
NewSQLはデータベースに革命を起こすか - NetflixにおけるCockroachDBのユースケース

近年のデータベースの新潮流にNewSQLと呼ばれる一群のデータベース製品群の登場がある。そのコンセプトを一言でいうと、RDBとNoSQLのいいとこどりである。SQLインタフェースと強いデータ一貫性(ACID)というRDBの利点と水平方向のスケーラビリティというNoSQLの長所を兼ね備えた夢のようなデータベースである。下図に見られるように、RDBとNoSQLが鋭いトレードオフを発生させていたのに対して、NewSQLではそれが解消されているのが分かる。
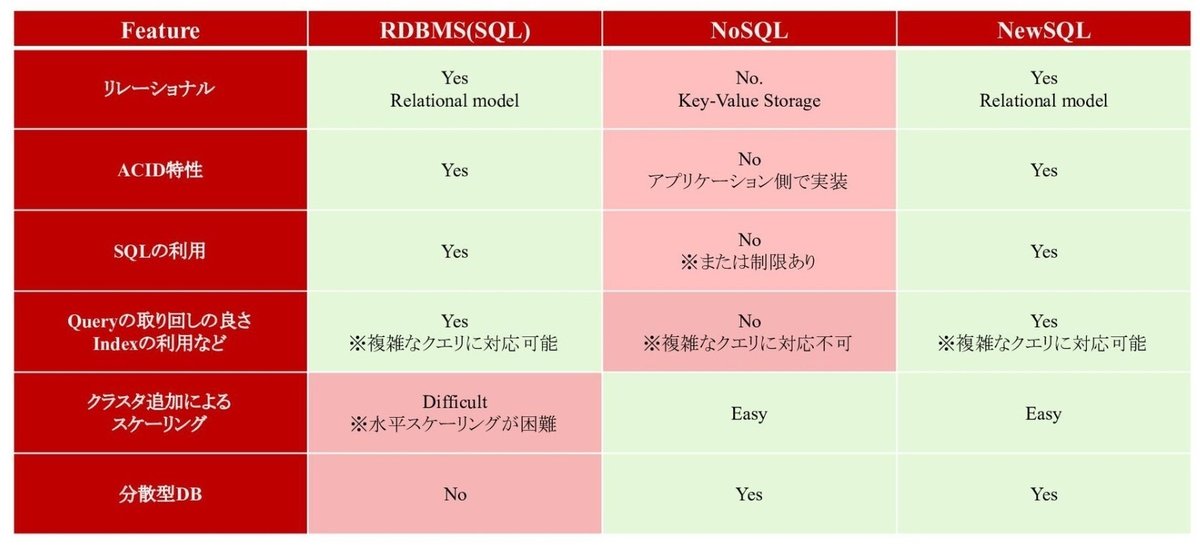
本当にそのような夢の実現に成功しているか、というのはまだ議論が続いているが(クエリのスループットを出すためにレイテンシを犠牲にしているので本当にトレードオフを解消はしていない、などの問題が指摘されている)、商用でも利用可能な製品としてGoogle Spanner、TiDB、YugabyteDB、CockroachDBなど有力な候補も登場してきている。日本でも楽天、PayPay、LINEなどのアーリーアダプタで採用が始まっている。
しかしNewSQLに対しては「便利そうだけどどこで使うの?」というユースケースに悩む声がまだ多いのも実情である。そこで、本稿ではNewSQLを実際に利用したケースとしてNetflixによるCockroachDBの例を、Netflixの技術ブログ"Orchestrating Data/ML Workflows at Scale With Netflix Maestro"を翻訳することで見ていきたい。かなり技術的に高度なことをやっており難解なところもあるのだが、NewSQLの大規模スケーラビリティの実例として有用ではないかと考えている。
全部読むと長い上に難解なので、CockroachDBに関係するところだけをサマリとしてまとめておく。時間のない方はこのサマリだけ読んでもらえれば十分である。
サマリ
Netflixも、いきなりCockroachDBに飛びついたわけではない。最初はNetflixもオンプレのデータセンターから始まったのである。
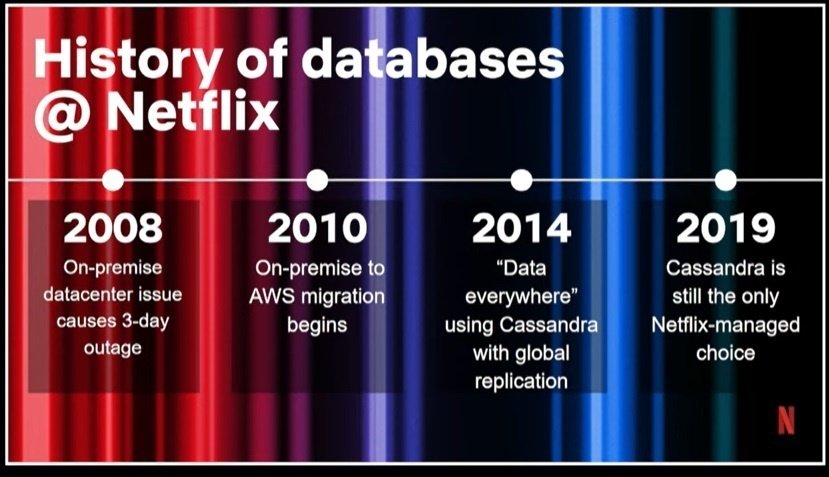
上図を見てもらえれば分かると思うが、2008年にオンプレでスタートして、2010年にAWSへ移行、2014年にCassandraを採用している。
2019年になると、NetflixはCassandraに限界を感じ始める。当時、Netflixは需要の増加と日増しに高まるデータベース要件に悩まされていた。Cassandraではリッチなトランザクションを組むことができず、グローバルレベルで一貫性のあるトランザクションをサポートすることが困難だった。またセカンダリ・インデックスは信頼性が低く、機能しないことが多かった。そこでAWSの AuroraやDynamoDBを候補に考えたが、いずれも要件を満たさなかった(参照:"The history of databases at Netflix: From Cassandra to CockroachDB")。Auroraは書き込みはシングルリージョンのみでスケールしない点、DyanamoDBは結果整合性しかなくSQLインタフェースがない点で敬遠されたのが分かる。

2020年、Netflixは最初のCockroachDBクラスタを本番環境にデプロイした。環境としてはAWS EC2とEBSが使われている。現在では100の本番クラスタと150以上のテストクラスタがある。2023年時点では、ほとんどのクラスタは3つのアベイラビリティゾーンを持つ単一リージョンにデプロイされている。Netflixで最大のCockroachDBクラスターは60ノード、単一リージョンのクラスターで、26.5テラバイトのデータがある。これだけの規模のデータで高トランザクションをさばきつつ監視やバックアップまで実現できているというのは、かなりすごいことだと思う。CockroachDBはまだ日本語のサポート窓口がないのだが、筆者が一番期待しているNewSQLの実装なので、早く日本進出してくれないかなと思っている。NetflixのほかにDoordashやSpotifyなどメガウェブサービスで利用されているので、エンタープライズにも適合する可能性が高いのではないかと期待しているのだ。
それでは、以下に全文の翻訳を示す。正直かなり抽象度が高く技術的にも高度なことを語っているので、理解するのに骨が折れる。興味のある所を拾い読みするのでもよいと思う。個人的には、Maestroのユーザである一般社員たちもかなりプログラミング言語(Java, Python, SQL)に習熟しているのが見受けられたのが印象的だった。さすが世界を代表するデータドリブン企業、といったところである。
Netflix Maestroでデータ/MLワークフローの大規模オーケストレーション
Netflixでは、データおよび機械学習(ML)パイプラインが広く使用され、レコメンデーション、予測、データ変換にとどまらない多様なユースケースを代表するビジネスの中心となっている。多用なビジネス要求に対応するため、毎日多くのバッチワークフローが実行されている。これには、ETLパイプライン、MLモデルのトレーニングワークフロー、バッチジョブなどが含まれる。ビッグデータとMLの普及が進み、影響力を持つようになるにつれ、オーケストレーション・エコシステムのスケーラビリティ、信頼性、ユーザビリティが、データサイエンティストと会社にとってますます重要になってきた。
このブログでは、大規模なワークフローをスケジューリング・管理できるワークフロー・オーケストレーター、Maestroを紹介し、そこから得られる学びを共有したい。
動機
大規模なワークフローを実現し、幅広いユースケースをサポートするためには、スケーラビリティとユーザビリティが不可欠である。私たちの既存のオーケストレーター(Meson)は、数年のあいだうまく機能してきた(訳注:MesonはApache Sparkベースのシステム)。1日あたり約7万個のワークフローと50万個のジョブをスケジューリングしている。その使い勝手の良さのため、システムによって管理されるワークフローの数は指数関数的に増加した。その結果、私たちは、次のようなスケールの問題の兆候に直面することになった:
午前12時(UTC)前後のトラフィックピーク時に処理速度が低下し、運用負荷が増大した。オンコールのスケジューラーが営業時間外にシステムを注意深く監視する必要が生じた。
Mesonは、高可用性を備えた単一リーダー・アーキテクチャに基づいていた。利用が増加するにつれ、システムを垂直方向に拡張しなければ追いつかなくなり、AWSインスタンスタイプの限界に近づいていた。
ここ数年、ワークフローが年間100%以上の割合で急成長しているため、スケーラブルなデータワークフローオーケストレータは、Netflixのビジネス要求にとって最も重要なものとなっていた。ワークフロー・オーケストレーターの現状を精査した結果、私たちは100以上のノードで構成されるクラスタにジョブを分散させる水平スケーリングが可能な次世代システムを開発することを決意した。このシステムは、私たちがMesonで直面している主要な課題に対処し、卓越した運用を実現してくれるはずだ。
ワークフロー・オーケストレーションの難題
スケーラビリティ:オーケストレーターは、毎日何十万ものワークフロー、何百万ものジョブをスケジューリングし、トラフィックが急増した場合でも、スケジューラーから投入後1分以内という厳しいSLOで運用しなければならない。Netflixでは、ピーク時のトラフィック負荷は平均負荷よりも数桁高くなることがある。私たちのワークフローの多くは、UTCの深夜に実行される。したがって、システムはSLO要件を維持しながら、トラフィックのバーストに耐えなければならない。さらに、運用とユーザビリティの観点から、ほとんどのユーザー・ワークフローを単一のスケジューラ・クラスターで管理したいと考えた。
考慮すべきスケーラビリティのもう一つの側面は、ワークフローのサイズである。データ領域では、1つのワークフロー内に膨大な数のジョブが存在することが一般的である。例えば、過去5年間の時間単位のデータをバックフィルするワークフローは、43800ジョブ(24 * 365 * 5)になり、それぞれが1時間分のデータを処理する。同様に、MLモデルのトレーニングワークフローは通常、1つのワークフロー内で数万(あるいは数百万)のトレーニングジョブから構成される。このような大規模なワークフローは、ホットスポットを発生させ、オーケストレーターや後続のシステムをパンクさせる可能性がある。そのため、オーケストレータは数十万のジョブで構成されるワークフローをパフォーマンスよく管理しなければならないが、これも非常に困難だ。ユーザの利便性:Netflixはデータ駆動型の企業であり、ランディングページで使用されるピクセルの色からテレビシリーズのリニューアルに至るまで、重要な意思決定はデータインサイトによって行われる(訳注:これもすごい話である)。データサイエンティスト、エンジニア、非エンジニア、そしてコンテンツ制作者までもが、必要な洞察を得るためにデータパイプラインを走らせている。多様なバックグラウンドを持つNetflixにとって、ユーザビリティは成功するオーケストレーターの要である。
ユーザーにはビジネスロジックに集中してもらい、オーケストレーターにはスケジューリング、処理、エラー処理、セキュリティなどの横断的な問題の解決を期待したい。似たような問題を解決するために、非エンジニア向けのハイレベルなものと、エンジニアが特定の問題を解決するためのローレベルなものと、異なる抽象度のシステムを提供する必要がある。また、ニーズに合わせてワークフローを設定するための簡便なUIを提供する必要がある。さらに、システムがデバッグ可能で、ユーザーがトラブルシューティングできるようにすべてのエラーを可視化することが重要である。
ワークフローやジョブの作成にかかる貴重な時間を節約するためには、ユーザーに抽象化を提供することも必要だ。私たちは、ユーザーが共有テンプレートを活用し、チーム全体でワークフロー定義を再利用することで、同じ機能を作成する時間と労力を節約することを期待している。社内全体でジョブテンプレートを使用することは、アップグレードや修正も簡単にする。テンプレートに変更が加えられると、それを使用するすべてのワークフローが自動的に更新されるからだ。
しかし、ユーザビリティというのはしばしば意見が分かれるテーマで、正直難しい。ユーザーによって好みが異なり、求める機能も異なる可能性があるからだ。時には、別々のユーザーが正反対の機能を求めたり、ニッチなケースを求めたりすることもあり、必ずしも幅広いユーザーにとって有用であるとは限らないのだ。
Maestroの導入
Maestroは、Netflixの現在および将来のニーズを満たす次世代データワークフロー・オーケストレーションプラットフォームである。NetflixのデータプラットフォームにフルマネージドなWorkflow-as-a-Service(WaaS)を提供する汎用ワークフロー・オーケストレータである。データサイエンティスト、データエンジニア、機械学習エンジニア、ソフトウェアエンジニア、コンテンツ制作者、ビジネスアナリストなど、さまざまなユースケースに対応する数千人のユーザーにサービスを提供している。
Maestroは、既存のユースケースや新しいユースケースをサポートするための高い拡張性を備えており、エンドユーザーへのユーザビリティを高めている。図1にハイレベル・アーキテクチャを示す。

Maestroでは、ワークフローはステップと呼ばれるジョブ定義の個々の単位からなる DAG(有向非巡回グラフ)である。ステップには、依存関係、トリガー、ワークフローパラメータ、メタデータ、ステップパラメータ、コンフィギュレーション、ブランチ(条件付きまたは無条件)がある。このブログでは、ステップとジョブを同義で使用する。ワークフローインスタンスはワークフローの実行であり、同様にステップの実行はステップインスタンスと呼ばれる。インスタンスデータには、実行時に収集される評価パラメータやその他の情報が含まれ、様々な種類の実行に関する洞察を提供する。本システムは3つの主要なマイクロサービスから構成さる。それぞれ、以下のセクションで説明する。
Maestroは、ビジネスロジックが分離して実行されることを保証する。Maestroはコンテナ内で作業単位(つまりステップ)を起動し、コンテナがユーザー/アプリケーションのIDで起動されることを保証する。IDで起動することで、作業がユーザー/アプリケーションの代わりに起動されることが保証される。IDは後に、操作が許可されているかどうかを検証するために下流のシステムで使用される。例えば、ユーザー/アプリケーションのIDは、テーブルの読み取り/書き込みが許可されているかどうかを検証するためにデータウェアハウスでチェックされる。
Workflow Engine
ワークフロー・エンジンは、ワークフロー定義、ワークフロー・インスタンスのライフサイクル、およびステップ・インスタンスを管理するコア・コンポーネントである。これは以下のような豊富なサポート機能を提供する:
あらゆる妥当なDAGパターン
サブワークフロー、foreach、条件分岐などの一般的なデータフロー構造
異なるエラーリトライポリシーでステップの失敗を処理する複数の失敗モード
ワークフロー/ステップレベルで実行数を調整する柔軟な同時実行制御
Sparkクエリの実行やGoogleシートへのデータ移動など、一般的なジョブパターンに対応したステップテンプレート
カスタマイズされた式言語を使用したパラメータコードインジェクションのサポート
ワークフロー定義とオーナーシップ管理
すべての状態変化と関連するデバッグ情報を含むタイムライン
私たちは、Maestroのワークフローのステートマシンを管理するライブラリとして、NetflixのオープンソースプロジェクトConductorを使用している。このライブラリは、ワークフローで定義された各ステップを、少なくとも1回は確実にエンキューおよびデキューする。
時間ベースのスケジューリングサービス
時間ベースのスケジューリングサービスは、ワークフロー定義で指定されたスケジュール時間に新しいワークフローインスタンスを開始する。ユーザーは、cron式を使用したり、毎時、毎週などの定期的なスケジュールテンプレートを使用してスケジュールを定義することができる。このサービスは軽量で、最低1回のスケジューリングを保証する。Maestroエンジンサービスは、ワークフローをスケジューリングする際に、正確な一度だけの保証を行うために、トリガーリクエストを重複排除する。
時間ベースのトリガーは、そのシンプルさと管理のしやすさから人気がある。しかし、時には効率的でないこともある。例えば、毎日のワークフローは、データパーティションの準備ができたときにデータを処理する必要がある。そのため、手動と時間ベースのトリガーに加え、イベントドリブンのトリガーも提供している。
シグナルサービス
Maestroは、パラメータ値などの情報を伝達するメッセージの一部であるシグナルを介したイベントドリブントリガーをサポートしている。シグナルトリガーは、ワークフローが実行可能かどうかをチェックするためにリソースを浪費することがなく、代わりに条件が満たされた時にのみワークフローを実行するため、効率的で正確である。
シグナルは二通りの使われ方をする:
新しいワークフロー・インスタンスを開始するためのトリガー
ステップを条件付き(データ分割準備など)で開始するためのゲート関数
シグナルサービスは以下のことを目的としている:
シグナルの収集とインデックス作成
ワークフロー・トリガーサブスクリプションの登録と処理
ステップゲーティング機能の登録と処理
シグナルによってブロックされた一連のワークフロートリガーとステップのキャプチャ

Maestroのシグナルサービスは、異なるソースからの全てのシグナル、例えば、全てのウェアハウステーブルの更新、S3イベント、シグナルをリリースするワークフローを受け取り、シグナルと記述されたワークフローを関連付けることにより、対応するトリガーを生成する。外部シグナルとワークフロー・トリガー間の変換に加えて、このサービスは、受信したシグナルを履歴の中から検索することにより、ステップの依存関係にも責任を持つ。スケジューリングサービスと同様に、シグナルサービスは、Maestroエンジンと一緒に、厳密に一度だけ実行されるトリガーの保証を実現する。
シグナル・サービスはまた、多くの場合に有用な一連のシグナルを提供する。例えば、ワークフローによって更新されたテーブルは、下流のワークフロー実行の連鎖につながる可能性がある。ほとんどの場合、異なるワークフローは異なるチームによって所有されており、一連のシグナルは、上流と下流のワークフロー所有者が、誰が誰に依存しているかを確認するのに役立つ。
規模に応じたオーケストレーション
Maestroのすべてのサービスはステートレスで、水平にスケールアウトできる。全てのリクエストは、メッセージ授受のための分散キューを介して処理される。シェアード・ナッシング・アーキテクチャを採用することで、Maestroは数百万ものワークフローとステップ・インスタンスの状態を同時に管理するために、水平にスケールすることができる。
CockroachDBは、ワークフロー定義とインスタンス状態の永続化に使用される。CockroachDBを選んだのは、オープンソースの分散SQLデータベースであり、強力な一貫性保証を提供し、運用上のオーバーヘッドなしに水平スケールできるからである。
一般に、超大規模なワークフローをサポートするのは難しい。例えば、ワークフロー定義では、数百万ノードからなるDAGを明示的に定義することができる。このような膨大なノードを持つDAGは、グラフィカルにはうまくレンダリングできない。いくつかの制約を強制し、ワークフロー・インスタンス内の数十万(あるいは数百万)のステップ・インスタンスからなる有効なユースケースをサポートしなければならない。
我々の調査やユーザーからのフィードバックによって、実際には以下のことが判明した:
ユーザーは、1つのワークフロー定義に何千ものステップの定義を手作業で記述したがらない。もしやればUI上で管理することは極めて困難になる。このようなユースケースでは、ワークフローをより小さなサブワークフローに分解することが常に可能である。
ユーザは、与えられたワークフローインスタンスにおいて、パラメータ設定を変えながら、DAGのある部分を何十万回(あるいは何百万回)でも繰り返し実行することを希望している。従って、実行時には、ワークフロー・インスタンスは数百万のステップ・インスタンスを含むかもしれない。
したがって、ワークフローDAGのサイズ制限(例えば1K)を強制し、foreachブロック内でサブDAGを定義し、より大きな制限(例えば100K)でサブDAGを反復することを可能にするforeachパターンを提供する。foreachは別のforeachでネストすることができる。そのため、ユーザーは1つのワークフローインスタンスで数百万から数十億のステップを実行することができる。
Maestroでは、foreach自体が元のワークフロー定義におけるステップである。foreachは内部的には別のワークフローとして扱われ、foreachループ内のステップ実行数に基づいて、他のMaestroワークフローと同様にスケールする。foreach 内のサブ DAG の実行は、別のワークフローインスタンスに委譲される。foreachステップは、これらのforeachワークフローインスタンスを監視し、そのステータスを収集する。

この設計により、foreachパターンは逐次ループと入れ子ループを高いスケーラビリティでサポートする。foreachステップでループ全体のステータスを見たり、各反復を個別に見たりできるので、管理やトラブルシューティングが容易である。
みんなのためのワークフロー・プラットフォーム
私たちは、Maestroを様々なバックグラウンドを持つユーザーにとって使いやすく、習得しやすいものにすることを目指している。ユーザーがプログラミング言語にある程度習熟していることをある程度想定しており、bashスクリプト、Jupyterノートブック、Java jar、Dockerイメージ、SQL文、あるいはパラメータ化されたワークフローテンプレートを使用したGUIで操作など(ただし、これらに限定されない)、複数の方法でビジネスロジックを実行することができる。
ユーザインタフェース
Maestroは、エンドユーザーがビジネスロジックから切り離されたワークフローを定義するために、YAML、Python、Javaを含む複数のドメイン固有言語(DSL)を提供する。ユーザーは、MaestroAPIに直接アクセスし、JSONデータモデルを使用してワークフローを作成することもできる。人間が読めるDSLは人気があり、さまざまなユースケースをサポートするために重要な役割を果たしていることがわかった。YAML DSLは、そのシンプルさと読みやすさから、最も人気のあるDSLである。
以下は、異なる DSL によって定義されたワークフローの例である:

さらに、ユーザーはUI上で特定のタイプのワークフローを生成したり、他のライブラリを使用したりすることもできる。
ノートブックUIでは、ユーザは選択したノートブックを定期的に実行するよう直接スケジュールすることができる。
MaestroUIでは、あるソース(データテーブルやスプレッドシートなど)から別のソースへ定期手kにデータを移動するよう、直接スケジュールすることができる。
Metaflowライブラリを使用して、任意のPythonコードで構成されるDAGを実行するワークフローをMaestroで作成できる。
パラメータ化されたワークフロー
多くの場合、ユーザーは様々なシナリオに適応するために動的なワークフローを定義したいと考える。これまでの経験から、完全に動的なワークフローは、保守やトラブルシューティングが難しく、あまり好ましいものではない。その代わりに、Maestroは、パラメータ化されたワークフローを定義するユーザーを支援する3つの機能を提供する:
条件分岐
サブワークフロー
出力パラメータ―
実行時にワークフロー DAG を動的に変更する代わりに、ユーザーはそれらの変更をサブ ワークフローとして定義し、実行時に適切なサブワークフローを呼び出すことができる。さらに、output パラメータを使用することで、ユーザーは上流ジョブステップから異なる結果を生成し、foreach 内でその結果を繰り返し処理したり、サブワークフローに渡したり、下流ステップで使用したりすることができる。
2つのステップを持つバックフィル・ワークフローの例(YAML DSLを使用)を示します。ステップ 1 では、バックフィル範囲を計算し、日付 (20210101 から 20220101) を返す。次に、foreach ステップは、step1 からの日付を使用して foreach イテレーションを作成する。最後に、各バックフィル・ジョブはforeachから日付を取得し、その日付に基づいてデータをバックフィルする。
Workflow:
id: demo.pipeline
FROM_DATE: 20210101 #inclusive
TO_DATE: 20220101 #exclusive
jobs:
- job:
id: step1
type: NoOp
'!dates': dateIntsBetween(FROM_DATE, TO_DATE, 1); #SEL expr
- foreach:
id: step2
params:
date: ${dates@step1} #reference upstream step parameter
jobs:
- job:
id: backfill
type: Notebook
notebook:
input_path: s3://path/to/notebook.ipynb
arg1: $date #pass the foreach parameter into notebook
Maestroのパラメータシステムは、コードインジェクションをサポートし、完全に動的である。ユーザーは、パラメータ定義としてJava構文でコードを書くことができる。セキュリティーを確保するために、独自のセキュア式言語(SEL)を開発した。これは、限られた機能のみを公開し、言語パーサーに追加のチェック(ループ文の反復回数など)を含んでいる。
実行の抽象化
Maestroは複数の実行抽象化レベルを提供する。ユーザーは、提供されたステップタイプの使用を選択し、そのパラメータを設定することができる。これは、一般的に使用される操作のビジネスロジックをカプセル化するのに役立ち、ユーザーがジョブを作成するのを非常に簡単にする。例えば、sparkステップタイプの場合、ユーザーはspark sqlクエリ、メモリ要件などの必要なパラメータを指定するだけで、Maestroがステップを作成するために舞台裏ですべてを行る。特定のステップのビジネスロジックを変更する必要がある場合、そのステップタイプのユーザーに対してシームレスに変更することができる。
提供されたステップタイプだけでは不十分な場合、ユーザーはJupyterノートブックで独自のビジネスロジックを開発し、それをMaestroに渡すこともできる。上級ユーザは、よく調整された独自のDockerイメージを開発し、Maestroにスケジューリングと実行を任せることができる。
さらに、パラメータ化されたノートブックであるジョブテンプレートを導入することで、様々なユースケースから共通の機能や再利用可能なパターンを抽象化し、疎結合の方法でMaestroに追加する。これはステップタイプとは異なり、テンプレートは様々なステップの組み合わせを提供する。上級ユーザーは、この機能を活用して、自分たちのチームに共通のパターンを出荷(ship)することもできる。新しいテンプレートを作成する際、ユーザーは必須/オプションのパラメータリストをタイプと共に定義し、テンプレートをMaestroに登録することができる。Maestroは、プッシュ時と実行時にパラメータと型を検証します。将来的には、この機能を拡張して、ユーザーがチームや全従業員用のテンプレートを非常に簡単に定義できるようにする予定だ。場合によっては、マルチステップ機能を実現するために、共通のサブDAGを定義するためにサブワークフローを使用することもある。
将来に向けて
私たちはビッグデータ・オーケストレーションを次のレベルに引き上げ、常に新しい問題や課題を解決していく。大規模なオーケストレーションの問題を解決したいという意欲のある方、ぜひ弊社にご応募ください。
おまけ
ちなみにCockroachDBはフードデリバリー企業のDoordash(Uber Eatsの競合。筆者も米国駐在時はよく使っていた)でも、Auroraからマイグレーション先に選ばれている。現在扱うデータ量は2テラバイトに達するという。以下の記事を参照。
この記事が気に入ったらサポートをしてみませんか?