
ComfyUIでWD 1.4 TaggerとMiaoshouAI Taggerを利用したi2i(FLUX.1編)

※ Last update 09-24-2024
※ 5.にて、様々な画像でi2iを試みていますので、先にご覧いただければと思います。
※ 前の記事(SDXL編)で導入したMiaoshouAI Taggerに加えて、WD 1.4 Tagger及びTagger用の新しいモデルを導入します。
※ カスタムノードの導入方法は、Windows向けに書いてあります。
■ 0. 概要
▼ 0-0. 注意事項
本記事ではi2i(image to image)を扱っています。i2iそのものが悪いわけではありませんが、他者の権利を侵害しない、ディープフェーク画像を作成しないなど、十分な注意を払ってください。
▼ 0-1. 本記事について
前の記事(SDXL編)では、ComfyUI用のMiaoshouAI Tagger(Microsoft Florence-2モデルに基づく高度な画像キャプションツール)を用いてキャプションを取得したり、そのキャプションを利用してi2iを行ったりしました。
本記事はFLUX.1とComfyUI WD 1.4 Taggerを利用して、同様の試みを行います。また、MiaoshouAI Taggerも利用します。
■ 1. MiaoshouAI Taggerの導入
今夏に登場したMicrosoft Florence-2モデルを利用する、性能が良い(とみられる)Taggerです。導入方法は前の記事(下記)に書いてあります。
■ 2. ComfyUI WD 1.4 Taggerの導入
Gitが導入済みであることを前提としています。
▼ 2-1. ComfyUIへの準備1
本記事のワークフローを利用するためには、ComfyUI-Custom-Scriptsが必要です。
ComfyUI-Custom-Scripts
https://github.com/pythongosssss/ComfyUI-Custom-Scripts
もし「ComfyUI\custom_nodes\ComfyUI-Custom-Scripts」が存在しない場合は、1.で紹介した記事の1-3.あたりを参照してインストールしてください。
▼ 2-2. ComfyUIへの準備2
下記URLの拡張機能をインストールして、必要なパッケージを導入します。ComfyUIを終了した状態で始めてください。
ComfyUI WD 1.4 Tagger
https://github.com/pythongosssss/ComfyUI-WD14-Tagger
コマンドプロンプトを開いてから「ComfyUI\custom_nodes」へ移動して、下記のコマンドを実行します。
git clone https://github.com/pythongosssss/ComfyUI-WD14-Tagger続いて、必要なパッケージをインストールします。下記のコマンドはポータブル版の場合です。
..\..\python_embeded\python.exe ..\..\python_embeded\Scripts\pip.exe install -r ComfyUI-WD14-Tagger\requirements.txt通常版の場合(ComfyUIのインストール先にvenvディレクトリがある)は、下記のコマンドを順に実行してください。
..\venv\Scripts\activate
pip install -r ComfyUI-WD14-Tagger\requirements.txt
deactivate手順が完了したらコマンドプロンプトを閉じます。なお、本当にすぐ閉じてしまう場合は、「deactivate」は不要です。
▼ 2-3. ComfyUIへの準備2
次にTaggerの新しいモデルをダウンロードします。なお、この情報はでんでんさんの記事で知りました。Stable Diffuison Web UIでの導入方法について記載されています。
新しいモデルは https://huggingface.co/SmilingWolf をチェックしましょうということが記事に書かれていました。実際、WD 1.4 Tagger用の様々なモデルが掲載されています。
本記事では、現時点で最新かつ性能の良いWD EVA02-Large Tagger v3を選択します。ダウンロードしたファイルは、下記のとおり名前を変更した上で移動してください。ディレクトリの作成が必要です。
WD EVA02-Large Tagger v3
https://huggingface.co/SmilingWolf/wd-eva02-large-tagger-v3
model.onnx → wd-eva02-large-tagger-v3.onnx
selected_tags.csv → wd-eva02-large-tagger-v3.csv
ComfyUI\custom_nodes\ComfyUI-WD14-Tagger\models へ移動
▼ 2-4. 簡単なワークフローで動作確認
この項目は読み飛ばしても構いません。画像を読み込んでTaggerを実行するだけの簡単なワークフローを実行します。下記のファイルをダウンロードしたら、ComfyUIの画面にドラッグ&ドロップします。非常に簡単なので、自分で作れそうな方はチャレンジしてください。
「Load Image」のノードに画像ファイルをドラッグ&ドロップするか、「choose file to upload」をクリックしてファイルを選択します。モデルは「wd-eva02-large-tagger-v3」を選択します(ワークフローでは選択済み)。
あとは、メニューの「Queue Prompt」をクリックします。解析は数秒程度で終わり、画像のキャプションが表示されます。
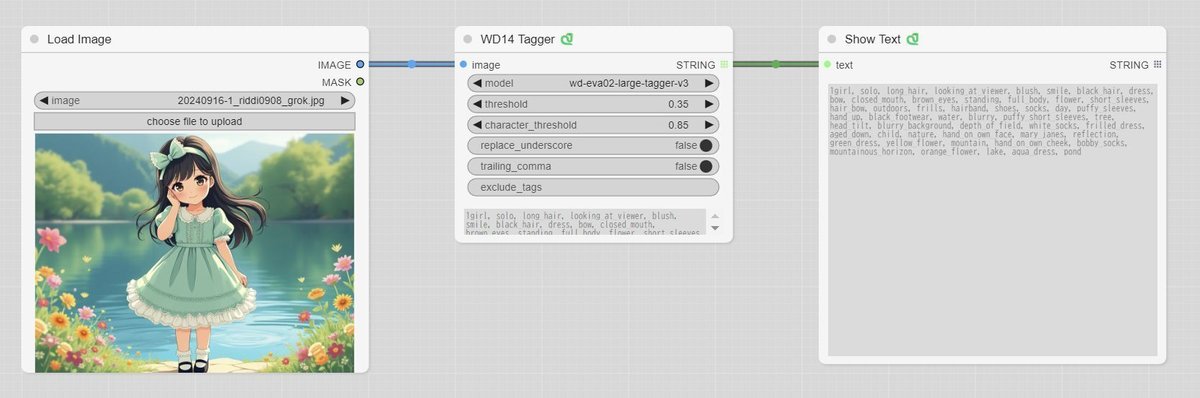
別のモデルを選択して実行した場合は、モデルが自動的にダウンロードされます。保存場所やファイル名は先ほどと同様でした。
▼ 2-5. ComfyUI WD 1.4 Taggerの説明
簡単に設定項目を紹介しておきます。
model
解析に利用するモデルを指定します。ダウンロードは自動的に行われます。threshold (default=0.35)
解析したタグにはスコア(一致率)が振られていて、この値より低いタグは結果のキャプションから除外されます。character_threshold (default=0.85)
キャラクター(人物)用のthresholdです。replace_underscore (default=false)
デフォルトのfalseでは「frilled_dress」と表現されるタグが、trueに変更すると「frilled dress」になります。trailing_comma (default=false)
値をtrueに変更すると、キャプションの末尾にカンマを付けます。exclude_tags
キャプションから不要なタグを取り除くためのものです。カンマ区切りで記述します。タグの中の一部だけを削除することはできません。
thresholdについての補足です。例えばthreshold=0.95に設定すると、人物以外のタグがほとんど消えます。この状態でcharacter_threshold=0.95にすると「1girl, solo, dress, 1girl, solo, dress」のみが残ります。ここから character_threshold=0.90 に下げると「1girl, solo, long hair, black hair, dress, flower, shoes, black footwear, 1girl, solo, dress」となり、タグが増えます。
以上のことから、i2iでキャプションを用いる場合は、thresholdを高めに設定して、誤ったタグが含まれないようにしておくのが良さそうです。
■ 3. 利用するモデルについて
モデルの準備が済んでいる方は読み飛ばしてください。ここでは標準の FLUX.1 Dev と、低Steps生成のためのHyper-FLUX.1-dev-8stepsを利用します。FLUX.1で生成できる環境を整えていない方は続きをご覧ください。
▼ 3-1. 利用するモデル(FLUX.1)
前述のとおり、FLUX.1 Dev を利用します。Black Forest Labsのオリジナルではなく Comfy Org(ComfyUI開発元)が配布する、CLIPとVAEが内蔵されたAll-in-oneモデルとします。
flux1-dev
https://huggingface.co/Comfy-Org/flux1-dev
flux1-dev-fp8.safetensors
ComfyUI\models\checkpoints へ移動
Hyper-FLUX.1により、8 Stepsでの高速な生成ができます。ただし、生成する画像の品質が若干低下しますのでご了承ください。
Hyper-FLUX.1
https://huggingface.co/ByteDance/Hyper-SD
Hyper-FLUX.1-dev-8steps-lora.safetensors
ComfyUI\models\loras へ移動
▼ 3-2. 他のモデル(オプション1)
CLIPとVAEが内蔵されていないFLUX.1 Devのモデルを利用する場合は、下記のファイルが必要です。ワークフローの修正が必要です。
flux-fp8 (DiT only)
https://huggingface.co/Kijai/flux-fp8
flux1-dev-fp8-e4m3fn.safetensors
ComfyUI\models\unets へ移動
※ e5m2形式もあるがe4m3fnが主流とみられる
下記のt5xxlについては、片方のみで(もちろん両方でも)結構です。PCのメインメモリが32GB以上の場合はt5xxl_fp16を推奨とのことです。逆に、リソースに余裕がない場合はt5xxl_fp8が良いでしょう。
clip (text encoder)
https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main
clip_l.safetensors
t5xxl_fp16.safetensors
t5xxl_fp8_e4m3fn.safetensors
ComfyUI\models\clip へ移動
VAEも必要です。ワークフローでは拡張子が当初のsftになっていますが、現在はsafetensorsに変更されています。中身は同じです。
vae
https://huggingface.co/black-forest-labs/FLUX.1-dev
ae.safetensors
ComfyUI\models\vae へ移動
▼ 3-3. 他のモデル(オプション2)
NF4形式やGGUF形式はLoRAが利用できないようなので注意してください。ワークフローの修正が必要で、各形式に対応する手順も必要です(下記)。前項のCLIPとVAEも必要です。
flux1-nf4-unet
https://huggingface.co/silveroxides/flux1-nf4-unet/tree/main
flux1-dev-nf4-unet.safetensors
ComfyUI\models\unets へ移動
※ 元となるAll in oneモデルもある
FLUX.1-dev-gguf
https://huggingface.co/city96/FLUX.1-dev-gguf
flux1-dev-Q4_0.gguf 等
ComfyUI\models\unets へ移動
※ サイズが小さいほど省リソースになるが品質も低下する
NF4やGGUF形式に対応するためには、カスタムノードの追加が必要です。手順は下記の記事を参照してください。
■ 3. FLUX.1版のi2i(Taggerは表示のみ)
シンプルなi2iのワークフローと実行例を掲載します。説明を大幅に減らしているため、詳細は前の記事を参照してください。
▼ 3-1. 概要(ワークフロー、画像付)
画像ファイルとプロンプトを入力して、単純なi2iを行います。表示された画像のキャプションを参考に、プロンプトの調整ができます。
下記はワークフローの留意点です。
デフォルトはWD 1.4 Taggerを利用してキャプションを表示する
MiaoshouAI Taggerのノードはミュートしてある(利用する場合はワークフローの修正が必要)
両方のTaggerがインストールされていないとエラーが出る(インストールしていない方のTaggerのノードを消せば問題ない)
i2iで使用する画像はGrokで生成しました。プロンプトはClaudeに作らせたものを微修正しています。

▼ 3-2. 実行
設定が正しければ、メニューの「Queue Prompt」をクリックするとフローが実行されます。うまくいかない場合は、該当するノードが目立つ色に変化しますので見直してください。
処理が始まると、キャプションが表示された後でi2iの生成が行われます。低Stepsで時短していますが、それでもPCのスペックによっては多少の時間がかかります。
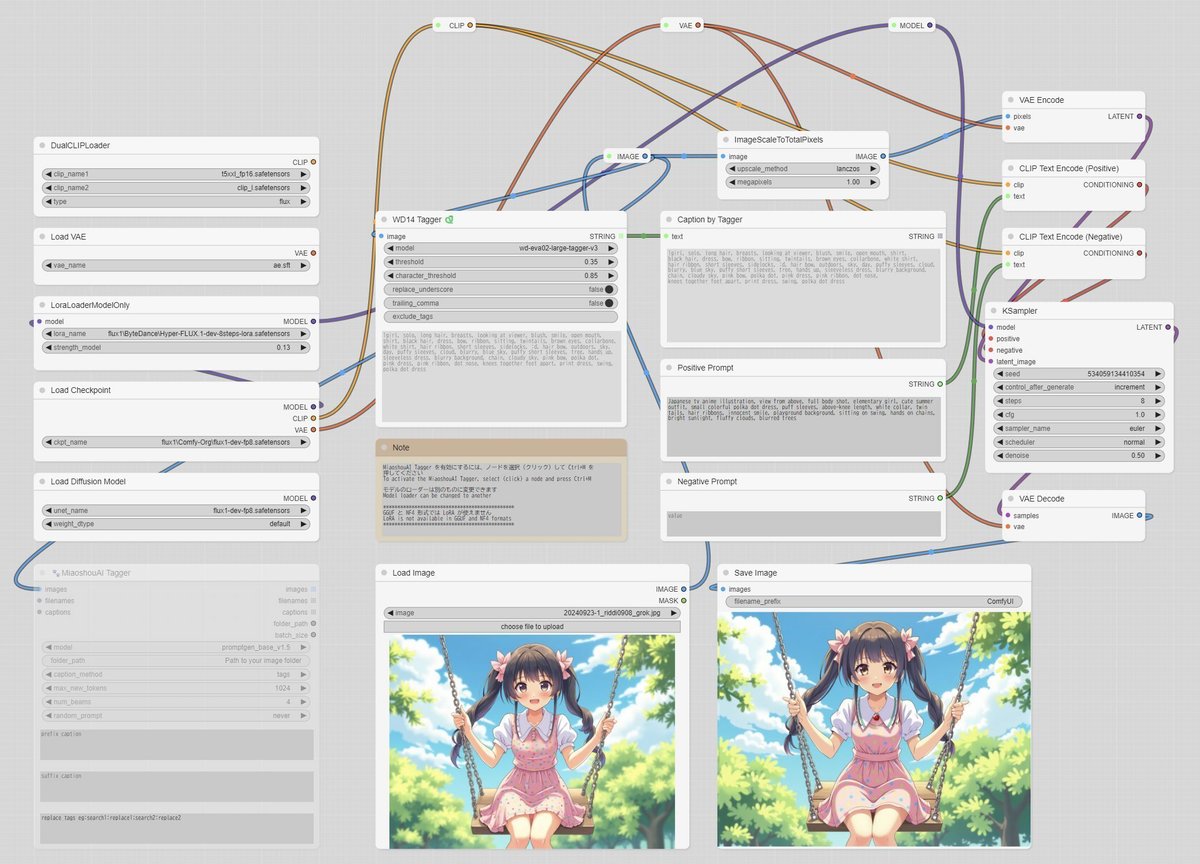

▼ 3-2. 生成画像の解像度を変更する
入力画像をi2iで処理する前に「ImageScaleToTotalPixels」を通し、縦横比を維持したまま一定の画素数にリサイズしています。デフォルトは低めの1MPです。画素数を上げると品質も向上します(ある程度までは)ので、GPUメモリの使用量や実行時間を考慮しながら調整してください。
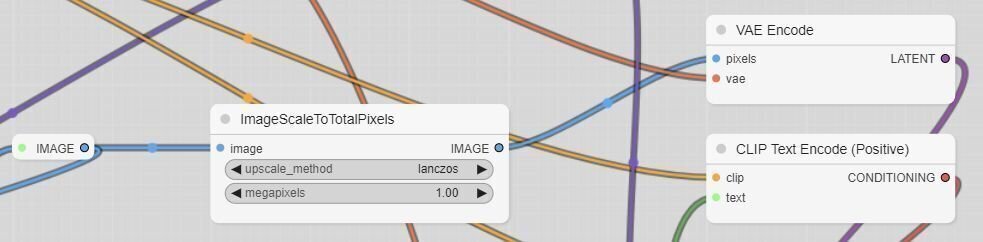
その他、ImageScaleToTotalPixelsの代わりに利用できるノードもあります。そちらに差し替えたり、間に挟んだり、Cropを追加したりするのも良いと思います。ESRGAN等のアップスケールを入れたりKSamplerを多段にしたりすることで、さらに品質を上げられます。
▼ 3-2. モデルの種類を変更する
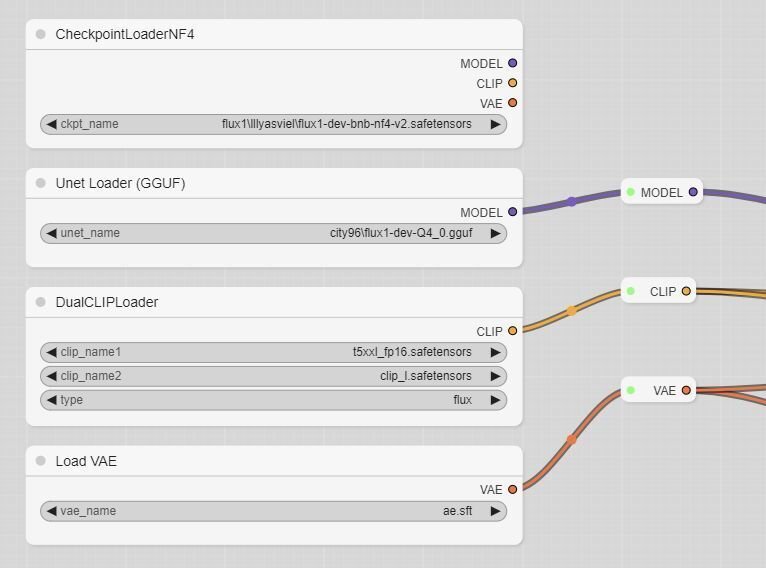
CLIPとVAEが内蔵されていないモデルを利用する場合は、ワークフローで未使用の「Load Diffusion Model」「DualCLIPLoader」「Load VAE」のノードを使用します。「MODEL」「CLIP」「VAE」のRerouteノードを用意してあるので、接続を変更してください。
また、GGUF形式を利用する場合は、下記のようにLoaderのノードを追加して接続を変更してください。NF4についても同様です。なお、これらの形式ではLoRAが利用できないかもしれません。
■ 4. FLUX.1版のi2i(Taggerの出力を適用)
大部分の説明を省略しているので、全体の流れは3.や前の記事を参照してください。
▼ 4-1. 概要(ワークフロー付)
画像ファイルを入力して、画像のキャプションをi2iのプロンプトとして使用するバージョンです。
▼ 4-2. 実行
処理が始まると、キャプションが表示された後でi2iの生成が行われます。


▼ 4-3. 設定
キャプションの前後に任意のタグを加えることができます。denoiseが0.5では変化しづらいので、その場合は値を上げてください(ただし全体も変化しやすくなります)。また、Taggerの「exclude_tags」で不要なタグを取り除くこともできます。
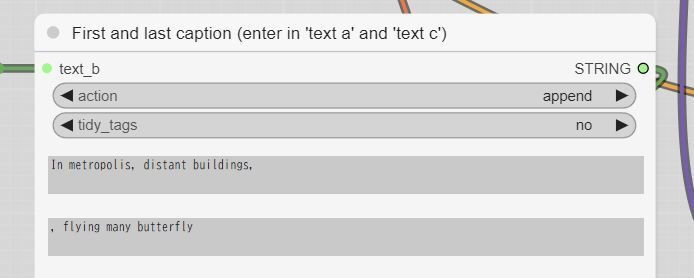

ここで紹介したカスタムノード「String Function🐍」は置換もできるようですが、1つのノードで1ヶ所に限定されているかもしれません。
参考:
https://www.runcomfy.com/comfyui-nodes/ComfyUI-Custom-Scripts/StringFunction-pysssss
■ 5. 様々な画像を試す
▼ 5-1. 既存リソースの再活用(?)
FLUX.1はイラスト向けというわけではないので、試しに色々な画像を入力に用いてみます。ここではMiaoshouAI Taggerを利用し、キャプションをプロンプトに使用します。本項で使うため、ワークフローを微修正しました。
▼ 5-2. 2年前の生成画像を入力する
まずは前の記事と同じ、2年前にStable Diffusionで生成した画像を用いてみます。

denoiseが0.5程度では、そこまで強力な補正は入らないようです。

denoiseを0.75まで上げると、かなり補正が入ります。耳が生えているのはキャプションに「animal ears」が入っているせいなので、除去してやれば消えます。

▼ 5-3. 1年半前の生成画像を入力する
こちらも前の記事と同じです。

元の画像が整っていると、denoiseは0.5でも十分そうです。内容を変更したい場合はdenoiseを上げたり、入力画像に加筆したりする必要があるかもしれません。実はFLUX.1では女の子の胸が出やすく、小さくするには子供に近づくように要素を入れていき、逆の要素を減らす必要があります。

▼ 5-4. DALL-E3の生成画像を入力する
こちらも前の記事と同じで、ChatGPTで生成した画像です。

この場合のi2iは有効かもしれません。好みのFLUX.1モデルがあれば、そちらで試してみると良いでしょう。

▼ 5-5. ややリアルな生成画像を入力する
過去の記事に掲載した画像です。モデルはStable Diffusion 1.5のDefacta 5rdを使用しています。

画像のリファインという意味では、確かにできました(人物にJapaneseを入れた方が良かったかも…)。denoiseを上げて、プロンプトも少し変えて再度生成するのも良いかもしれません。

▼ 5-6. 実写風の生成画像を入力する
こちらは別の記事(ComfyUI上でFLUX.1のモデルを使用して画像の生成を試す)に掲載した画像で、FLUX.1 Devを使用しています。当然ながら、被写体は架空の人物です。

これをi2iにかけると、似て異なる人物になります。さらにdenoiseを上げたりタグを書き換えたりすることで、権利的に問題の無い写真をもとに、構図を含めて内容の似ているバリエーションを生み出すことができそうです。この利用方法については、十分に注意を払ってください。

▼ 5-7. デジタル写真を入力する (1)
旭川の旭山動物園で撮った写真です。

探せば変な箇所があるとは思いますが(男の子の向こうの人の地面の高さが変?)、実写との見分けがつきにくいです。男の子は、Japanese boyにしてやれば直ると思います。

▼ 5-8. デジタル写真を入力する (2)
デンバー(コロラド州)の、16th streetの写真です。

ぱっと見は良さそうですが、よく見ると少しずつ変な箇所があり、区別ができます。

▼ 5-9. デジタル写真を入力する (3)
次は奈良公園です。

ソースによっては、この画像の鹿の毛並みのように不自然な部分が生じます。FLUX.1の得手不得手なのかどうか不明ですが、生き物はこういう事が起こりやすいのかもしれません。左端の異常は、画像の解像度を丸めていないことが原因でしょうか(要改善?)。

▼ 5-10. デジタル写真を入力する (4)
食べ物は思ったようにいきません。多様な見た目の食べ物を、i2iで再現すること自体に無理があるのだと思います。これは沖縄で撮りました。

このように、謎の食べ物ができてしまいます。

試しにプロンプトを空白にしてみても、謎の食べ物になりました。

■ 6. あとがきっぽいもの
▼ 6-1. 感想
FLUX.1でのi2iは、求めるイメージに近づけられない場合があるのではないかと感じました。当然、FLUX.1の出力をi2iする分には問題が少ないと思います。
実写からのi2iは、SDXLとFLUX.1それぞれで試してみてもいいかもしれません。特定のスタイルに寄せるだけであれば、SDXLの方が向いているはずです。
■ 7. その他
私が書いた他の記事は、メニューよりたどってください。
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。
この記事が気に入ったらサポートをしてみませんか?