
図書館蔵書の半自動予約 by Python①

プログラミングの基礎知識がない私が、デジタルファーストキャンプで学んだ内容を応用し、最終課題として提出したプログラムについてのnoteです。
試みたこと
図書館のサイトで1冊ずつ本を予約するのは面倒なので、Google spread sheetに本のリストを作成したら、あとはPythonのプログラムを走らせて自動で予約を行う、というもの。
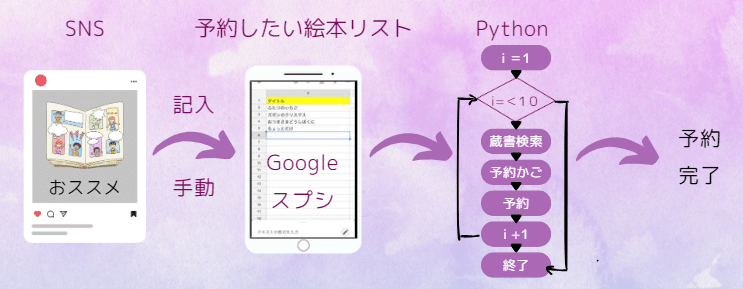
(前提)
まだ基本的な部分しかできていません。
例えば、”この蔵書はありません”などのエラーを処理するコードは盛り込めていません。
また、当然ながら各自治体で図書館サイトは異なりますので、ご自身の環境に合わせてアレンジしてください。
プログラム完成までの道のり
Dfcで学んだGoogle Colab上でのSeleniumを使用したWeb Scrapingを試したが、ログインすらできない。AIで対処するが、エラーが消えない。
Colabでは環境依存の問題が発生するようで、PCにPythonをインストールした。
Seleniumの代わりにPlaywrightというフレームワークを使おうとしたが、Playwrightの使い方が分からない…。
Git hubで公開されているPlaywrightを使ったWeb Scrapingのプログラムを書き換えようと試みた。プログラムの構造やコードの意味を理解しないまま、AIを頼りに改造したが、エラーを解消できず…。
Dfcの上ちゃんに相談したところ、参照していたプログラムが「関数と、関数の呼び出し」という基本構造になっていることを教えて頂いた。そのおかげで、プログラムのどこを修正すればいいのか理解でき、上記のプログラムを完成させることができた。
実施手順
紆余曲折を経ましたが、まとめるとこのような手順になります。
デスクトップにPythonをインストール
必要なライブラリのインストール
Google Spread sheetのAPIキーの取得
Google Spread sheetのJSON化
プログラムをご自身の環境に合わせて書き換える
プログラム
from playwright.sync_api import sync_playwright, expect
#from google.cloud import sheets
import requests
def login_and_take_screenshot(playwright, url, username, password, url2):
browser = playwright.chromium.launch()
context = browser.new_context()
page = context.new_page()
page.goto(url)
page.wait_for_load_state("load")
# ログイン処理
page.click('text=ログイン')
page.fill('[name="txt_usercd"]', username)
page.fill('[name="txt_password"]', password)
page.click('text=ログイン')
# spreadsheet data
response = requests.get(
'https://sheets.googleapis.com/v4/spreadsheets/10xxxxxxxxxxxQ/values/sheet1?key=Axxxxxxxxxxxxxng'
)
response.raise_for_status()
data = response.json()
# 検索キーワードをテキストボックスに入力
for index in range(1, len(data['values'])):
if data['values'][index] is None:
break
keyword = data['values'][index][0]
page.fill('[name="txt_word"]', keyword)
page.get_by_role('button', name='検索').click()
page.get_by_role('link', name='予約かごへ').click()
page.get_by_role('link', name='トップメニュー').click()
page.goto(url2) #MyLibrayの予約かご
page.get_by_role('link', name='全選択').click()
page.get_by_role('button', name='通常予約').click()
page.get_by_role('button', name='予約').click()
# スクリーンショットの取得
page.screenshot(path='screenshot.png')
# ブラウザを閉じる
browser.close()
if __name__ == '__main__':
# 以下はログインに必要な情報
url = 'https://www.------.jp/'
username = 'xxxxxxxx'
password = 'yyyyyyyy'
url2 = 'https://www.zzzzzzz.jp/'
with sync_playwright() as p:
login_and_take_screenshot(p, url, username, password, url2)
ご参考:
マニュアルのようになってしまい長文ですが、各手順について詳細を以下にまとめています。
この記事が気に入ったらサポートをしてみませんか?