漢字でGO!で自作問題を遊んでみる

おことわり
本記事は自作問題を遊ぶために既存問題とコードの改変を行います。予期せぬ不具合が生じる可能性もあるため、試される際は自己責任でお願いします。
また、漢字でGO!の問題やコードを改変した作品を二次配布することは公式で禁止されています。
また、原則として誤解を防ぐため、本ゲームの問題やコードを改変した作品を二次配布することは一切禁じます。
はじめに
漢字でGO!、面白いですね!
現在も積極的に問題追加などのアップデートがなされているので、まずは公式の問題を是非遊んでください。スマートフォン版もあります。
漢字の勉強になるので問題集を自作しゲーム内で遊んでみたいというニーズもあると思われます。一方で、記事執筆時点ではエディットモードは存在しません。ソースコードを軽く眺めると検討はされてそうですが、有料フォントを使用しているため実装のハードルは高そうです。ここは自力で自作問題を実装してみましょう。
【未定】エディットモードが欲しい
漢字は(JIS第3~を合成したり手書きで違和感のないよう表示するため)画像ファイルを使用しており、モードを考慮すると、ゲーム内部に画像を生成するジェネレータのようなものを作る必要がございます。
(中略)
セイビタカナワは有料フォントにつき、ジェネレーターのような仕様にするためには有料ライセンスを得る等の手続きが必要になる(あまり現実的ではないです)
フォントの規約上、とりわけ有料のフォントファイルはゲームフォルダ内に同梱できないことが多いです。(二次配布行為となってしまうため)
回答日時:2023年9月2日 午後0:40
以下の準備が必要です。Pythonの環境構築は各自で対応ください。
準備するもの
・漢字でGO! ダウンロード版
今回は1.0.8.0を使用しました。
・Python、pillow、OpenCVライブラリ
今回使用したバージョンです。
- Python:3.12.1
- pillow:10.2.0
- OpenCV:4.9.0
問題を自作する前に
ゲームの仕様を確認する
漢字でGO!はRPGツクールMVで製作されているゲームです。公式でダウンロード版が配布されており、こちらでJavascriptで記述されたソースコードが確認できます。

ゲーム内でこちらへ迫ってくる漢字はwww/img/picturesディレクトリ内に画像ファイルとして格納されており、www/excelData/Lv**.txtに問題の解答、説明文などが記述されています。これらの画像、テキストファイルを差し替えることで自作問題を遊ぶことができると思われます。
(今回は漢字を読む問題を作成しますが、上記仕様のためイラストや写真を答える問題も自作できそうです)

ちなみに、RPGツクールMVのリソース(画像、音楽など)はrpgmvpという規格で暗号化されています。「rpgmvp 変換」で検索すると復号化・暗号化するツールを提供するサイトがすぐ見つかるので、本記事では割愛します。
問題のフォーマット
問題はLv01.txt~Lv07.txtの中に記述されており、各問題が以下のようなフォーマットで管理されています。
問題:Lv01_0001
解1:ごうきゅう
解2:
解3:
送前:
送後:
文上:大声をあげて泣くこと。
文下:
配列:0
長い:0
ジャ:0
文数:0
サブ:0
カジ:0
珍回:
--------------------------------内容を解読してみました。
問題:レベルと問題番号で定義されており、同名のrpgmvgファイルと紐づいていると思われる。
解1~解3:解答となる読みが記載されている。複数解あれば解2以降に追記。
送前、送後:解説文の上に付く読みに送り仮名を付与していると思われる。
文上、文下:出題後に表示される解説文で、2段組みの上段と下段の内容がそれぞれ書かれている。
配列:最終問題の炎エフェクト用?
長い:長い問題がはみ出ないような処理で使っていると思われる。
ジャ:ジャンルを指定している。
文数:n文字指定問題のnを設定していると思ったが、何文字であっても1を設定している。解の文字数に合わせて自動で計算されている模様。
サブ、カジ、珍回:今回は触らないためスルー
検証
問題を差し替えて遊ぶことができるか実際に確認します。適当な画像ファイル(rpgmvp)をコピーし、他の問題画像ファイルと同名にリネームすることで全ての問題を同じ画像にしてしまいます。これでゲーム内に反映されればいいのですが…反映されません。
開発者ツールで確認するとどうやら問題はローカルではなくGitHubから読み込んでいるようです。ソースコードを探してみるとそれらしい箇所を発見しました。
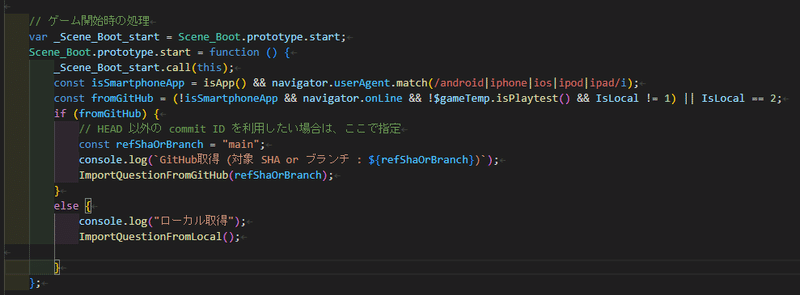
fromGitHubをfalseで上書きするとローカルでコピペした画像を読み込むことが確認できます。
テキストも同様にローカルで編集した内容が反映されました。
これで自作問題を遊べることは検証できたのですが、総問題数も変更できると麗しいです。
Map003.jsonに総問題数を設定していると思われる箇所があるので編集します。改行されてないjsonの中から頑張って探しましょう。
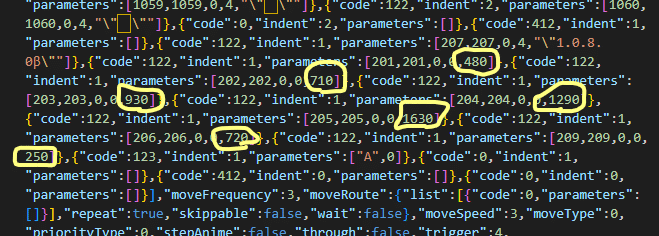
以上で自作問題を遊ぶ準備が整いました。いよいよ問題を自作していきます。
問題を自作する
方針
問題を自作するとして、数百~数千の問題テキストと画像を手作業で準備するのは大変なので、自動化に頼ります。
Pythonで問題集を読み込み問題テキストと画像を出力する簡易的なジェネレータを作ることにします。
フォントを準備する
自作問題を作るだけであればフリーフォントで十分ですが、せっかくなので公式っぽい問題画像を目指します。公式で使用されているフォントを確認すると、
ゲーム中の使用フォントが知りたい
基本フォント:わんぱくルイカ
解説などのフォント:Noto Sans
漢字のフォント:セイビタカナワ(B)
漢字のフォントはセイビタカナワBです。1万円以上が当たり前の有料フォントで6,600円は安いですね(錯乱)。ルビはNoto Sansで描かれているため、こちらも導入しましょう。
セイビタカナワBに収録されている漢字はJIS第一・第二水準+αなので、普通の問題であれば十分です。しかし、漢検1級の問題を作る場合は丫(あげまき、JIS第四水準)などの一部漢字が収録されていません。
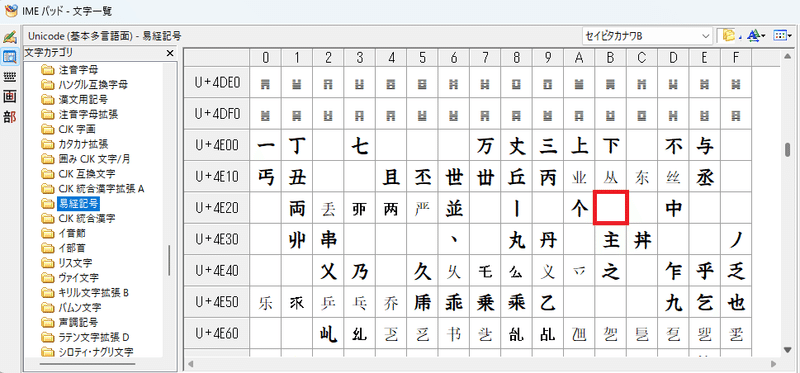
画像を作成してから別途ペイントソフトで手書きするという方法もありますが、ジェネレータで完結させたいのでフォントとして取り回しできるほうが都合が良いです。
今回は、書体の無い字をカバーするフォントを自作することで対応しました。この方法であれば、公式のレベル7で登場するような得体の知れない漢字も出題できます。
フォント自作はこちらの記事を参考にさせていただきました。
問題集を作成する
ジェネレータに食わせる問題集は表形式で作成します。

必要な列と記述内容は以下の通りです。上の例ではNo.列がありますが、無くても大丈夫です。CSV形式、UTF-8(BOM無)で保存しましょう。
漢字前、漢字、漢字後、ルビ:問題の画像に描画する内容です。詳細は下図を参照ください。ルビは●とひらがなで構成されます。
解1、解2、解3:読みの解答を書きます。
送前、送後:解説文の上に付く読みの解答に送り仮名を付与します。
Lv:問題のレベルです。1~7で定義します。
問題番号:ゲーム内で管理される番号です。各レベル毎に1番から番号を振ります。
文上、文下:出題後に表示される解説文です。2段組みの上段と下段の内容をそれぞれ書きます。
ジャンル:適切に設定することでジャンルを反映できます。

ジェネレータを作成する
以下のコードです。各自の環境に合わせて編集すべき箇所は次項で説明します。
import numpy as np
import csv
from pathlib import Path
from PIL import Image, ImageDraw, ImageFont
import cv2
# 問題を記述したCSVファイルのパスを指定
import_csv = r"C:\Users\user\kanji.csv"
# 画像のエクスポート先ディレクトリを指定
export_dir = r"C:\Users\user\Pictures\temp"
# 外字(=ベースフォントにない文字)の一覧を定義
extend = "丫𠄔"
# フォントのクラスを定義
class Font:
def __init__(self, path, index: int = 0):
self.path = path
self.index = index
# フォントのパスを指定
base_font = Font(r"C:\Users\user\sbkaib.ttc") # ベースフォント
extend_font = Font(r"C:\Users\user\seibitakanawa_extend.ttf") # 外字用フォント
ruby_font = Font(r"C:\Users\user\Downloads\Noto_Sans_JP\static\NotoSansJP-Black.ttf") # ルビ用フォント
# 画像のサイズ(幅, 高さ)を指定
width, height = 1680, 480
# 各文字のフォント、サイズ、色、位置情報を管理するクラス
class Char:
def __init__(self, char: str, font: Font, size: int, color):
self.char = char # 文字
self.font = font # フォント
self.size = size # サイズ
self.color = color # 色
self.position = (0,0) # 文字の左上の座標
self.xL, self.yT, self.xR, self.yB, self.descent = self.fontbboxdesc() # フォントのバウンディングボックスとディセントを取得
def set_position(self, x: int, y: int): # positionを設定
self.position = (x, y)
self.xL, self.yT, self.xR, self.yB, self.descent = self.fontbboxdesc() # フォントのバウンディングボックスとディセントを更新
def shift(self, x: int, y: int): # 現在の位置から移動
self.position = (self.position[0] + x, self.position[1] + y)
self.xL, self.yT, self.xR, self.yB, self.descent = self.fontbboxdesc() # フォントのバウンディングボックスとディセントを更新
def fontbboxdesc(self):
fontPIL = ImageFont.truetype(self.font.path, self.size, index = self.font.index) # PIL用のフォントを作成
_, descent = ImageFont.FreeTypeFont(self.font.path, self.size).getmetrics() # ディセントを取得
dummy_draw = ImageDraw.Draw(Image.new("L", (0,0))) # ダミーの描画オブジェクトを作成
xL, yT, xR, yB = dummy_draw.multiline_textbbox(self.position, self.char, font=fontPIL) # フォントのバウンディングボックスを取得
return [xL, yT, xR, yB, descent]
# 文字列の構成文字をリストで管理するクラス
class Text:
def __init__(self, text: str, font: Font, size: int, color):
self.text = list(map(lambda c, f, s, col: Char(c,f,s,col), list(text), font, size, color)) # 文字のリストを作成
def get_width(self, left: int = 0, right: int = -1):
return self.text[right].xR - self.text[left].xL # 文字列の幅を取得
def shift(self, x: int, y: int): # 文字列全体を現在の位置から移動
for c in self.text:
c.shift(x, y)
def vertical_aline(self): # 垂直方向でベースラインに合わせて揃える
sizemax = np.array(list(map(lambda c: c.size, self.text))).max() # 文字列に存在するフォントサイズの最大値
descentmax = np.array(list(map(lambda c: c.descent, self.text))).max() # 文字列に存在するディセントの最大値
for c in self.text:
y = (sizemax - c.size) - (descentmax - c.descent) # ベースラインが揃うy_offsetを計算
c.set_position(c.position[0], y)
def horizontal_cat(self, margin: list = [0]): # 水平方向に並べる marginは文字の間隔(負の値で狭める)
# marginはlistで記述 [0文字目と1文字目のmargin(無視), 1文字目と2文字目のmargin, ...]
# marginの要素数1の場合、全ての文字間に指定した値を適用する
if len(margin) == 1:
margin = margin * (len(self.text))
x = self.text[0].xL
for i, (c, m) in enumerate(zip(self.text, margin)):
if i > 0:
x = x + m # マージンを調整
c.set_position(x, c.position[1])
x = c.xR # 次の文字の左端の位置
def draw_text(self, img: Image.Image, fill = None):
draw = ImageDraw.Draw(img) # 描画オブジェクトを作成
for char in self.text:
fontPIL = ImageFont.truetype(font = char.font.path, size = char.size, index=char.font.index) # PIL用のフォントを作成
draw.text(char.position, char.char, font = fontPIL, # 文字を描画
fill = (char.color if fill == None else fill))
# フォントを設定する関数
def font_setting(char: str):
if char in extend: # 外字判定
return extend_font # 外字用フォントを指定
else:
return base_font
# 文字サイズを設定する関数
def size_setting(char: str):
if char == "2": # 読む漢字
return 280
else: # 送り仮名
return 220
# ルビの文字サイズを設定する関数
def rubysize_setting(char: str):
if char == "●": # ルビが●
return 68
else: # ルビが●ではない
return 75
# 文字色を設定する関数
def color_setting(char: str, lv):
lv = int(lv)
if char == "1": # 送り仮名の場合
return "white"
elif lv < 4: # Lv1~3
return "#F9F089"
elif lv < 6: # Lv4~5
return "#F6B455"
elif lv < 7: # Lv6
return "#EE5E25"
else: # Lv7
return "#BC70FC"
# テキストに問題を書き込む関数
def write_quiz(row):
write_mode = "a" # appendモードを既定にする
if row["問題番号"]=="1":
write_mode = "w" # 問題番号1であれば新規作成
if row["ジャンル"] == "":
row["ジャンル"] = 0
moji_shitei = int(len(row["ルビ"]) > 0) # 文字数指定あり
arr = "1"*len(row["漢字前"]) + "2"*len(row["漢字"]) + "1"*len(row["漢字後"]) # 配列を作成 1:送り仮名等 2:漢字
islong = int(len(arr) > 4) # 問題の文字数が5文字以上でlong
quiz_list = [
"問題:Lv{}_{}".format(row["Lv"].zfill(2), row["問題番号"].zfill(4)),
"解1:{}".format(row["解1"]),
"解2:{}".format(row["解2"]),
"解3:{}".format(row["解3"]),
"",
"送前:{}".format(row["送前"]),
"送後:{}".format(row["送後"]),
"",
"文上:{}".format(row["文上"]),
"文下:{}".format(row["文下"]),
"",
"配列:{}".format(arr),
"長い:{}".format(islong),
"",
"ジャ:{}".format(row["ジャンル"]),
"文数:{}".format(moji_shitei),
"サブ:0","カジ:0","珍回:",
"--------------------------------"
]
print(quiz_list)
# excelDataフォルダを作成
quizdir = Path(export_dir, "excelData")
quizdir.mkdir(parents=True, exist_ok=True)
quizpath = Path(quizdir, "Lv{}.txt".format(row["Lv"].zfill(2)))
# 問題をtxtファイルに書き込む
with open(quizpath, write_mode, encoding='utf-8') as f:
f.writelines("%s\n" % item for item in quiz_list)
# 漢字部分の描画設定を行う関数
def kanji_draw_setting(row):
question = row["漢字前"] + row["漢字"] + row["漢字後"] # 画像に書き込む問題文
arr = "1"*len(row["漢字前"]) + "2"*len(row["漢字"]) + "1"*len(row["漢字後"]) # 読み対象を判別する配列を作成 1:送り仮名等 2:漢字
font = list(map(lambda char: font_setting(char), list(question)))
size = np.array(list(map(lambda kana: size_setting(kana), list(arr))))
color = list(map(lambda kana: color_setting(kana, row["Lv"]), list(arr)))
q = Text(question, font, size, color)
## ----- ここから組版 ----------------
margin = [-20] # 文字の間隔(px) マイナスで狭める リストで格納
q.vertical_aline() # 高さ揃え
q.horizontal_cat(margin) # 指定間隔で横に並べる
# 中央寄せ
w, h = q.get_width(), size.max() # 文字列全体の幅、高さ
q.shift((width - w) / 2, (height - h) / 2) # 中央にシフト
## -----------------------------------
return q
# ルビ部分の描画設定を行う関数
def ruby_draw_setting(row, kanji: Text):
rfont = [ruby_font] * len(row["ルビ"])
rsize = np.array(list(map(lambda char: rubysize_setting(char), list(row["ルビ"]))))
rcolor = ["#d6fafd"] * len(row["ルビ"])
rb = Text(row["ルビ"], rfont, rsize, rcolor)
## ----- ここから組版 ----------------
margin = [9] # 文字の間隔(px) マイナスで狭める
size75 = (rsize == 75)
margin = np.array(margin * len(rb.text)) - 5 * (size75 | np.roll(size75, 1)) # sizeが75の文字の両端だけマージンを5縮める
rb.vertical_aline()
rb.horizontal_cat(list(margin))
# 漢字の上にルビを中央寄せで配置する
rw, rh = rb.get_width(), rsize.max() # ルビの幅、高さを計算
arr = "1"*len(row["漢字前"]) + "2"*len(row["漢字"]) + "1"*len(row["漢字後"]) # 読み対象を判別する配列を作成 1:送り仮名等 2:漢字
kw = kanji.get_width(arr.find("2"), arr.rfind("2")) # 漢字部分の幅
for c in rb.text:
c.shift(q.text[arr.find("2")].position[0] + (kw - rw)//2,
q.text[arr.find("2")].position[1] - rh - 30)
## -----------------------------------
return rb
# imgを膨張させる関数
def stroke(img):
new_img = cv2.cvtColor(np.array(img, dtype=np.uint8), cv2.COLOR_RGBA2BGRA)
ellipse_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (19,19)) # 半径9pxの楕円カーネル
kernel = ellipse_kernel | ellipse_kernel.T # 楕円カーネルを転置してandをとる
dst = cv2.dilate(new_img, kernel) # カーネルで膨張
img = Image.fromarray(cv2.cvtColor(dst, cv2.COLOR_BGRA2RGBA))
return img
with open(import_csv, 'r', encoding='utf-8') as csv_file:
f = csv.DictReader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True)
for row in f:
print(row)
write_quiz(row) # 問題のtxtを作成
# picturesフォルダを作成
picdir = Path(export_dir, "img", "pictures")
picdir.mkdir(parents=True, exist_ok=True)
q = kanji_draw_setting(row)
# 縁どり用の文字列をimgに描画
img = Image.new('RGBA', (width, height), (0, 0, 0, 0)) # 透過pngを作成
q.draw_text(img, fill='black')
# 文字列をimg2に描画
img2 = Image.new('RGBA', (width, height), (0, 0, 0, 0))
q.draw_text(img2)
# ルビがあれば追記
if row["ルビ"] != "":
rb = ruby_draw_setting(row, q)
rb.draw_text(img, fill='black')
rb.draw_text(img2)
img = stroke(img) # imgを9px膨張させる
img.paste(img2,(0,0),img2) # 縁取り文字列の上から縁なし文字列を重ねる
# pngで保存
picpath = Path(picdir, "Lv{}_{}.png".format(row["Lv"].zfill(2), row["問題番号"].zfill(4)))
img.save(str(picpath))
ジェネレータ作成にあたってはこちらのサイトを参考にさせていただきました。
画像を生成する
ジェネレータ実行前に編集する箇所です。
# 問題を記述したCSVファイルのパスを指定
import_csv = r"C:\Users\user\kanji.csv"
# 画像のエクスポート先ディレクトリを指定
export_dir = r"C:\Users\user\Pictures\temp"
# 外字(=ベースフォントにない文字)の一覧を定義
extend = "丫𠄔"
(中略)
# フォントのパスを指定
base_font = Font(r"C:\Users\user\sbkaib.ttc") # ベースフォント
extend_font = Font(r"C:\Users\user\seibitakanawa_extend.ttf") # 外字用フォント
ruby_font = Font(r"C:\Users\user\Downloads\Noto_Sans_JP\static\NotoSansJP-Black.ttf") # ルビ用フォントimport_csv:問題を記述したCSVファイルのパス。
export_dir:画像とテキストを出力するディレクトリのパス。
extend:外字を文字列で並べる。ここで指定した字はextend_fontで設定したフォントで表示。
base_font, extend_font, ruby_font:それぞれベースフォント、外字用フォント、ルビ用フォントをFontインスタンスで設定する。第一引数でパス、第二引数でフォントファイル内から参照したい書体のindexを指定。
編集後、ジェネレータを実行してみましょう。
適切に準備されていれば、出力先のディレクトリに画像とテキストファイルが生成されていると思います。環境にもよりますが、1000問あたり2分程度かかります。
出力内容に問題がなければ画像をrpgmvpに変換しましょう。
サンプル
ジェネレータにより出力された画像のサンプルです。


自作問題を遊べるようにする手順
以上は自作問題を一から作成する手順でした。
問題一式が準備できたら、以下の手順で自作問題を遊べます。
www/img/pictures/Lv**_****.rpgmvp、www/excelData/Lv**.txtを自作した問題で上書きする。
QuestionImport.jsの85行目をconst fromGitHub = false;に書き換える。
Map003.json内の総問題数を定義している箇所(下図参照)を、差し替えた問題数に書き換える。
起動時の自動アップデートを防ぐため、GitHubAutoUpdater.jsの58~66行目をコメントアウトするか削除する。
これでとりあえず遊べることは確認しましたが、予期せぬ不具合が起こる可能性もあるため、改変は自己責任でお願いします。また、このような改変を加えたゲームプログラムの二次配布は絶対に行わないようにお願いします。
おわりに
以上で自作問題を遊べるようになりました。
おまけで今回トライで作成した問題のリソースを置いておきます。差し替えの動作確認にでもどうぞ。
ポケモンの繁体中文名読み問題
・pngはrpgmvpに変換が必要です。
・フォント作成をサボるため繁体字とフォントが無い字の一部は新字体・異体字に置換してます。
・全1025問(Lv3:75問, Lv4:200問, Lv5:560問, Lv6:190問)
・ゲキムズ+で遊ぶことを想定してます。
この記事が気に入ったらサポートをしてみませんか?