SDXL 0.9のデモをWindows PCで試す(VRAM 8GB)

Last update 07-08-2023
【07-15-2023 追記】
高性能なUIにて、SDXL 0.9モデルが実験的にサポートされています。下記の記事を参照してください。12GB以上のVRAMが必要かもしれません。
本記事は下記の情報を参考に、少しだけアレンジしています。なお、細かい説明を若干省いていますのでご了承ください。
【リポジトリ】
https://github.com/FurkanGozukara/stable-diffusion-xl-demo
【解説動画】
Stable Diffusion XL (SDXL) Locally On Your PC - 8GB VRAM - Easy Tutorial With Automatic Installer
https://www.youtube.com/watch?v=__7VNmnn5iU
【チュートリアル】
https://github.com/FurkanGozukara/Stable-Diffusion/blob/main/Tutorials/How-To-Use-Stable-Diffusion-SDXL-Locally-And-Also-In-Google-Colab.md
▼ 環境
インストールから実行まで行うために必要な環境(大ざっぱ)です。
Geforce RTX 2xxx以降(VRAM 8GB以上)
Python 3.10、CUDA Toolkit 11.8、Gitがインストール済み
なるべく高速なSSD
なるべく高速なインターネット回線
▼ インストールの手順
事前の準備
https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9 へアクセスして申請を行い、許可されたら https://huggingface.co/settings/tokens よりアクセストークンを取得してください。
環境の構築
作業ディレクトリを「C:\aiwork」としていますので、適宜読み替えてください。コマンド プロンプトを開いて、下記のコマンドを順に実行してください。torchの行とrequirementsの行でそれぞれ、数GB程度のダウンロードが発生します。
cd \aiwork
git clone https://github.com/FurkanGozukara/stable-diffusion-xl-demo
cd stable-diffusion-xl-demo
python -m venv venv
venv\Scripts\activate
(ここで行頭に (venv) が付いていることを確認する)
python.exe -m pip install --upgrade pip
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install xformers==0.0.21.dev557
pip install -r requirements2.txt
deactivateファイル「stable-diffusion-xl-demo\app2.py」をテキストエディタで開いて、Hugging Faceのアクセストークンを入力してください(17行目付近)。
access_token = "your_token"起動用バッチファイルの作成
下記の内容で、バッチファイル「C:\aiwork\sdxldemo.bat」を作成してください。オリジナルとは少しだけ内容が異なります。
@echo off
call stable-diffusion-xl-demo\venv\Scripts\activate.bat
set PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128
set ENABLE_REFINER=false
python stable-diffusion-xl-demo\app2.py
deactivate
pauseなお、VRAMが潤沢にある環境の場合は、下記の設定に差し替えるとREFINERを有効にできます。
set PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:256
set ENABLE_REFINER=true▼ 実行の手順
起動する
先ほどの手順の続きです。コマンド プロンプトを開いて(先ほど使用したものでも構いません)、下記のコマンドにて起動してください。
cd \aiwork
sdxldemo初回は大量のダウンロードが始まるので、しばらくかかります。起動が完了したら下記のメッセージが表示されますので、指示されたURLへアクセスしてください。
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.推論を行う
表現したい文をprompt欄(必要があればnegative promptも)に入力して、「Generate image」をクリックしてください。すぐに思いつかない場合は、下の方にある「Examples」のどれかをクリックしてみてください。
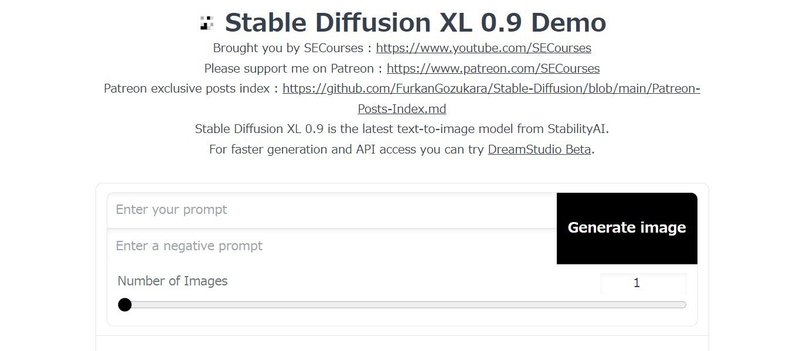
生成される画像のサイズは1024x1024固定で、RTX 3060では1枚あたりの生成に45秒程度かかりました(デフォルトの場合)。画像は「stable-diffusion-xl-demo\outputs」に保存されます。
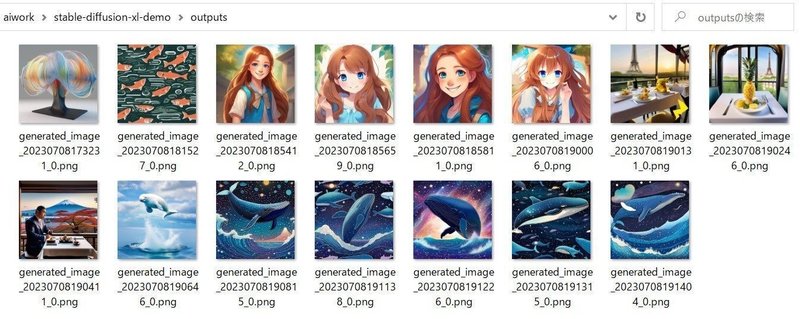
その他の設定は「Advanced settings」にあります。「Images」は1回で生成する枚数で、「CUDA out of memory」のエラーが出ない範囲で上げることができます。「Refiner Strengs」は、「set ENABLE_REFINER=true」の場合のみ設定できます。
終了する
やめる場合は、コマンド プロンプトのウインドウで「Ctrl + C」を押してください。おもむろにウインドウを閉じても構いません。
▼ メモ
アンインストールの手順
もし、「stable-diffusion-xl-demo\outputs」の中身が必要であれば移動してください。その後、実行を終了した状態で「stable-diffusion-xl-demo」のディレクトリを削除してください。
キャッシュについて
Hugging Faceからダウンロードしたデータは、「C:\Users\(ユーザー名)\.cache\huggingface」内にキャッシュされます。たまっていくので、内容を確認しながら適宜削除することをおすすめします。削除してしまっても、元データが消えない限りは必要時に再度ダウンロードされます。
▼ 古いメモ
公式の方法で推論を行う場合の手順です。VRAMが(12GBでも)不足してしまい実行できなかったので、動作の確認はとれていません。
情報
モデル(ダウンロードは申請が必要)
base https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9
refiner https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-0.9Windows用のTritonについて
https://github.com/openai/triton/issues/1057
インストール~実行
コマンド プロンプト上で作業を行ってください。作業ディレクトリ(下記例では「C:\aiwork」)は適宜変更してください。
cd \aiwork
git clone https://github.com/Stability-AI/generative-models
cd generative-models
python -m venv venv
venv\Scripts\activate
python.exe -m pip install --upgrade pip
pip install wheel
CUDA用のTorch(先に入れておかないとCPU版が入る)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Windows用のTriton(標準では存在しない模様)
pip install https://huggingface.co/r4ziel/xformers_pre_built/resolve/main/triton-2.0.0-cp310-cp310-win_amd64.whl
pip install -r requirements_pt2.txt
ここまでの間にcheckpointsのディレクトリを作ってモデルを入れておく
実行後ブラウザが上がるのでしばらく待つ(ポート番号は任意の値)
streamlit run scripts/demo/sampling.py --server.port 8888▼ その他
私が書いた他の記事は、メニューよりたどってください。
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。
この記事が気に入ったらサポートをしてみませんか?