
雑記 GPT2-japaneseを使って詩を描く

世の中はAIを持て囃す。
資本化する人類に「自我はいらない」
だからこそ自我を持ち、このクソッタレの世界から離れることも必要だ。機械学習の手を借りて、人間をやる時間を増やしていこう。
今回ChatGPTを使って機械学習をさせて文章を自動生成してみたので、やったことも含めて記事に整理しておく。
ちなみに、記事TOPに載せているのが実際に作ったものになる。
分かったことは、巷でAIと呼ばれるものが活用されるのであれば、技術的な側面のハードルを越えてやりたいことが簡単に実現させられる。
仕事や生き方も変えていかないとこの先生き残れない。プログラムスクールに通うだとか、資格を取るだとか、なんかそんな漠然とした目的観だけでは、厳しいんだろうなと感じた。
足元ではWWⅢの姿が見え隠れし、過去の戦争の反省はなくただ指を咥えて見ているだけに等しい。こうした暴力の流れを打ち砕くには、多くの人々の余暇をもっと増やさないと世界全体で圧力を掛けられない。
日々「殺すな」を願い、思い、それだけ。
気軽に話して、活動して、よりよくなるように願う。活動こそ、人間がしなければならない。けれど、賃金は減り、労働時間は減ることもなく、いたずらに体を休めるだけの日々が続いている。
かくいう僕もchatGPTにはお世話になって、VBAや Pythonやらで延々と続く数値世界を楽に出来ないか、日々悩んでいる。
どうやら人材不足は全てに及び、仕事をしながら一次産業もやる必要に迫られる。農業のメインは60代だから、10年後続けられるとは思えない。
であるなら、仕事をバチクソ楽にして作った余裕で農水産に携わる必要に駆られるかもしれない。(移民を増やすと国は言うが、問題はそこにない。いつだってやらなくちゃいけないことは隅に追いやられる。我々はこの馬鹿馬鹿しさにいつまでつき合わなければならないのだろう。)
そんなわけで、これまで携わっていた技術だけでなく機械学習を自分でやってみる価値はある。
色々な記事は出ているが、
Pythonを使った機械学習をchatGPTに教わろう。
そうしてやってみたのが3/27で、完成したのが4/4なので、素人が始めてもそれなりに時間を掛けずにとりあえず動くものが作れることが分かった。
【成果】
・何らかの文章が生成出来た。
・初歩的なPythonの書き方、Pycharmの使い方の習得。
【やりたいこと】
・自分の詩、又は小説を自動生成したい。
これによって、自分自身の頭の働きを遺せるようになりたい。
【準備物】
・ChatGPT
・Python開発ソフト(Pycharm)
・これまで書いて来た詩700作ほど↓
https://kakuyomu.jp/works/16816452221143234638
⓪Python開発環境の導入
これは単純に、Pycharmの使い方教えてと聞いた。一般的な事だけ出力されたので役に立たなかったため「Pycharmの使い方」で出て来た記事を流し読みして導入した。
①RNN(リカレントニューラルネットワーク)の学習
「格納されている .txtファイルのファイル名とテキストデータを学習させて、同様の形態となる指定した文字数分のテキストデータを生成することは可能でしょうか?」と聞いたら出て来たもの。
(煩雑なので、記事の一番最後に載せておく。)
一発目に聞いて出て来たものの、これはそのまま使えなかった為、何度かエラー文をchatGPTに張り付けて解決策を聞きつつ、似たようなことやっている記事もあるのでQiitaなどで色々見ながら修正した。
時間がかかった様に思えて、3日。色々調べて回っていたのは合計で6時間くらい。仕事が終わって帰ってきてから少しずつやってもなんとかなった。
その時に出力出来た文字列は以下。

②GPT2-Japaneseを使った文章生成
あまり使えなかった①の問題点は以下の2つ。
・自分の文章だけ学習させると限られた文字列からしか文章生成が出来ない
・学習させるほど過学習が強まって、文章にすらならない
なので、ちゃんと日本語に特化したGPT-2の大規模言語モデルを使うことにして、ChatGPTに「GPT2-japaneseを使用した文章のファインチューニングとテキスト生成する方法を教えてください。」と聞いてコードを出してもらった。(GPTの発音、ドイツだとゲーぺーテーになるのだろうか?)
こちらも同じように聞いて出て来たコードを何も考えず実行→エラーが出たら質問→解決しなければwebで検索する。
そんなことを繰り返して2日、こちらも6時間くらいで出来た。
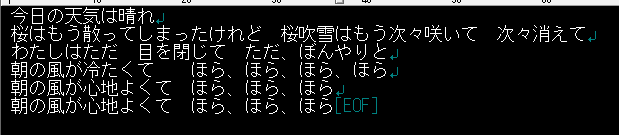
結果
月並みな総評にはなるが、専門的なものを作ろうとした場合、おそらくこんなにはうまくいかない。ChatGPTが出してくれるのはあくまで一般的なもので、web上にあるもの以外はあんまり役に立たない。
けれども、ざっくりとやりたいことに対してコードは書いてくれるし、すぐ動かせて手軽に「できた! 嬉しい!」を体験できるので、取っ掛かりには非常に役に立つ。
それに、GPT2で学習させたものは、それっぽくこれまで書いて来た文章を再現出来ていそうだし、過去を振り返って想像力を掻き立てるのに使えそうでもある。
つまり、面白可笑しく使える玩具が出来た。それだけでも十分な収穫だったと思う。
また、色々なことが自分で出来ると思えてきたので、他の手法なども調査していきたい。
参考
以下は実際に作成したプログラム。ほぼほぼChatGPTなのでなんとも言えないが、プログラムは考えるより慣れろ、みたいな側面があるのでこういう感じで何度も作って流して、作ってを繰り返すのは役に立つはずだ。(詩や小説なんかも効率は悪いが、沢山作るのは意味がある。)
①で作ったプログラム
import os
import torch
import torch.nn as nn
import numpy as np
# 指定のフォルダ内のすべての .txt ファイルのパスを取得
def get_text_files(folder_path):
text_files = []
for file_name in os.listdir(folder_path):
if file_name.endswith('.txt'):
text_files.append(os.path.join(folder_path, file_name))
return text_files
# 指定のフォルダ内のすべての .txt ファイルのテキストデータを結合して返す
def concatenate_text_files(folder_path):
text_data = ""
text_files = get_text_files(folder_path)
for file_path in text_files:
with open(file_path, 'r', encoding='utf-8') as file:
text_data += file.read()
return text_data
# テキストデータの前処理
def preprocess_text(text):
tokens = text.split() # 簡易的なトークン化
return tokens
# テキストデータを学習データに変換する
def create_dataset(tokens, seq_length):
dataset = []
for i in range(len(tokens) - seq_length):
seq = tokens[i:i + seq_length]
target = tokens[i + seq_length]
dataset.append((seq, target))
return dataset
# RNNモデルの定義
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.rnn = nn.RNN(hidden_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden):
x = self.embedding(x)
output, hidden = self.rnn(x, hidden)
output = self.fc(output)
return output, hidden
# 指定のフォルダ内のすべての .txt ファイルのテキストデータを結合
folder_path = "/python"
text_data = concatenate_text_files(folder_path)
print(text_data)
# テキストデータの前処理
tokens = preprocess_text(text_data)
# トークンのユニークな数を取得
vocab = sorted(set(tokens))
vocab_size = len(vocab)
# テキストデータを学習データに変換
seq_length = 20
dataset = create_dataset(tokens, seq_length)
# ここから先は学習の手順を実行していきます
# トークンをインデックスにマッピングする辞書を作成
word_to_index = {word: i for i, word in enumerate(vocab)}
index_to_word = {i: word for i, word in enumerate(vocab)}
# パラメータの設定
seq_length = 20
input_size = vocab_size
hidden_size = 128
output_size = vocab_size
learning_rate = 0.001
num_epochs = 50
# データセットの作成
dataset = create_dataset(tokens, seq_length)
# モデルの初期化
model = RNN(input_size, hidden_size, output_size)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 学習
for epoch in range(num_epochs):
for i, (seq, target) in enumerate(dataset):
inputs = torch.tensor([word_to_index[word] for word in seq], dtype=torch.long)
target = torch.tensor([word_to_index[target]], dtype=torch.long)
# 隠れ状態の初期化
hidden = torch.zeros(1, 1, hidden_size)
# 勾配の初期化
optimizer.zero_grad()
# フォワードプロパゲーション
outputs, _ = model(inputs.view(1, -1), hidden)
loss = criterion(outputs.view(1, -1), target)
# バックプロパゲーションとパラメータの更新
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(dataset)}], Loss: {loss.item():.4f}')
print('Finished Training')
# 学習済みモデルの保存
torch.save(model.state_dict(), 'rnn_model.pth')
# 新しいテキストデータの生成
def generate_text(model, start_sequence, length):
generated_text = start_sequence
input_sequence = []
for word in start_sequence.split():
if word in word_to_index:
input_sequence.append(word_to_index[word])
else:
# 辞書内に存在しない単語がある場合は処理を中断
print(f"Word '{word}' not found in vocabulary.")
return ""
hidden = torch.zeros(1, 1, hidden_size)
for i in range(length):
inputs = torch.tensor(input_sequence[-seq_length:], dtype=torch.long).view(1, -1)
outputs, hidden = model(inputs, hidden)
_, predicted_indices = torch.max(outputs, 2)
predicted_index = predicted_indices[0][-1].item() # 最後の要素のインデックスを取得
predicted_word = index_to_word[predicted_index]
generated_text += ' ' + predicted_word
input_sequence.append(predicted_index) # 予測されたインデックスを入力シーケンスに追加
return generated_text
# テキストの生成
start_sequence = "深く、体に根付いたもの"
generated_text = generate_text(model, start_sequence, length=100)
print(generated_text)②で作ったプログラム
from transformers import GPT2Tokenizer, GPT2LMHeadModel, TextDataset, DataCollatorForLanguageModeling, Trainer, TrainingArguments, AutoTokenizer, AutoModelForCausalLM
import os
import torch
# 指定のフォルダ内のすべての .txt ファイルのテキストデータを結合
folder_path = "/python"
# 指定のフォルダ内のすべての .txt ファイルのパスを取得
def get_text_files(folder_path):
text_files = []
for file_name in os.listdir(folder_path):
if file_name.endswith('.txt'):
text_files.append(os.path.join(folder_path, file_name))
return text_files
# 指定のフォルダ内のすべての .txt ファイルのテキストデータを結合して返す
def concatenate_text_files(folder_path):
text_data = ""
text_files = get_text_files(folder_path)
for file_path in text_files:
with open(file_path, 'r', encoding='utf-8') as file:
text_data += file.read()
return text_data
text_data = concatenate_text_files(folder_path)
# テキストデータをファイルに書き出す
with open("combined_text.txt", "w", encoding="utf-8") as file:
file.write(text_data)
# 2. トークナイザーの準備
model_path ="rinna/japanese-gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 3. モデルの読み込み
model = AutoModelForCausalLM.from_pretrained(model_path)
#データセットの設定
# テキストデータが書き出されたファイルを TextDataset に渡す
train_dataset = TextDataset(
tokenizer=tokenizer,
file_path="combined_text.txt", # 結合されたテキストデータのファイルパスを指定
block_size=128, # ブロックサイズを指定(文章の長さを揃えるためのサイズ)
)
#データの入力に関する設定
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
# 訓練に関する設定
training_args = TrainingArguments(
output_dir="./gpt2-finetuned", # 関連ファイルを保存するパス
overwrite_output_dir=True, # ファイルを上書きするかどうか
num_train_epochs=3, # エポック数
per_device_train_batch_size=32, # バッチサイズ
logging_steps=1000, # 途中経過を表示する間隔
save_steps=5000, # モデルを保存する間隔
save_total_limit=2,
)
#トレーナーの設定
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
)
trainer.train()
# 6. モデルの保存
model.save_pretrained("finetuned-gpt2-japanese")
# 1. ファインチューニング後のモデルの読み込み
model_path ="rinna/japanese-gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(model_path)
tokenizer.do_lower_case = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 学習したモデルを読み込む
model = AutoModelForCausalLM.from_pretrained("finetuned-gpt2-japanese")
model.to(device)
model.eval()
# 2. テキスト生成
seed_sentence = "凪いでいる空、赤くひろく"
input_ids = tokenizer.encode(seed_sentence, return_tensors="pt",add_special_tokens=False).to(device)
num = 1
# テキスト生成の設定
with torch.no_grad():
output = model.generate(
input_ids,
max_length=400,
min_length=400, # 最短の文章長
do_sample=True,
top_k=500, # 上位{top_k}個の文章を保持
top_p=0.95, # 上位{top_p}%の単語から選択する。例)上位95%の単語から選んでくる
temperature=1.2,
num_return_sequences=1,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
early_stopping=True,
bad_word_ids=[[tokenizer.unk_token_id]],
# num_return_sequences=num # 生成する文章の数
)
# 3. 生成されたテキストをデコードして出力
decoded = tokenizer.batch_decode(output,skip_special_tokens=True)
formatted_text = ""
char_count = 0
for char in decoded:
formatted_text += char
char_count += 1
if char == " " and char_count > 50: # スペースで改行
formatted_text += "\n"
char_count = 0
print(formatted_text)釘を打ち込み打ち込まれる。 そんなところです。