
Kaggle: Dstl Satellite Imagery Feature Detection 2

前回に続いて,Dstl Sattelite Imagery Feature Detection の解説をしていきたいと思います.
第 1 回はタスクの理解(背景・評価指標)をしましたが,今回はデータの確認をしてきます.
以下のような流れでみていきます.
1. Data Description
Dstl コンペのデータ(https://www.kaggle.com/c/dstl-satellite-imagery-feature-detection/data)一覧は以下の通りです.

以下が各ファイルの簡単な説明です.
three_band ファイルには,RGB 形式の一般的な画像が tiff フォーマットで 450 枚含まれています.
sixteen_band ファイル には Panchromatic(1 channel),Multispectral(8 channel)そして SWIR(8 channel)の 3 種類の画像が 450 枚分,計 1350 枚含まれています.これらの channel(帯域)に関しては後ほどもう少し踏み込んだ説明をします.
train_geojson_v3 ファイル には,学習データに該当する 25 枚分の画像データのラベル情報が geojson フォーマットで格納されていますが,本記事では同じ情報の得られる train_wkt_v4.csv を利用しますので,このファイルを取り扱うことはありません.
grid_sizes.csv は,train_wkt_v4.csv から得られる正解ラベルにあたる polygon マスクを,画像データ(pixel フォーマット)に正しく変換するためのメタ情報が含まれています.後ほど,この変換も含めて可視化のパートで確認します.
sample_submission.csv は,お馴染み submission 用の csv ファイルです.このファイルの MultipolygonWKT カラムに,予測ラベルに該当する WKT フォーマット の Multipolygon タイプの geometry 文字列を書いて,提出することになります(下図参照,wikipedia より).

さて,sixteen_band ファイル には,
- Panchromatic
- Multispectral
- SWIR
の 3 種類の band に相当する画像データが含まれているのは上に書いた通りです.よりしっかりした理解のためにも,ここで一旦,衛星から地上の観測に使用される光(電磁波)に関して,簡単な説明をしておきます.
我々が光と聞いて想像しがちな RGB などに代表される光は,「可視光」と呼ばれるもので,下図でいうと「カメラ」のマークのある「可視線」と呼ばれるごく限られた帯域でしかありません.
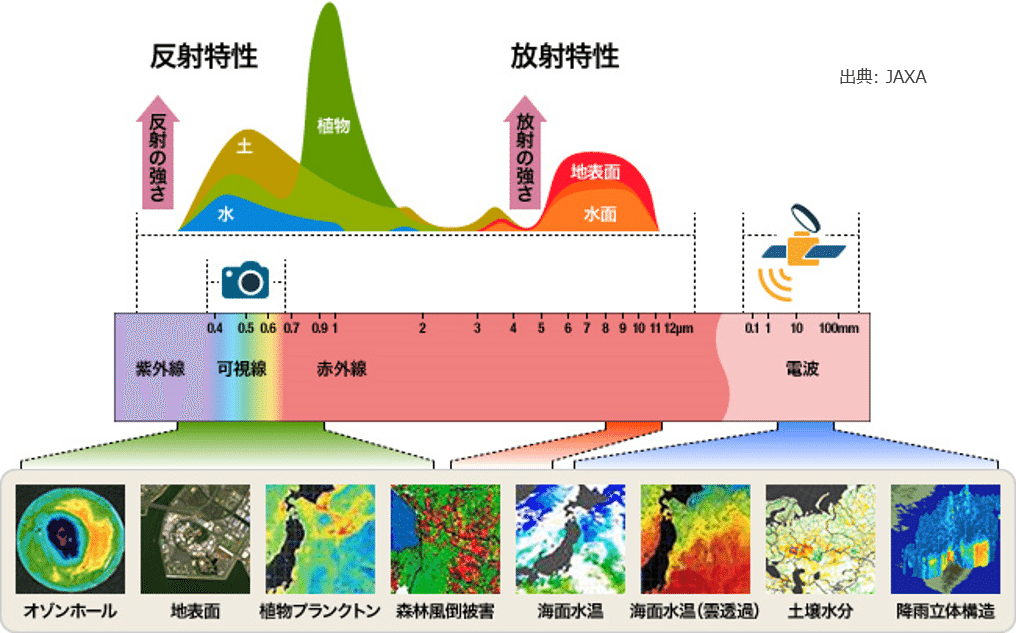
可視光以外にも,極短波長側の紫外線,長波長側の赤外線,そしてもっと長波長側の電波というように,光の波長の長さに応じて色々な帯域が存在します.衛星は紫外~電波の広範囲に渡って,地表から反射された光や水分からの放射光・反射光など,各帯域に応じて色々なものを観測することができます.
Dstl コンペのデータで与えられている Panchromatic は,大雑把に言えば,可視光全域の光(WorldView 3 の場合は 450 - 800 nm)を積分してその強度を白黒で表しているといえます.そのため,データとしては 1 channel となっています.また,この帯域は他の帯域と比較して解像度が高く(WorldView 3 の場合は 0.31 m),解像度では Panchromatic に劣る Multispectral (WorldView 3 の場合は 1.24 m)と重ねることで,より鮮明なカラー画像を作ることができます.こうして作られた画像を「パンシャープン画像(pan sharpened image)」と呼びます.
(参考:https://sorabatake.jp/279/)
Multispectral は,400 - 1040 nm と,紫外から近赤外域に至る光を 8 つの帯域に分けたものです.そのため,データとしては 8 channel になります.
同様に,SWIR(短波長赤外線:Short Wave InfraRed)は,1195 - 2365 nm を 8 つの帯域に分けたもので,Multispectral と同様にデータは 8 つの channel をもちます.
帯域の分け方などの詳細は,WorldView 3 のスペックシートに記載されていますので,そちらを見てみると良いでしょう.
(参考:https://www.restec.or.jp/satellite/worldview-3)
結果的には,Panchromatic (1) + Multispectral (8) + SWIR (8) で 17 channel 分の画像データとなっていますので,これらのデータが入っているファイル名が sixteen_band という名前になっているのは少し違和感がありますね.
(一応,補足しておきますと,Panchromatic の波長帯域は,Multispectral の波長帯域に含まれていますので,16 channel という考え方もできなくはないとは思います)
ここまで確認してきたことをまとめますと,Dstl コンペのデータには色々な波長で観測された画像データが RGB,Panchromatic,Multispectral,SWIR と,合計で 20 channel 分入っています.各帯域の分解能も異なるので,これらをどのようにモデルの入力として使うかが鍵となりそうです.例えば,建物と比較して小さい乗り物などは,分解能が高い RGB や Panchromatic などの方が良いかもしれません.一方で,大きな建物であれば細かなノイズに惑わされにくい SWIR の方が良かったりするかもしれません.
入力情報である画像データにこのような特性があるということを念頭においておきましょう.
それでは,いよいよ実際にデータの中身をみていきます.
2. Class Distribution
最初に,正解ラベルである polygon マスクの Class 分布を確認してみましょう.まず,polygon マスクの情報をもっている train_wkt_v4.csv を下のように読み込んでみます(Dstl コンペの data は実際は zip 形式で提供されています:https://www.kaggle.com/c/dstl-satellite-imagery-feature-detection/data).ここでは,'input/dstl-satellite-imagery-feature-detection' の下に train_wkt_v4.csv.zip が存在するとしています.
import pandas as pd
train = pd.read_csv(
'input/dstl-satellite-imagery-feature-detection/train_wkt_v4.csv.zip'
)
print(train.shape)
# (250, 3)
train.head()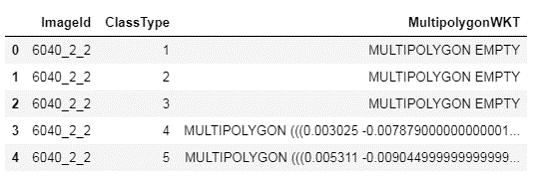
ImageId は各画像に割り当てられたユニークな文字列です.
ClassType は,1 ~ 10 までの値をとり,その内訳は下図のようになっています.Dstl コンペは各画像・各 Class 毎のマスクを予測することになります.

そして,MultipolygonWKT に polygon マスクの情報が,WKT フォーマットの MULTIPOLYGON オブジェクトの形式ではいっています.例えば,「MULTIPOLYGON EMPTY」とあるのは,該当 Class がその画像内に存在しないことを意味しています.
MULTIPOLYGON オブジェクトは geo data を扱うことのできる package で取り扱うのが基本となりますが,python でよく使用されているのは shapely package です.Dstl コンペの kernel などでも,この package が頻繁に使用されています.
それでは,試しに ImageId が 6090_2_0 で,Class が 4(track: 小道)に該当する MULTIPOLYGON を取り扱ってみましょう.
早速,shapely.wkt.loads 関数を利用して以下のように MULTIPOLYGON データを読み込んでみます.
import shapely
polygon = shapely.wkt.loads(train.query(
'ImageId == "6090_2_0" & ClassType == 4'
)['MultipolygonWKT'].values[0])
polygon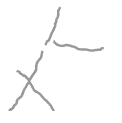
ちゃんと読むことができていれば,polygon の出力図として上図のような,少しサイズが小さく,どこか頼りない描画結果が得られるはずです.とはいえ,この図形が track を表すマスクとなります.
このマスクは 3 つの track で構成されていますが(下側の交差している 2 つの線はまとめて 1 つとカウントされます),それを確かめるには,以下のように単純に len 関数を適用してあげればよいです.
print(f'{len(polygon)} polygons')
# 3 polygons3 つ track がある,と認識できていそうです.
では,先ほど読み込んでおいた train DataFrame の全行に対して MULTIPOLYGON の中に存在する polygon マスクの数をカウントしてみます.
train['n_polygon'] = train['MultipolygonWKT'].apply(
lambda x: len(shapely.wkt.loads(x))
)
train.head(10)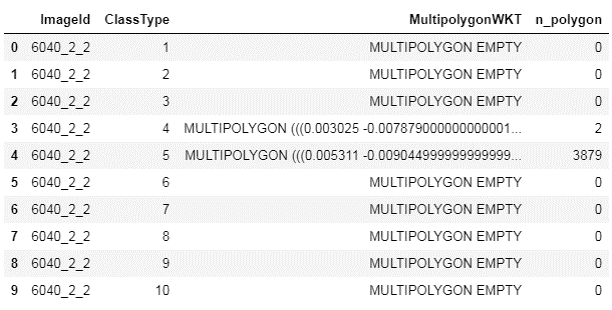
MULTIPOLYGON EMPTY になっているところはちゃんとカウントが 0 になっていて,見た感じではカウントできていそうです.では,全画像に渡って,Class の分布がどのようになっているかを下のコードで確認してみましょう.
import matplotlib.pyplot as plt
plt.style.use('ggplot')
polygon_stat_df = train.pivot(
index='ImageId', columns='ClassType', values='n_polygon'
)
polygon_stat_df.columns = ['1: Buildings',
'2: Misc',
'3: Road',
'4: Track',
'5: Trees',
'6: Crops',
'7: Waterway',
'8: Standing water',
'9: Vehicle Large',
'10: Vehicle Small']
fig, ax = plt.subplots(1, 1, figsize=(10, 6))
polygon_stat_df.sum(axis=0).plot.bar(ax=ax)
for p in ax.patches:
ax.annotate(
str(p.get_height()),
(p.get_x() * 1, p.get_height() * 1.02),
size=8, color='dimgray'
)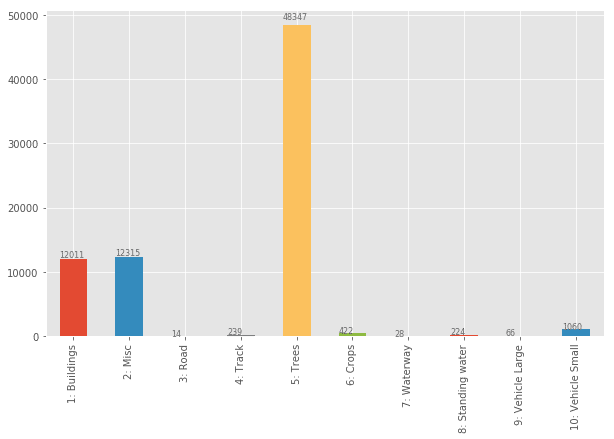
出力として得られるのが上図です.polygon マスクの個数をみた場合,Class 間の分布はかなり極端に偏っていそうなことが分かります.Class 5 の Tree は木の本数分だけカウントされることになりますので,個数でみると非常に多くなるということを示唆していそうです.他には,Class 9 の Vehicle Large が少ないのが気になりますね.しっかりと学習させることができるかどうか不安になるカウント数です.一方で,Class 3 の Road は個数こそ少ないものの 1 つあたりの画像に占める割合が大きい可能性があります.
カウントするだけでは Class 間の不均衡を捉えるには不十分そうですので,それぞれの Class が占める面積もみてみましょう.面積を計算するためには,次のコードのように shapely package の Geometric Objects クラスの area メソッド を利用します.
train['area_polygon'] = train['MultipolygonWKT'].apply(
lambda x: shapely.wkt.loads(x).area * 1e6
)
polygon_stat_df = train.pivot(
index='ImageId', columns='ClassType', values='area_polygon'
)
polygon_stat_df.columns = ['1: Buildings',
'2: Misc',
'3: Road',
'4: Track',
'5: Trees',
'6: Crops',
'7: Waterway',
'8: Standing water',
'9: Vehicle Large',
'10: Vehicle Small']
polygon_stat_df
fig, ax = plt.subplots(1, 1, figsize=(10, 6))
polygon_stat_df.sum(axis=0).plot.bar(ax=ax)
for p in ax.patches:
ax.annotate(
str(np.round(p.get_height(), 1)),
(p.get_x() * 1, p.get_height() * 1.02),
size=8, color='dimgray'
)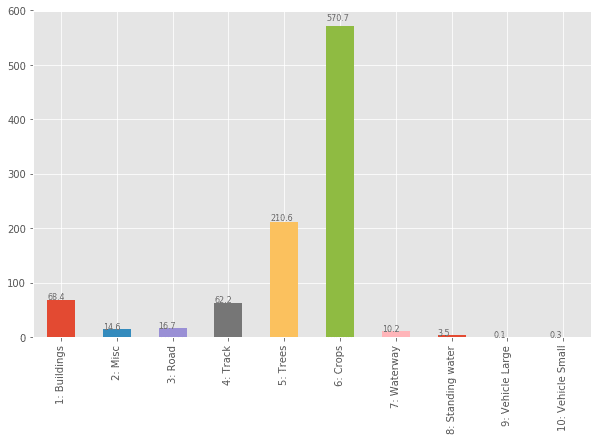
得られた上図をみると,先ほどの polygon マスクの個数をカウントした結果と比較して,大きく見え方が変わっていることが確認できます.個数が多くなかった Class 6 の Crops は,画像に占める面積は大きいようです.つまり,polygon 1 つあたりの面積が大きいと考えられます.一方で,Class 5 の Trees は木 1 つあたりの面積はそこまで大きくないでしょうから,面積でみるとその比率は落ちています.しかし,Class 9 の Vehicle Large や Class 10 の Vehicle Small は面積でみても比率が小さく,学習が難しいであろうことがこの時点で予想される結果となりました.
実際に,Class 9 と Class 10 のスコア(Jaccard 係数)は,private LB で top 3 に入っているモデルでも,あまり芳しくないことは下リンクの第 1 回の記事で確認することができます.
ここまでの分析で,どの Class の学習が大変そうか,および shapely を使用した簡単な geo data の取り扱いの確認ができました.
では,RGB 画像と polygon マスクを重ねて描画させてみましょう.
3. Visualization of RGB Band with Polygon Masks
WKTフォーマットの MULTIPOLYGON を matplotlib 等で扱える pixel 形式の np.ndarray フォーマットにするためには,いくつかのプロセスが必要です.
具体的には,以下リンクの Kaggle の公式 tutorial にもあるような形で処理をしていくことになります.1 つ 1 つ確認をしていきましょう.
ImageId が 6090_2_0 で,Class が 4 の MULTIPOLYGON を引き続き例として使用します.
3-1.
まず最初に tiff フォーマットの RGB 画像を tifffile package で読み込んでおきましょう.読み込む 6090_2_0.tif ファイルは,'input/dstl-images' の下に存在するとしています.ここで 1 つの注意点があります.tifffile packge によって読み込んだ tiff フォーマットの画像は,(Channel, Height, Width) の順になってしまっていますので,忘れずに深層学習に優しい (Height, Width, Channel) の順に並べ替えておきましょう.
また,WorldView 3 の RGB (Multispectral)画像のダイナミックレンジは 11 bit( WorldView 3 spec sheet )ですので,各ピクセルの強度を 2^11 で割ることで規格化します.
import tifffile as tiff
IM_ID = '6090_2_0'
im_rgb = tiff.imread(
f'../input/dstl-images/{IM_ID}.tif'
).transpose([1, 2, 0])
print(f'RGB tiff image shape = {im_rgb.shape}')
# RGB tiff image shape = (3349, 3393, 3)
print(f'max = {im_rgb.max()}\nmin = {im_rgb.min()}')
# max = 856
# min = 91
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
ax.imshow(im_rgb / 2 ** 11)
ax.grid(None);
無事,上図のように RGB 画像を表示させることができましたが,このままですとコントラストが悪く,何がどのようになっているかが分かりにくい状態です.次のステップでこの画像のレベル補正をして,より地上構造物の形がみやすいように変換してみます.
3-2.
レベル補正を行うための helper function を下のように作成します.
行っていることは単純で,各 channel 強度の 1%・99 % 点を下限・上限として規格化しているだけです(見易さのために code の行数が増える書き方をしています).
# Helper function to scale an image
def scale_per(arr):
min_ch = np.percentile(arr, 1, axis=(0, 1))
range_ch = np.percentile(arr, 99, axis=(0, 1)) - min_ch
arr = arr - min_ch[np.newaxis, np.newaxis, :]
arr = arr / range_ch[np.newaxis, np.newaxis, :]
return arr.clip(0, 1)では,さっそくレベル補正をしたものとそうでないものを比較してみましょう.
fig, ax = plt.subplots(1, 2, figsize=(24, 12))
ax[0].imshow(im_rgb / 2 ** 11)
ax[0].grid(None)
ax[1].imshow(scale_per(im_rgb))
ax[1].grid(None);
上左図がレベル補正無しのものを,上右図がレベル補正後のものを表しています.画像の各 channel 強度のヒストグラムなどをあまり深くみずに強引に補正した感はありますので,色がピンクがかかった少し変な画像になってしまっています.ですが,左図のものと比較して地上の構造物が分かりやすくなっています.ところどころに散在している点のようなものはおそらくは木なのでしょう.では,次にこのレベル補正後の図にマスクを重ねてみます.
3-3.
train_wkt_v4.csv ファイルから得られた polygon マスクを RGB 画像に重ねるためには,Kaggle 公式の tutorial にある通り,適切に polygon マスクを scaling をして pixel 形式の RGB 画像にしっかりと重なるようにしなければいけません.
そのために,まずは polygon マスクを scaling する以下の helper function(get_scalers 関数)を作成します.(どうしてこのような仕様になっているかは分かりませんが,とりあえず公式の tutorial 通りの処理にしています)
# helper function to project polygons to pixel coordinates
# reference:
# https://www.kaggle.com/c/dstl-satellite-imagery-feature-detection/overview/data-processing-tutorial
def get_scalers(image, x_max, y_min):
im_size = image.shape[:2]
h, w = im_size
w_ = w * (w / (w + 1))
h_ = h * (h / (h + 1))
return w_ / x_max, h_ / y_minそして,複数存在する可能性のある polygon マスクを 1 つの 2D の numpy.ndarray 上に展開させるための mask_for_polygons 関数を用意します.マスクのあるところは 1 に,存在しないところは 0 になるように opencv2 の fillPoly 関数 を利用しています.一切 polygon マスクがなかった場合は,全要素が 0 の 2D の numpy.ndarray を返すだけとなります.また,この関数の引数である polygons は適切に scaling を受けた後のものであることに注意してください.
import cv2
# helper function to make a mask from polygons
def mask_for_polygons(polygons, image):
im_size = image.shape[:2]
img_mask = np.zeros(im_size, np.uint8)
if not polygons:
return img_mask
int_coords = lambda x: np.array(x).round().astype(np.int32)
exteriors = [int_coords(poly.exterior.coords) for poly in polygons]
interiors = [
int_coords(pi.coords) for poly in polygons for pi in poly.interiors
]
cv2.fillPoly(img_mask, exteriors, 1)
cv2.fillPoly(img_mask, interiors, 0)
return img_maskそれでは,polygon マスクと RGB 画像を重ねてみましょう.下のコードの各パートを簡単に説明します.
# 1 と # 2 にて,polygon マスクデータと RGB 画像データをもう一度読み込ませています.
# 3 では,polygon マスクの scaling に必要な情報である x_max と y_min を grid_sizes.csv から読み込んでいます.
# 4 では,先ほど作成した get_scalers 関数を使い,polygon マスクを適切に scaling するための係数を計算しています.
# 5 では,shapely の affinity.scale 関数 を使い,先ほど求めた scaling 用の係数(x_scaler および y_scaler)を使い,polygon マスクを原点を基点として scaling しています.
# 6 では,mask_for_polygons 関数を利用し,2D numpy.ndarray 上に複数の polygon マスクを展開させています.
IM_ID = '6090_2_0'
POLY_TYPE = '4'
# 1. Read polygon mask
train = pd.read_csv(
'input/dstl-satellite-imagery-feature-detection/train_wkt_v4.csv.zip'
)
polygon = shapely.wkt.loads(train.query(
'ImageId == @IM_ID & ClassType == @POLY_TYPE'
)['MultipolygonWKT'].values[0])
# 2. Read RGB image with tiff
im_rgb = tiff.imread(
f'input/dstl-images/{IM_ID}.tif'
).transpose([1, 2, 0])
print(f'RGB tiff image shape = {im_rgb.shape}')
# 3. Load grid size
grid_sizes = pd.read_csv(
'input/dstl-satellite-imagery-feature-detection/grid_sizes.csv.zip'
)
x_max, y_min = grid_sizes.query(
'ImageId == @IM_ID'
).values[0][1:].tolist()
# 4. Project to pixel coordinates
x_scaler, y_scaler = get_scalers(im_rgb, x_max, y_min)
# 5. Affine transformation
# https://shapely.readthedocs.io/en/latest/manual.html?highlight=scale#shapely.affinity.scale
polygon_scaled = shapely.affinity.scale(
polygon, xfact=x_scaler, yfact=y_scaler, origin=(0, 0, 0)
)
# 6. Get masks
mask = mask_for_polygons(polygon_scaled, im_rgb)
# 7. Draw
fig, ax = plt.subplots(1, 2, figsize=(24, 12))
ax[0].imshow(scale_per(im_rgb))
ax[1].imshow(scale_per(im_rgb), alpha=0.7)
ax[1].imshow(np.tile(mask[..., np.newaxis], (1, 1, 3)) * scale_per(im_rgb),
alpha=0.7)
ax[0].grid(alpha=0.2); ax[1].grid(alpha=0.2)
fig.tight_layout();# 7 で描画させると,下図が得られます.
polygon マスク外のピクセル部分は薄黒く塗りつぶす形にしてありますので,Class 4 である track に該当する部分が際立ってみえる形となりました.それにしても,左下図では track に該当する部分がどこにあるかあまり分かりませんね.
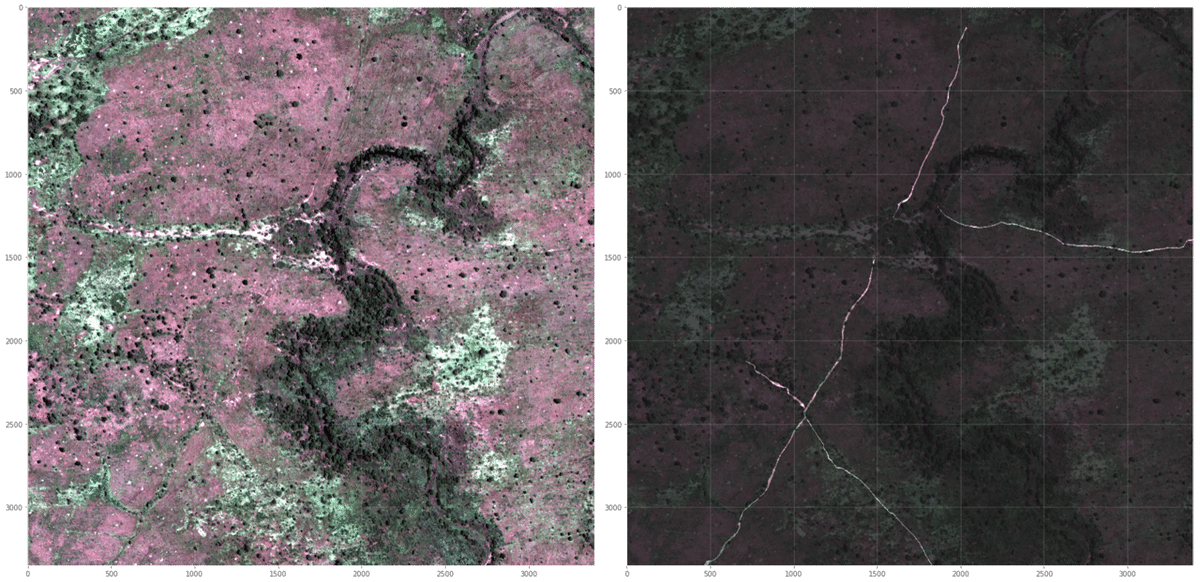
これで RGB 画像に対して polygon マスクを重ねて表示させることができるようになりました.最後に,全 Class の polygon マスクを確認して今回は終わりにしたいと思います.
4. Image Library
1: Buildings


2: Structures

3: Road

4: Track

5: Trees

6: Crops

7: Waterway

8: Standing water

9: Vehicle Large

10: Vehicle Small

ところどころ,「うーん・・・そうなの?」と少しマスクの annotation の仕方に疑問をもってしまうようなものもありますが,とりあえずはデータの通りにマスク情報をピクセル上に展開することができました.
さて・・・次回以降は,念願のモデリングへと話題を進めたいと思います.
気長にお待ちいただけると幸いです.
(余談)
下リンクの Kaggle admin の discussion によると,この annotation は相当大変だったとのことです.ですので,私のような素人でも annotation 精度などに何らかの疑問をもつことがあるのも仕方のないことなのかもしれません.ちなみに,annotation がしっかりとされた画像は実は 57 枚しかなく,450 枚ある画像のうちの残り 390 枚程度は,全部 dummy だった(精度が評価されないので,順位に一切関係ない)とのことです.なんてこった・・・.
この記事が気に入ったらサポートをしてみませんか?