
Python Pandas データ取り込み

Pythonでデータ分析するなら必須のツールであるPandas。よくあるデータ形式の取り込み方を列挙する。
モジュールインポート
print("実行環境")
import pandas as pd
import numpy as np
import xml.etree.ElementTree as ET
# from lxml import objectify
from lxml import etree
!python -V
print('pandas ' + pd.__version__)実行環境
Python 3.8.12
pandas 1.3.4# 出力時の表示を指定の数値以下にする
pd.set_option('display.max_rows', 10)
pd.set_option('display.max_columns', 100)Seriesの生成
series_data = pd.Series([0, 1, 2, 3, 4, 5],
index=['a', 'b', 'c', 'd', 'e', 'f'])
series_dataa 0
b 1
c 2
d 3
e 4
f 5
dtype: int64DataFrameの生成
dataframe_data = pd.DataFrame({'A':[0, 1, 2, 3, 4, 5],
'B':[6, 7, 8, 9, 10, 11],
'C':['one', 'two', 'three', 'four', 'five', 'six']},
index = ['a', 'b', 'c', 'd', 'e', 'f'])
dataframe_data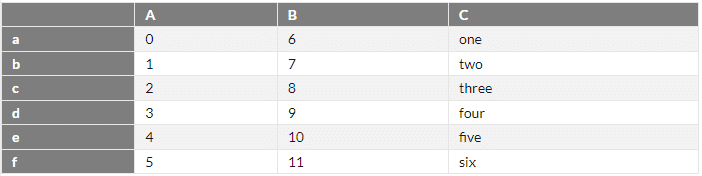
ファイルからの読み込みによる生成
ファイルの種類ごとにデータフレームを生成する方法を列挙する。ファイル名の指定部分は直接開けるオンライン上のURLを直接指定しても取得可能。
csvデータ
sepで区切り記号を指定できるので、csv以外のテキストデータのようなものもこの方法で処理できる可能性がある。
csv_data = pd.read_csv('iris_test.csv', # ファイル名の指定
# header = [0, 15], # xx行目を列名指定 []で複数行指定可能。指定した行より上は無視される。
# skiprows = xx # 上からxx行をスキップ
# skipfooter=1
# encoding='SHIFT-JIS' # 日本語が含まれるファイルの場合はSHIFT-JISを指定
# sep=',' # 区切りの記号指定。指定しない場合は","(csvのデフォルト)
)
csv_data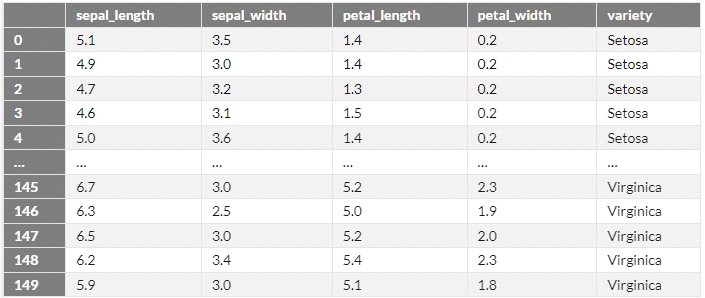
jsonデータ
サンプルで使用するjsonファイルの内容は次の通り。
print(open('sample.json').read()){ "name" : "John Smith",
"sku" : "20223",
"price" : 23.95,
"shipTo" : { "name" : "Jane Smith",
"address" : "123 Maple Street",
"city" : "Pretendville",
"state" : "NY",
"zip" : "12345" },
"billTo" : { "name" : "John Smith",
"address" : "123 Maple Street",
"city" : "Pretendville",
"state" : "NY",
"zip" : "12345" }
}このjsonファイルをデータフレームに読み込むと次のように整理される。
json_data = pd.read_json('sample.json', # ファイル名の指定
# encoding='SHIFT-JIS' # 日本語が含まれるファイルの場合は指定
)
json_data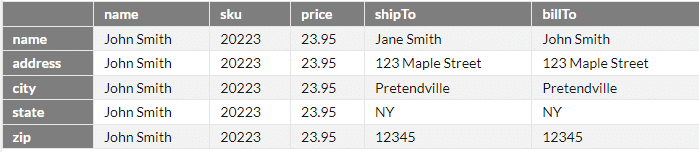
xmlデータ
サンプルで使用するxmlファイルの内容は次の通り。
print(open('sample.xml').read())<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book price="730" ISBN="1234" publicationdate="2018-05-12">
<title>hand</title>
<author>
<first-name>neko</first-name>
<last-name>inu</last-name>
</author>
<genre>string</genre>
</book>
<book price="6738" ISBN="5678" publicationdate="2019-05-27">
<title>foot</title>
<author>
<first-name>kabu</first-name>
<last-name>kotatsu</last-name>
</author>
</book>
</bookstore>lxmlも併せてインポートしておくことでread_xmlが使用可能。csvやjsonファイルと同様の方法で読み込みができ、要素名に番号や記号(以下のpriceやISBNなど)がある場合でもうまく抽出してくれる。
#Pandas ver 1.3 以上 book要素の抽出
pandas_data_1 = pd.read_xml('sample.xml', # ファイル名の指定
xpath='//book', # 抽出する要素をbookに指定
# encoding='UTF-8' # 日本語が含まれるファイルの場合は指定
)
pandas_data_1
#Pandas ver 1.3 以上 author要素の抽出
pandas_data_2 = pd.read_xml('sample.xml', # ファイル名の指定
xpath='//author', # 抽出する要素をauthorに指定
)
pandas_data_2
おまけ。Pandasのバージョンが1.3未満の場合はread_xmlが使用できない。その場合は以下の方法でもある程度抽出可能。
#Pandas ver 1.3 未満 直下の階層のみ抽出
xml_data = open('sample.xml').read()
root = ET.XML(xml_data) # element tree
all_records = []
for i, child in enumerate(root):
record = {}
for subchild in child:
record[subchild.tag] = subchild.text
all_records.append(record)
pandas_data_3 = pd.DataFrame(all_records)
pandas_data_3