
ChatGPT+PineconeでSlackbotを作ってみた

夏休みに「Open AI GPT-4 ChatGPT Langchain 人工知能プログラミング(実践入門) 布留川 英一さん著」を購入。この本では、Google ColabというブラウザでPython コードが実行できるツールを使って、ChatGPTやLangchain、そしてLlamaIndexなどの王道APIを簡単に試してみることができる手順がステップ・バイ・ステップで紹介されています。夏休みの宿題さながら、一通りサンプルを試してみた後に、自分でもなんか作りたくなって、Airtableに入っている社内でまとめているAI関連の資金調達や重要ニュースのナレッジベースをChatGPTを使ってQ&AでできるSlack Botを作ってみましたので簡単に紹介します。
使ったツール
ChatGPT API
Airtable/Airtable API: 社内のナレッジベース格納先。
Pinecone/Pinecone API:ベクトルデータ用のデータベース
PythonAnywhere:Slackから呼び出されるSlackbot本体の実行環境。Pineconeへの問い合わせと、ChatGPTへの問い合わせ、そしてSlackへ結果を返す処理を行う。
Slack/Slack API
Llama_index: 各種ベクトルデータやLLMへの繋ぎ込みやテキスト→ベクトルデータへの変換などを簡単にしてくれるPythonライブラリ群。Pinecone, OpenAIとの接続の例は、「Open AI GPT-4 ChatGPT Langchain 人工知能プログラミング(実践入門)」を(超)参考にしました。
Google Colab:Pythonコードのテストに使用
VS Code:PythonAnywhereで実行するPythonコードを書くのに使用
Flask:Webサーバーフレームワーク
ngrok:PCで動くWebサーバー(開発環境用)
システム図
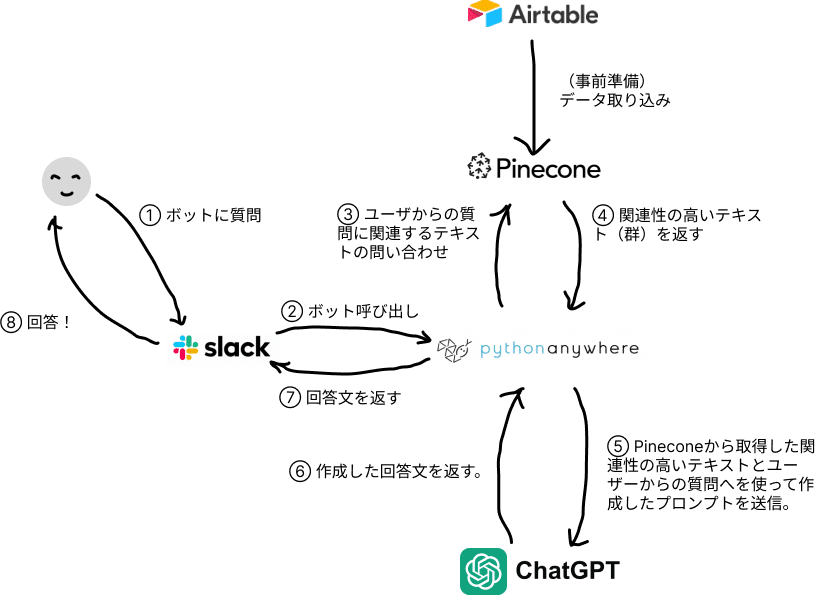
手順概要
Pythonコードを書いてAirtable APIを使って該当するテーブルのデータをダウンロード
Airtableからダウンロードしたデータ(Json[ジェイソン]というファイル形式)からタグをはずしてテキストファイルとして格納。(Pythonコード)
Pineconeのインデックスを作成
Pineconeへデータを投入
Slackからの質問を受けてPineconeとChatGPT APIへ問い合わせを行うPythonコードを書く。
5の手順で作成たPythonコードをPythonAnywhere環境へ以降。
Slackを設定する
ボットのIDの作成や呼び出すタイミングの設定。
手順5で作成したPythonコードとSlackの接続。
Slackからボットへ質問してみる。
苦労したポイント
約20年ぶりに動くソフトウェアを開発してみたため、いろいろと苦労しました😅
Flaskって何?どうやって使うの?
Pythonコードを書いた後にそれをSlackからアクセス可能な公開サーバー上に置いておく必要があるのですが、そこで使われているWEBサーバーのフレームワークがFlask。開発環境からFlaskやngrokといった初めて触れるツールの設定とPythonコードの書き方を習得するのが大変でした。
Slackとボットが繋がらない。。。
SlackからPythonAnywhere上にあるPythonコードを呼び出すようにするためにあらかじめテストリクエストを送信して、正常に稼働するコードであることを確認するのですが、そのときの確認方法がユーザーからの質問への回答とは違うコードを追加で書く必要があり、どうやっていいのかがなかなか分かりませんでした。
Slackのリトライ
Slackは、ボットに問い合わせた後に数秒以内に返信が無い場合は、同じ問い合わせを数回行う仕様になっています。ChatGPTを使うとSlackへ返信するのに数秒かかってしまうことが多い為、何度も同じ質問が来てしまい、回答も複数回繰り返す現象が発生しました。リトライの場合は、無視するみたいなロジックが必要でした。
学び
今回の実験を通していろいろ学びがありました:
① 自社のデータと大規模言語モデルを使ったシステムを構築するためには、元データをどういった単位、構成でベクトルデータベースへ格納するかといったノウハウが重要になる。
今回の例では、Airtable上の1行につき1つの情報単位といった形式でしたが、例えば社内Wiki、Zendesk、Jira、 Notion、Word, Google Docsなど、様々な形式で保存されている情報をベクトルデータへ取り込むには、どういった単位で情報を定義していくか(Chunking: チャンキング)が、ChatGPTから最高の回答を得られるキーになると感じました。このチャンキングによって、どれくらい回答のヒントが詰まった簡潔なデータを大規模言語モデルに渡せるかが決まってきます。
また、その手前で重複データのクリーニングや、個人情報・機密情報のマスキング、アクセス権限の大規模言語モデルシステム上での適用させる等の処理も必要になってきますね。この辺りの課題は複数のスタートアップがプロダクト化を始めています。
② 曖昧さを含んだシステム
ユーザーからの質問とPineconeからの回答でプロンプトを作成し、ChatGPTへ質問するきちんと回答が帰ってきます。システム上の最も困難な部分を大規模言語モデルがやってくれます。私の場合は、ノーチェックでユーザーにそのままChatGPTの回答を返していますが、実際には回答内容のチェックも行う必要が出てくるかもしれません。
うまく言えませんが、この”曖昧さ”が残る感覚は新しいと感じました。
③ 大規模言語モデルのプログラミングの活用
今回自分で、大規模言語モデルを使った開発をしてみて思ったのは、ChatGPTやBingは、コーディングに使えるということです。特にSaaS各社のAPIのように、それぞれの手順や関数がある場合などはなおさらでした。
ここで重要になってくるのが、Stack Overflow、Github等のサイト上のコミュニティメンバーのやり取りやサンプルコードの重要です。大規模言語は、それらを学習データとしていますので、コミュニティが活発なほうがより大規模言語モデル時代により有利になります。私の少ないサンプルですが、SlackやGoogleは、内部のエンジニアも積極的に開発者からの質問に回答したり、Githubに新しいライブラリのサンプルコードを積極的に公開したりしています。
What's next?
今取り組んでいる(ホビー)プロジェクトは、Google Drive上に保存されているGoogle DocsをGoogle Cloud上のツール群:
- Vertex AI Vector Search (元Vertex AI Matching Engine)
- Palm2 :大規模言語モデル
- FireStore:
を使ってQ&Aシステムを作ってみるというものです。こちらは、Airtable + Pinecone + ChatGPTよりもより汎用性の高いものにしたいと思っています。ある程度できたらまた共有できればと思っています。
あとは、作りっぱなしになっているので、回答の精度評価なんかもやっていきたいと思っています。