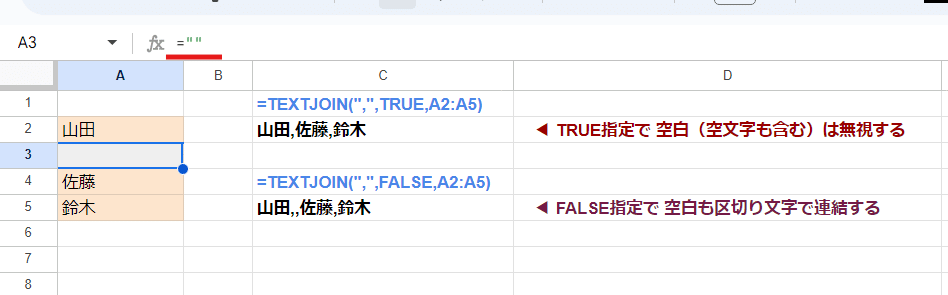
TEXTJOINの第2引数 TRUE指定は、空白だけでなく 空文字も無視します。この仕様はTOROW、TOCOLとちょっと違いますね。
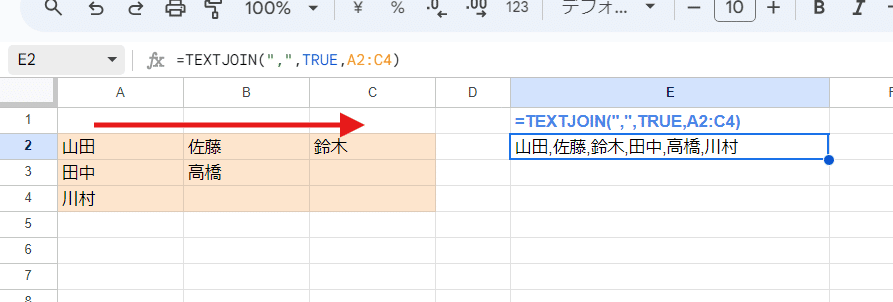
第3引数以降ですが、複数行、複数列のセル範囲(二次元配列)を指定することも出来ます。
この場合は 横方向を優先してスキャンします。この挙動は TOCOLやTOROWと一緒ですね。
残念ながらスキャン方向を引数で切り替えることは出来ません。
SPLIT関数と違って 第1引数の区切り文字は必ず指定する必要はなく、
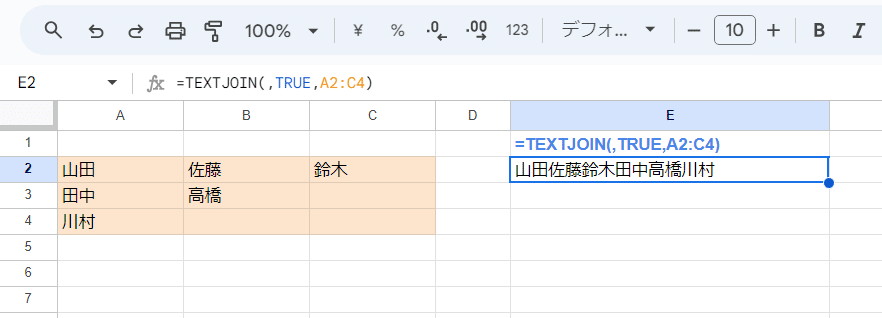
=TEXTJOIN(,TRUE,A2:C4)
または
=TEXTJOIN("",TRUE,A2:C4)
第1引数を空、もしくは空文字とすることで、区切り文字なしで範囲を連結することができます。
TEXTJOIN関数とARRAYFORMULA
TEXTJOIN関数は、標準で第3引数以降に セル範囲をとれる関数であるため、RRAYFORMULAと組み合わせて 行毎に TEXTJOINといったことは出来ません。
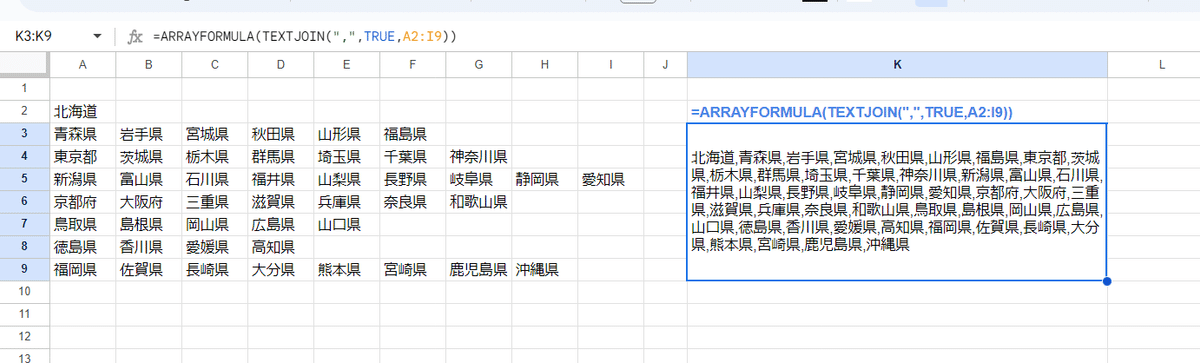
普通に範囲を全て連結した1つの結果が返るだけです。
じゃあ第1引数の区切り文字を配列指定できないのか?
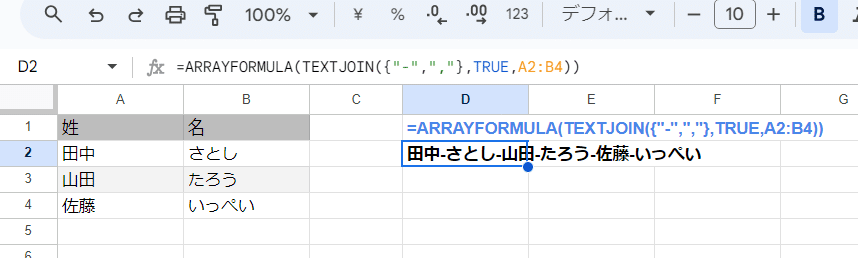
残念ながらこちらも出来ません。
このように 第1引数を配列指定して ARRAYFORMUALと組み合わせても変化はなく 配列の1つ目のみが 区切り文字として扱われるだけです。
TEXTJOIN関数は、ARRAYFORMULAが効かない関数ってやつですね。
ExcelのTEXTJOIN関数との比較
TEXJOIN関数はExcelにも Excel2019から存在する関数です。
GoogleスプレッドシートのSPLIT関数とExcelのTEXTSPLIT関数は、関数名、引数、挙動と 色々違いありましたが、TEXTJOIN関数は 基本的には GoogleスプレッドシートとExcelで大きな違いはありません。
同じ感覚で使える関数と思ってOKです。
あまり気にするポイントではありませんが、Excelの場合は第3引数以降の連結するテキスト引数は 最大 252 という上限があります。
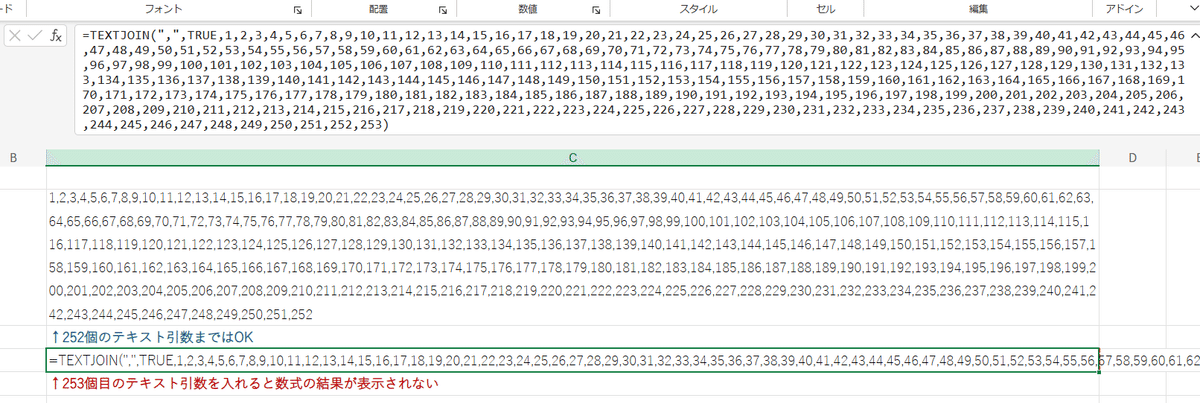
一方、GoogleスプレッドシートのTEXTJOINの場合は、この引数の上限はなさそうです。

まぁ引数を大量指定するような使い方はあまり無いと思いますが・・・。
またTEXTJOIN関数でGoogleスプレッドシートでは出来なくて、Excelだと出来る独特な挙動に、
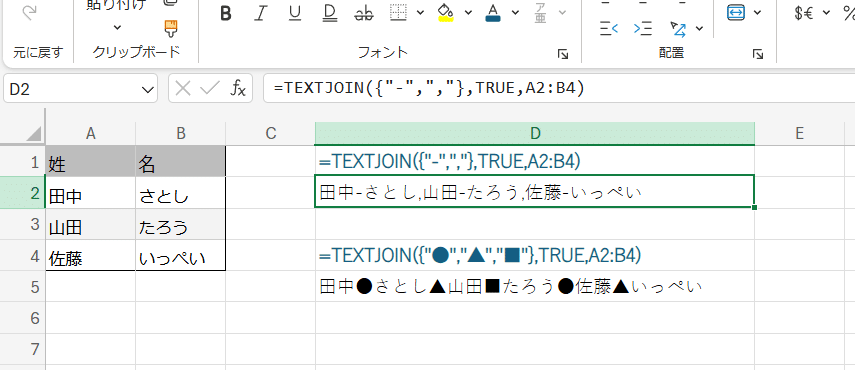
=TEXTJOIN({"-",","},TRUE,A2:B4)
とか
=TEXTJOIN({"●","▲","■"},TRUE,A2:B4)
こんな感じで第1引数の区切り文字を配列指定できるという点があります。
配列で指定した文字は、順番にループしながら区切り文字として使われます。
あまり使う機会は無さそうですが、面白い挙動ですね。GoogleスプレッドシートのTEXTJOIN関数だとこれは出来ません。
TEXTJOIN関数の類似関数
Googleスプレッドシートには TEXTJOIN関数に近い挙動の関数(演算子)が幾つかあります。
JOIN関数
CONCAT関数
CONCATENATE関数
演算子&(アンパサンド)
TEXTJOIN関数と比較しながら見ていきましょう。
1. JOIN関数
JOIN(区切り文字, 値または配列1, [値または配列2, ...])
TEXTJOIN関数の廉価版って感じの関数です。
大きな違いとしては
空白を無視の指定が出来ない
1行データ、または1列データのみを対象とし 複数行複数列は不可
この2点。
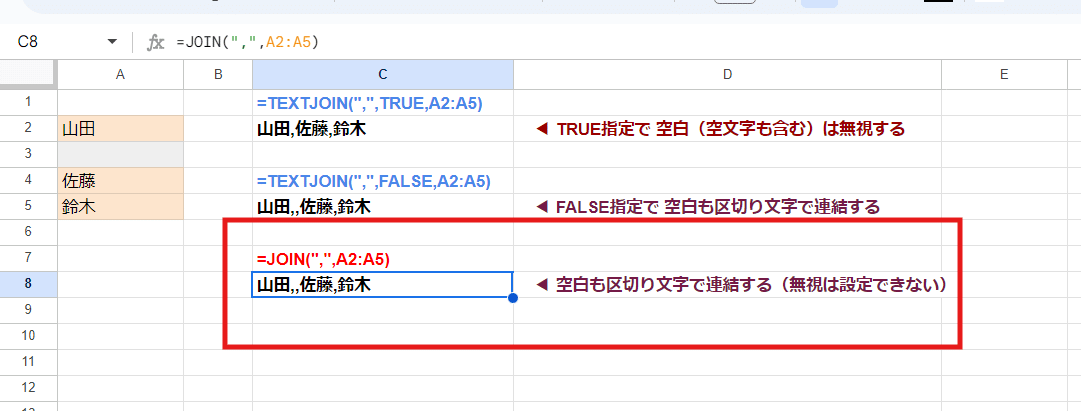
JOIN関数は空白を無視するといった指定が出来ません。
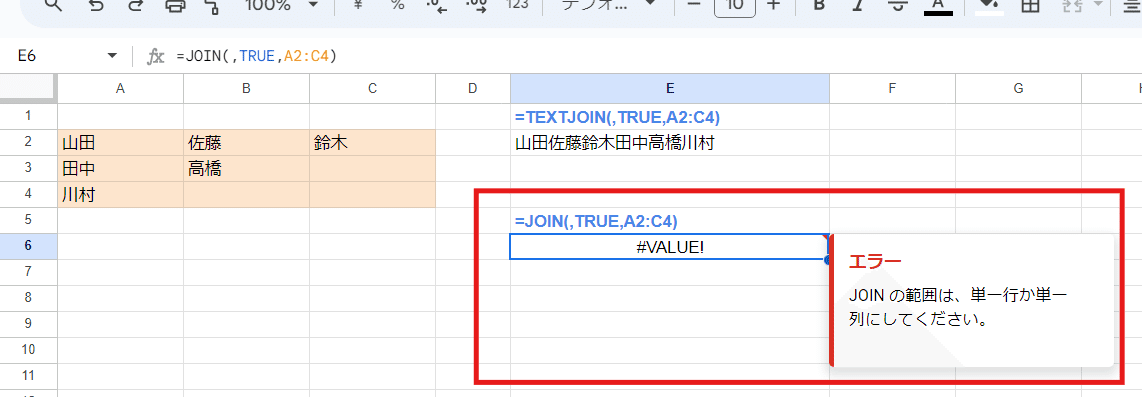
また、複数行複数列のセル範囲に対しては、JOIN関数が使えません。
第2引数以降のテキスト引数は1列、または1行データ(一次元配列)のみとなります。
JOIN関数は、TEXTJOINよりちょっと関数名が短いくらいしか取り柄がない関数かなと。
ムリに使う必要はありませんね。
2. CONCAT関数
CONCAT(値1, 値2)
GoogleスプレッドシートのCONCAT関数は、ExcelのCONCAT関数とは別モノです。
公式ヘルプにも記載がりますが、ぶっちゃけ 演算子の & と一緒、いや&の方が連続で複数連結出来て自由度が高い分、 &の劣化版と言えます。
これに近い Excelの関数は CONCATENATE関数ですが、あちらは2つ以上の引数をとれるんで、Googleスプレッドシートの CONCAT関数は、さらに劣化版と言えます。
2つの引数を連結するだけですし、これを使う機会はほぼ無いと思ってOKです。
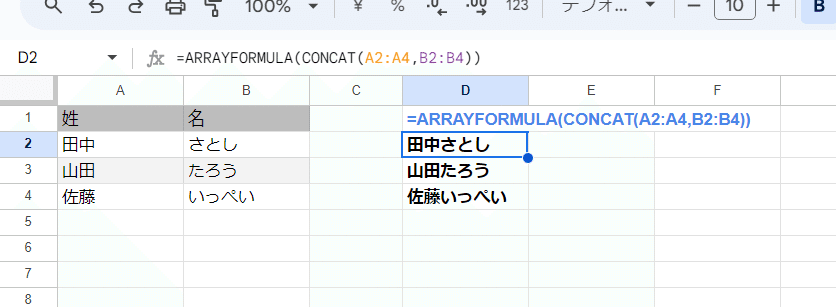
一応 ARRAYFORMUALが効く関数(演算子)ではありますが、これだって &で書いた方が短いです。
=ARRAYFORMULA(CONCAT(A2:A4,B2:B4))
↕ 同じ
=ARRAYFORMULA(A2:A4&B2:B4)
使う必要はありませんが、「ExcelのCONCATとは違うのだよ。」ということだけ覚えておいた方がいいかも。
3. CONCATENATE関数
CONCATENATE(文字列1, [文字列2, ...])
Googleスプレッドシートだと CONCATENATE関数が、ExcelのCONCAT関数に該当します。
そうです、ほぼ関数名と仕様が逆なんです・・。
単に輸入の際にGoogleの担当者が間違えたんでは??って思いますよね。
互換性の部分で紛らわしいのと、CONCATENATEっていう長い関数名(しかもスペルミスしやすい)のせいで、どうも好きになれませんw
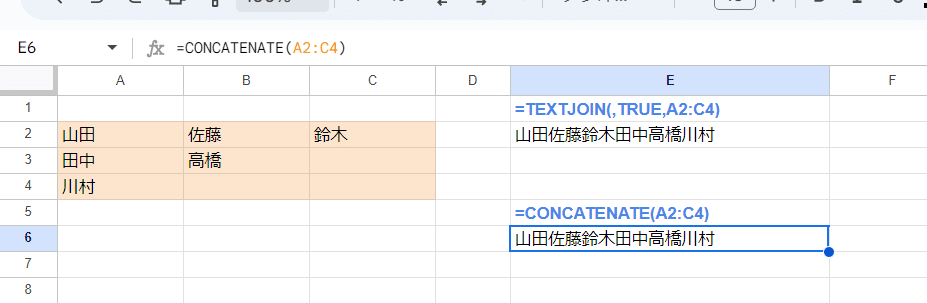
引数には複数行、複数列のセル範囲を指定できて、横スキャン優先とTEXTJOINに近い挙動です。
CONCATENATE関数は、空白無視と区切り文字指定ができないTEXTJOINと思えばOK。(空白無視の方は、区切り文字がないので気にするケースはありません)
区切り文字不要の連結の時にたまーに使うことがありますが、TEXTJOINで代替できるんでコチラを忘れていても問題ありません。
4. 演算子 &(アンパサンド)
テキスト1 & テキスト2 & テキスト3 ・・・
なんだかんだでよく使うのが文字列結合の定番 & です。
2つ以上の文字列を連結して、1つの文字列の値を生成します。
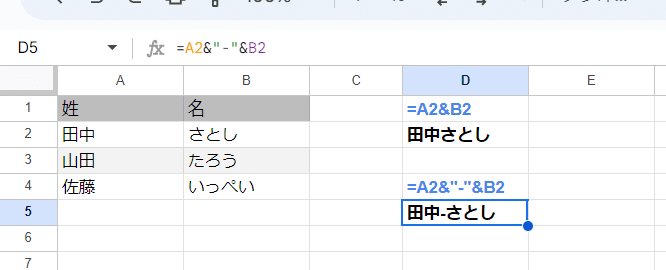
普通にセル参照を&で連結したり、区切り文字を間にいれて
=A2&"-"&B2
こんな連結をするケースが多いです。
&演算子を使うメリットはARRAYFORMULAと組み合わせてスピル処理ができる点です。
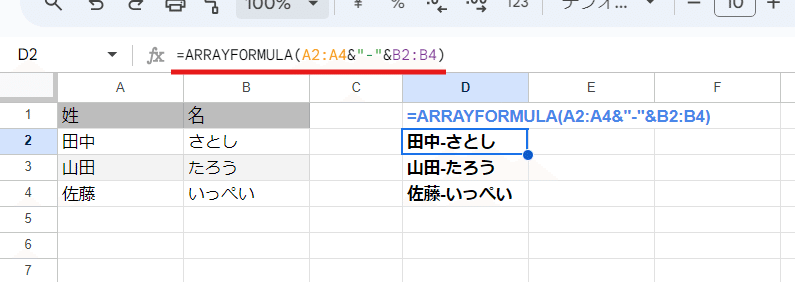
=ARRAYFORMULA(A2:A4&"-"&B2:B4)
ちなみに上の式で "-" をA2:A4の行数分の配列で用意する必要はなく、配列と単体の値を演算子で掛け合わせた場合は、配列の個々の値全てに演算(今回は - を連結する)が機能します。
一方&では、セル範囲を指定してまとめて連結といった使い方は出来ないので、その際は CONCATENATEやTEXTJOINを使うことになります。
このように TEXTJOIN関数の類似関数は色々りますが、基本的にはTEXTJOIN関数と &演算子が使えれば OK かなと思います。
SPLIT関数 チョイ応用例
基本を踏まえた上で、今回はSPLIT関数のチョイ応用例 お題を少しだけやって終わりにしましょう。
Q1. 名前データをスペースで区切って姓と名に分けたい
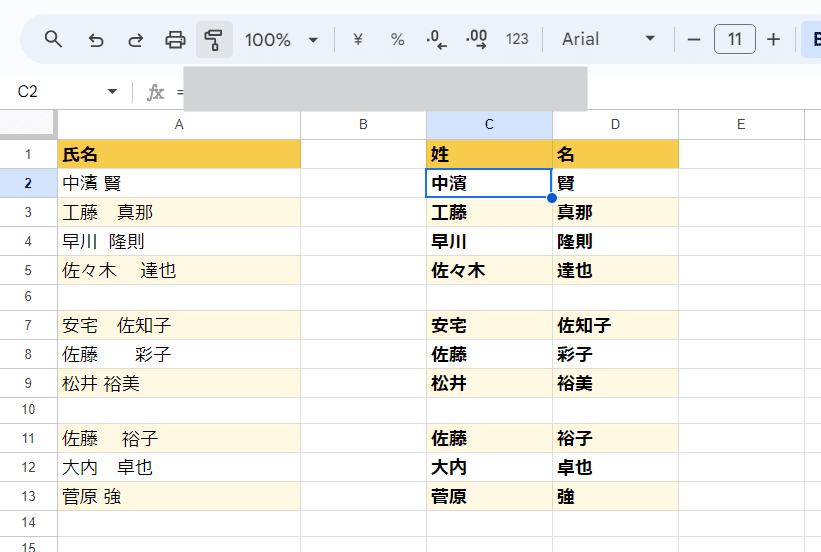
このように A列(A2:A13)に氏名データがあり、姓と名はスペースで区切られている。
ただし手入力の為、スペースは 半角スペースと全角スペースが混在しており、かつスペースが2回以上入ってるケースもある。また、途中に空白行も存在する。
これをC2セルに一つ式を入れて、C列に姓、D列に名と分けて出力したい。(空白行は空白のままとしたい)
どんな式をいれればよいでしょうか?
データはこちら。
氏名 姓 名
中濱 賢
工藤 真那
早川 隆則
佐々木 達也
安宅 佐知子
佐藤 彩子
松井 裕美
佐藤 裕子
大内 卓也
菅原 強 基本問題です。やってみましょう!
↓↓
ここから回答です。
↓↓
A1. 名前データをスペースで区切って姓と名に分けたい
回答です。
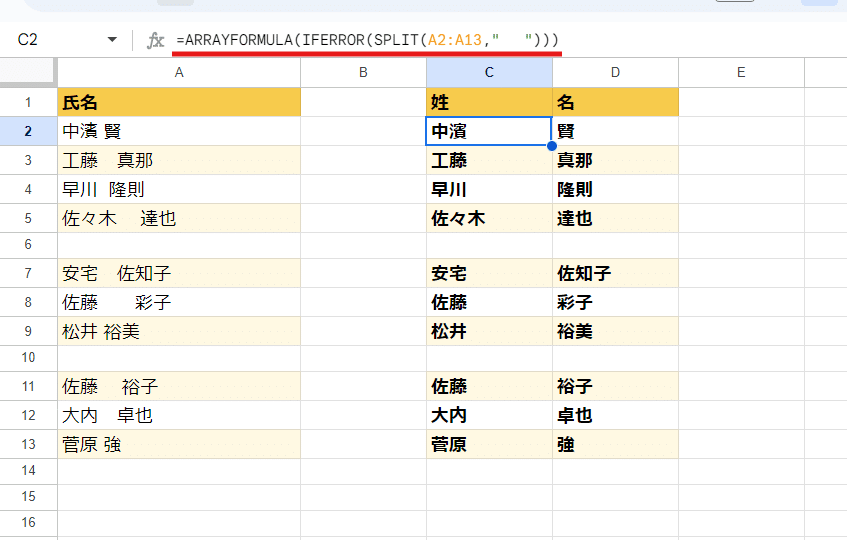
=ARRAYFORMULA(IFERROR(SPLIT(A2:A13," ")))
少しわかりづらいですが、SPLITの第2引数 " " は、半角スペースと全角スペースが入っています。これで半角スペース、全角スペースどちらでも区切っています。
さらにSPLITは基本が 空白を無視なので、スペースが複数回あってもズレは発生しません。
空白行があるとのことなので、IFERRORでエラー表示を回避して、一番外側に配列処理用に ARRAYFORMULA でOKですね。
まずはこれが出来れば基本はOKです。
Q2. セル内改行されたデータを 改行ごとにセルを分けて出力したい
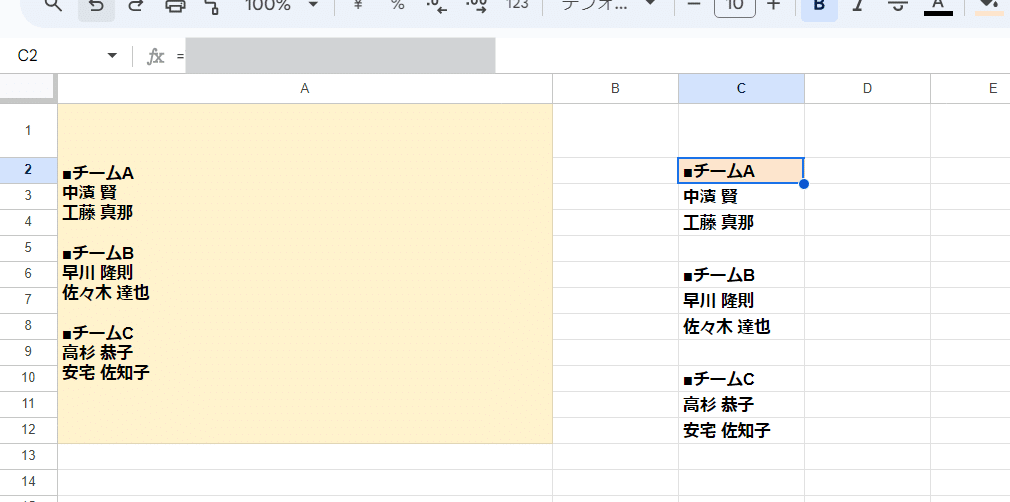
A1セルに セル内で改行されたデータが入っていて、これを C列のような形で縦方向に改行ごとにセルを分けて出力したい。
チームごとに1行あけている箇所はそのまま保持したい。
これを C2 セルに式を入れて実現したい。
さて、このケースはどうすれば良いでしょうか?
■チームA
中濱 賢
工藤 真那
■チームB
早川 隆則
佐々木 達也
■チームC
高杉 恭子
安宅 佐知子A1セルの中身のデータは ↑ こちらです。(セル内に貼ってご利用ください)
ポイントは
・区切り文字が改行?
・1行あけたところを残す?
・分割して縦方向に出力?
ですね。考えてみましょう!
↓↓
ここから回答です。
↓↓
A2. セル内改行されたデータを 改行ごとにセルを分けて出力したい
回答です。
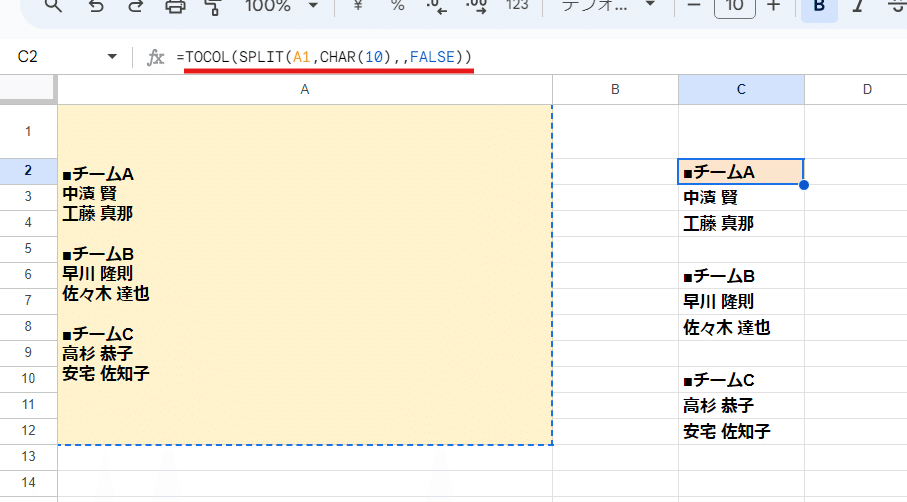
=TOCOL(SPLIT(A1,CHAR(10),,FALSE))
まず、改行での区切りですが CHAR(10)を使うのがよいでしょう。
CHAR関数は文字コード(Googleスプレッドシートの場合はユニコード値)を文字に変換する関数です。
改行はもっとも多く使うので、CHAR(10)は 関数使いは意識せず暗記してますw
CHAR(10)を使わず式の中で改行を入れる方法でも出来るんですが、
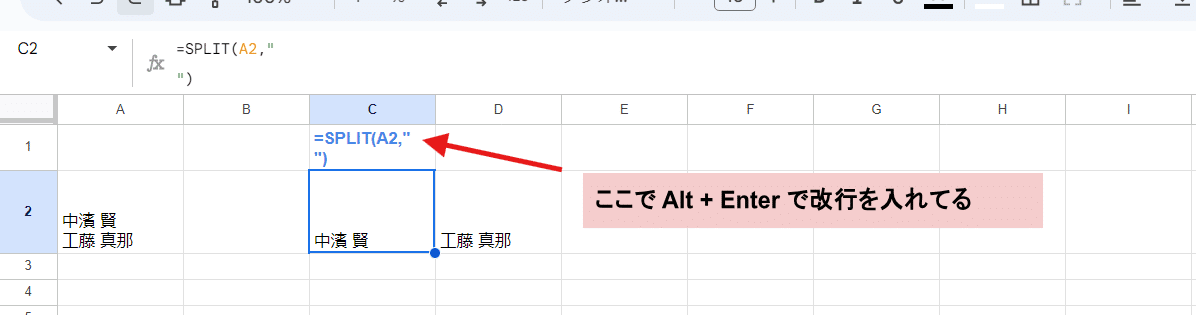
式が変な感じ改行されてしまうし、パッと見でわかりづらいんで CHAR(10)を使うことをお勧めします。

1行あけを保持するという要件ですが、この1行あけは 改行が2回入っている箇所となります。つまり区切り文字が連続している箇所ですね。
ということは、SPLIT関数の第4引数の空白を無視を FALSE指定して、空白セルを残すとすればOKってことです。
そして最後の縦方向への結果出力、これはSPLIT関数では出来ません。
一度SPLITで横に展開した結果を 他の関数で縦に変換すると考えましょう。
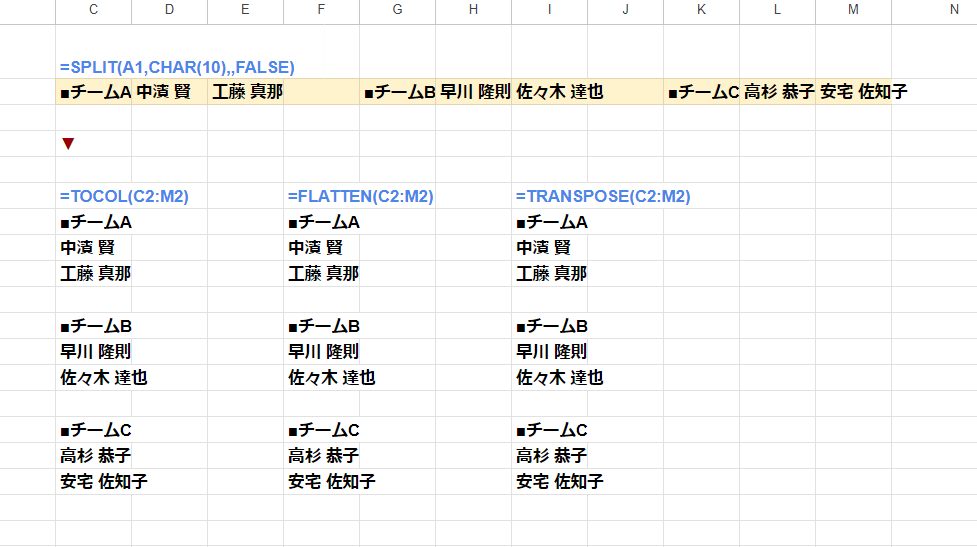
今回は TOCOL関数を組み合わせましたが、ここは FLATTEN関数やTRANSPOSE関数を使ってもOKです。
改行を区切りとした分割、縦方向への展開も出来ましたね。
Q3. 日付データから 年、月、日 の数値を一気に取得したい
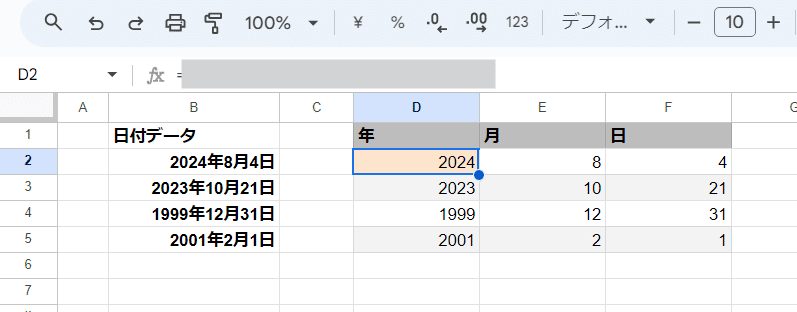
このように B2:B5 の日付データから、D2セルに一つの式を入れるだけで、それぞれの日付と同じ行の D列、E列、F列に 年、月、日 を数値で出力したい。
こんな時D2にどんな式を入れればよいでしょうか?
この流れなんで、使う関数はわかってますねw
割と簡単ですが、Excelユーザーからすると「えっ?」ってるお題です。
考えてみましょう!
↓↓
ここから回答です。
↓↓
A3. 日付データから 年、月、日 の数値を一気に取得したい
回答です。
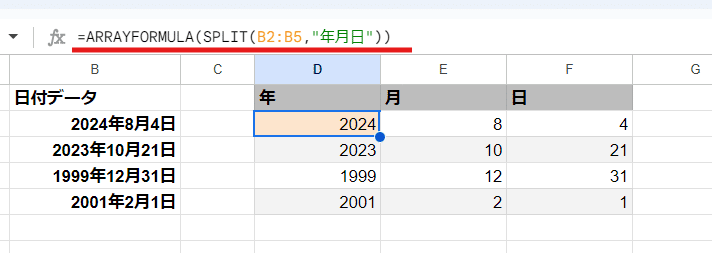
=ARRAYFORMULA(SPLIT(B2:B5,"年月日"))
日付データから、年、月、日を取得するとなると、一般的には YEAR関数、MONTH関数、DAY関数を使う、もしくはTEXT関数で年なら
=--TEXT(B2,"yyyy")
こんな方法が思いつきます。
でも上のような年、月、日 を 一気に一つの式で取得(展開)したいってケースなら SPLIT関数を使う方法がおススメです。
第2引数を "年月日"と指定することで、
2024年8月4日 → 2024 8 4
このように、年、月、日が 区切り文字となり、それぞれの数値だけを取り出すことが出来ます。
ん、日付データは中身シリアル値で 〇年〇月〇日って表示形式なのにおかしくない?
って、思う方も多いんじゃないでしょうか。
そうなんです。これ Excelだと出来ないんです。
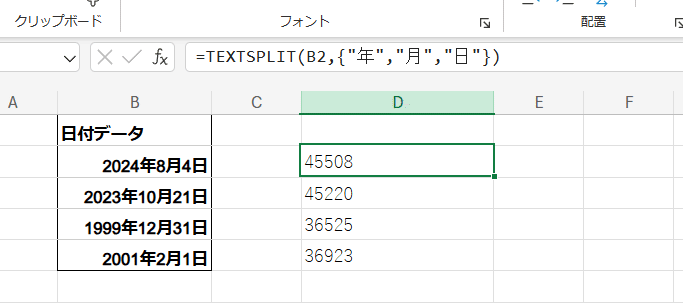
Excelの場合は関数で見にいくのは中身のシリアル値である為、TEXTSPLIT関数を使っても 区切り文字である 年、月、日は存在しないとなり、単にシリアル値を文字列にした結果が返ります。
しかしGoogleスプレッドシートの場合は、テキスト操作系関数は 表示形式を適用した結果を扱う仕様となっている為、SPLIT関数を使ったこのような方法で日付データの分割が可能となります。
このGoogleスプレッドシートの独特な一部関数の仕様については、いきなり答える備忘録さんもサイトで触れています。
じゃあ、表示形式変わったらどうなるのか?

実は 表示形式を変えると数式の結果が変わりますw
元の日付データ を YYYY年MM月DD日 から YYYY/MM/DD に変更すると、今まで "年月日" でSPLITしていた方は 区切り文字なしでそのまま日付が返り、一方 横に追加した "/" で区切るSPLIT関数の式は 表示切替後に 年、月、日に分割された結果が返っているのがわかりますね。
便利な反面、数式としてはちょと不安定だなーとも思います。
Q4. 分割したデータの 2番目の値だけを取り出したい
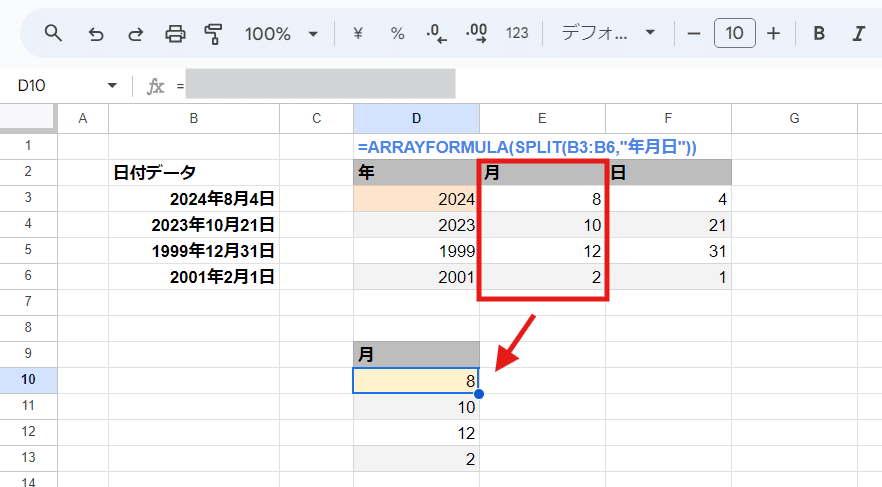
先ほどの日付データの続きですが、もし年、月、日ではなく 月だけを出力したい場合はどうしたらいいでしょうか?
まぁ、これだと MONTH関数スピらせればいいんですが、このケースに限らず 区切り文字で分割したデータの 各行の 2番目のデータを取得したいってお題だと思って下さい。
上の画像だと D10セルに入れる式を考えるお題です。やってみましょう!
↓↓
ここから回答です。
↓↓
A4. 分割したデータの 2番目の値だけを取り出す
回答です。
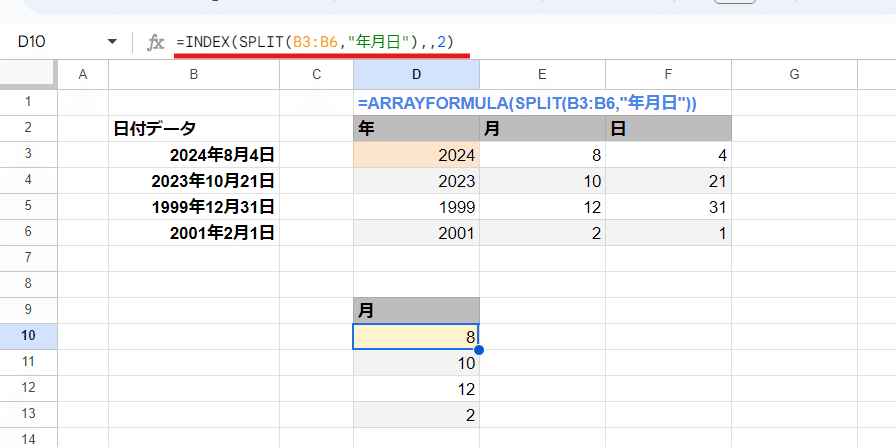
=INDEX(SPLIT(B3:B6,"年月日"),,2)
結果から 2列目を取得するので、INDEX関数を使いましょう。
ここで =INDEX(ARRAYFORMULA(SPLIT(B3:B6,"年月日")),,2) と、そのまま先ほどの式を INDEX関数で括ってもいいんですが、INDEX関数自体にARRAYFORMULAと同じ効果があるので、ARRAYFORMULAは不要になります。
INDEX関数を組み合わせるケースでは、ARRAYFORMULAを外してスッキリした式に出来ることを覚えておきましょう。
Q5. 分割したデータの最後(一番右の値)を取得したい
それでは今回の最後のお題です。
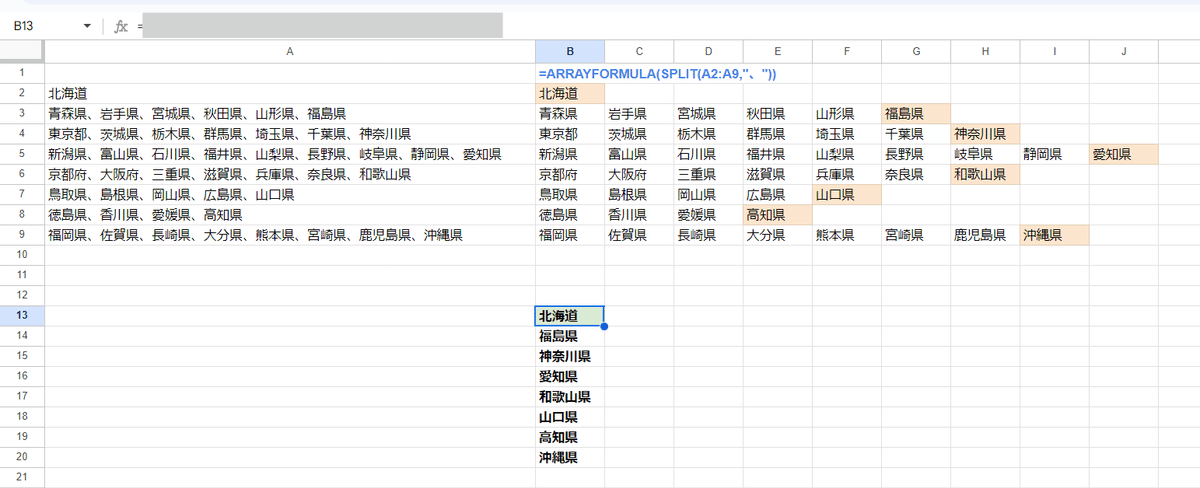
このような A2:A9のエリア別で都道府県が "、"で区切られて入ったデータを"、"で分割した各行の一番後ろ(一番右)のデータを取得して、
北海道
福島県
神奈川県
愛知県
和歌山県
山口県
高知県
沖縄県
こんな結果を出力したい。
この時、どんな式を組めばよいでしょうか?
北海道
青森県、岩手県、宮城県、秋田県、山形県、福島県
東京都、茨城県、栃木県、群馬県、埼玉県、千葉県、神奈川県
新潟県、富山県、石川県、福井県、山梨県、長野県、岐阜県、静岡県、愛知県
京都府、大阪府、三重県、滋賀県、兵庫県、奈良県、和歌山県
鳥取県、島根県、岡山県、広島県、山口県
徳島県、香川県、愛媛県、高知県
福岡県、佐賀県、長崎県、大分県、熊本県、宮崎県、鹿児島県、沖縄県元データはこちらです。 A2に貼ってご利用ください。
前から2番目のように固定ではないのがポイントですね。
少し難しくなります。考えてみましょう!
↓↓
ここから回答です。
↓↓
A5. 分割したデータの最後(一番右の値)を取得する
いきなり回答ではなく、順を追って考えてみましょう。
分割したデータの最後を取得したいわけですが、さきほどのINDEX関数でデータの一番最後を取得しようとすると、データの横幅(列数)が必要となります。
これを LET関数を絡めてやる方法もありますが、
=ARRAYFORMULA(LET(x,SPLIT(A2:A9,"、"),INDEX(x,,COLUMNS(x))))
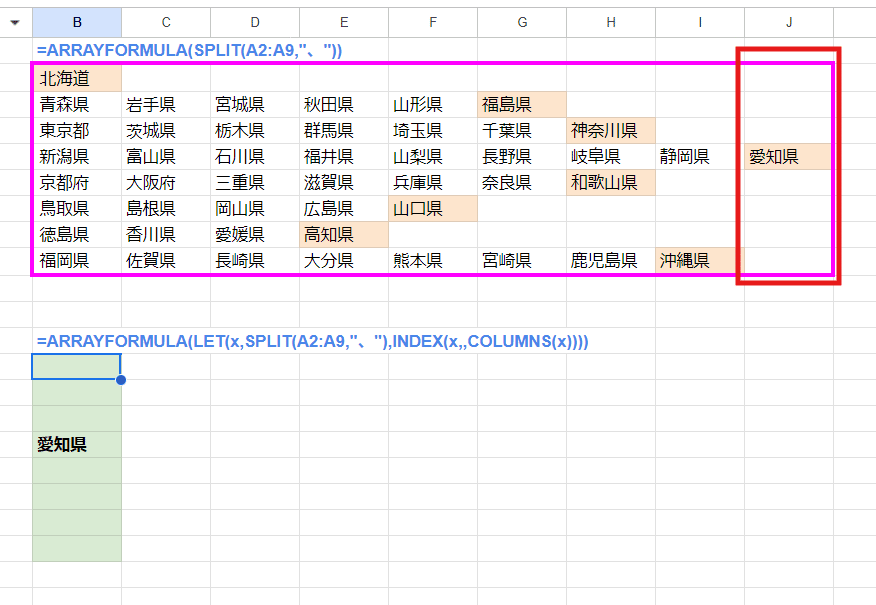
このように SPLITで分割した結果を xと置いて COLUMNS(x) とすると 展開された配列データの列数 8となる為、取得する結果は 一番右側の 愛知県のある一列となってしまい 他の行の結果は空白が返ります。
欲しい結果はこれじゃないです。
他にも マイナスの引数で 後ろから何列目と指定できる CHOOSECOLS関数を組み合わせてARRAYFORMULAという方法もありますが、結果は一緒です。
=ARRAYFORMULA(CHOOSECOLS(SPLIT(A2:A9,"、"),-1))

CHOOSECOLS関数は 2023年3月にExcelからGoogleスプレッドシートに輸入された便利関数ですが、この方法ではダメでした。
ではどうするか?
ARRAYFORMULAによる一括処理ではなく、1行(1セル)毎にSPLIT分割 & CHOOSECOLS マイナス指定 で 最後のデータを取得、これを繰り返す式を作る必要があるってことです。
普通に先頭行に式を書いて下にフィルコピーすれば簡単なんですが、これを一つの式で実現出来るのが LAMBDAヘルパー関数の一つMAP関数です。(BYROWでも可)
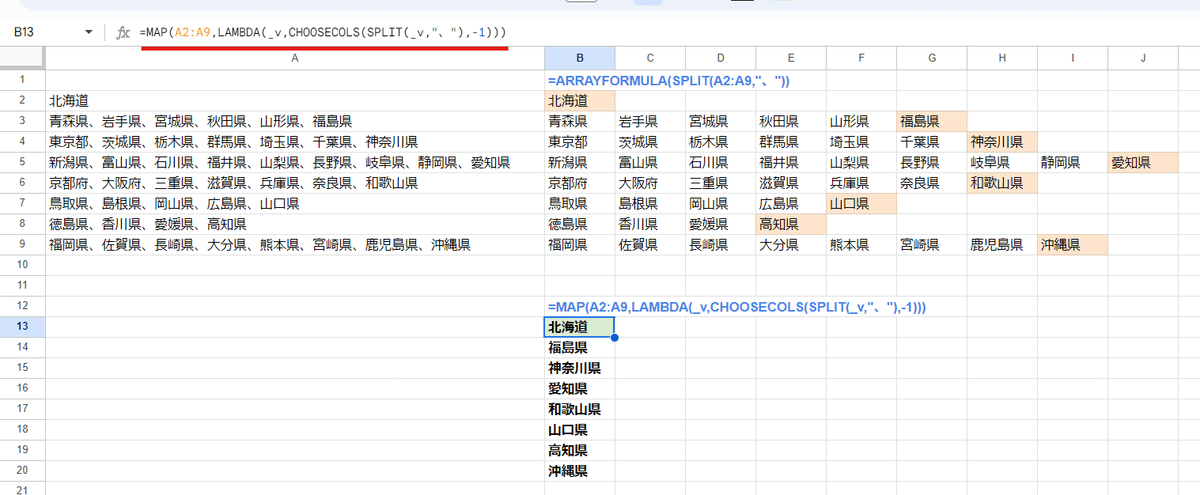
=MAP(A2:A9,LAMBDA(_v,CHOOSECOLS(SPLIT(_v,"、"),-1)))
LAMBDAヘルパー関数を ARRAYFORMULAが効かない関数にも配列処理効果があるというとらえ方をしている人もいますが、中の計算処理が根本的に違います。
配列として一括処理をするARRAYORMULAの動きに対して、LAMBDAヘルパー関数のMAPやBYROW、REDUCEは、中身は繰り返しの処理です。
上の式はA2:A9を 上から順に一つずつ取り出して _v に入れて
CHOOSECOLS(SPLIT(_v,"、"),-1)
SPLITで "、"を区切り文字として分割して、CHOOSECOLSの-1指定で 一番後ろ(右)のデータを取得する。この動作を繰り返しています。
なので、ARRAYFORMULAだと出来なかった 個々の行の一番右のデータを取得することが出来るわけです。
まぁ今回のケースは、REGEXEXTRACT関数を使って正規表現で
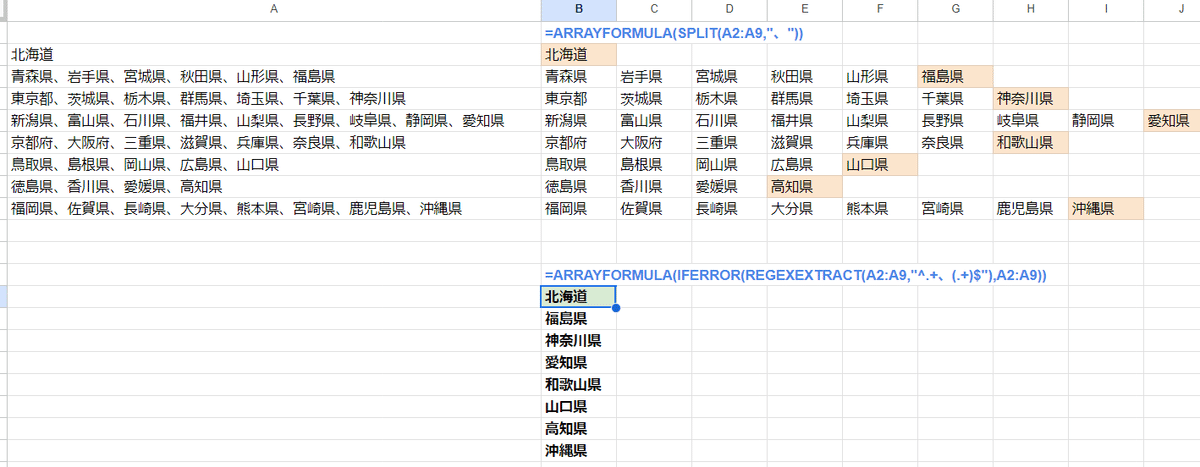
=ARRAYFORMULA(IFERROR(REGEXEXTRACT(A2:A9,"^.+、(.+)$"),A2:A9))
このように書くことも出来るんですが。
でも、正規表現は苦手意識のある人も多いですし、式も長めでわかりにくいんで、
=MAP(A2:A9,LAMBDA(_v,CHOOSECOLS(SPLIT(_v,"、"),-1)))
今回はコチラの方が、スッキリしたわかりやすい式と言えるじゃないでしょうか?
新関数のMAPや CHOOSECOLS をSPLITと組み合わせた応用例でした~。
次回 SPLIT関数 + TEXTJOIN関数を使った 超応用例を!
今回は、SPLIT関数、TEXTJOIN関数の基本、そしてSPLIT関数のちょい応用例で終わってしまいました。
TEXTJOIN関数の出番は少なかったですねw (あまり単体でいいお題がない)
次回は、TEXTJOIN関数のちょい応用例や、この2つの関数を組み合わせた応用例、より難解な超?応用例に取り組んで理解を深めていきましょう!
いいなと思ったら応援しよう!
