高校数学をプログラミングで解く(数学I編)「3-1 データの整理、データの代表値」

はじめに
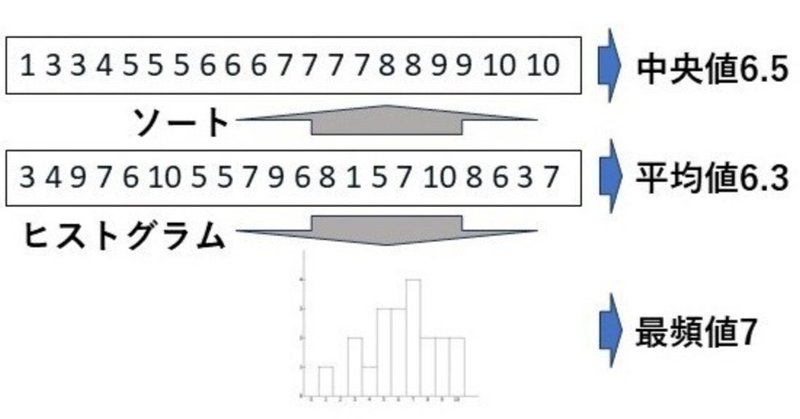
今回は、数学Iで学ぶ「データの整理、データの代表値」について、データの代表値として平均値、中央値、最頻値を求めるプログラムを作成します。
データの代表値
まず、データの代表値として、平均値、中央値、最頻値について解説しておきます。
平均値
変量$${x}$$についてのデータの値が、$${n}$$個の値$${x_0,x_1, \cdots, x_{n-1}}$$であるとき、それらの総和を$${n}$$で割ったもの。
$$
\bar{x} = \frac{1}{n} ( x_0 + x_1 + \cdots + x_{n-1} )
$$
中央値(メジアン)
データを値の大きさの順に並べたとき、中央の位置にくる値。データの大きさが偶数のときは、中央に2つの値が並ぶが、その場合は、その2つの値の平均値とする。
最頻値(モード)
データにおいて、最も個数の多い値。
今回は、データに対してこれらの値を求めるプログラムを順に作成していきます。
利用するデータの準備
以下で作成する各種プログラムで利用するデータは以下の20個の数を利用します。なお、これらの数は「小テストの点数」としておきます。
$$
3 \ 4 \ 9 \ 7 \ 6 \ 10 \ 5 \ 5 \ 7 \ 9 \ 6 \ 8 \ 1 \ 5 \ 7 \ 10 \ 8 \ 6 \ 3 \ 7
$$
なお、プログラムではfloat型の配列として扱います。
// データ
int data_num = 20; // データ数
float[] data = {3,4,9,7,6,10,5,5,7,9,6,8,1,5,7,10,8,6,3,7}; // データ平均値を求める
まず、平均値を求めるプログラムを作成します。アルゴリズムは平均値の定義通り、データの総和を計算してデータ数で割るだけですので、簡単です。
// データの平均値を計算する
void setup(){
// データ
int data_num = 20; // データ数
float[] data = {3,4,9,7,6,10,5,5,7,9,6,8,1,5,7,10,8,6,3,7}; // データ
// 平均値
float mean = calcmeanvalue(data_num, data);
println(mean);
}
// 平均値を計算する関数
float calcmeanvalue(
int data_num, // データ数
float[] data // データの配列
){
float sum = 0.0;
for(int i=0; i<data_num; i++){
sum += data[i];
}
return sum / data_num;
}ソースコード1 データの平均値を求めるプログラム
なお、平均値を求める部分は関数化(関数名「calcmeanvalue」)しており、引数にデータ数「data_num(int型)」とデータ「data(float型の配列)」を渡すと、平均値を計算して返す関数となっています。
このソースコード1を、Processingの開発環境ウィンドウを開いて(スケッチ名を「calcMeanValue」としています)、テキストエディタ部分に書いて実行すると、図1のようにデータの平均値「6.3」がコンソールに出力されます。

中央値を求める
次に、中央値を求めるプログラムを作成します。
データをソートする関数の準備
中央値の定義では「データを値の大きさの順に並べたとき、中央の位置にくる値」となっています。そのため、中央値を求めるためにはデータを値の大きさの順に並べ替える必要があります。このようなデータの並べ替えを「データをソートする」と言います。
このデータをソートする関数を準備します。特に、今回はデータを昇順(小さい方から大きい方へ並べる)にソートします。また、ソートの方法はいくつかありますが、今回は最も単純なソート方法であるバブルソートを利用します。
バブルソート(昇順)
① $${n}$$個のデータの値をそれぞれ配列の要素$${x_0, x_1, \cdots, x_{n-1}}$$に順に入れておきます。
② $${x_0}$$と$${x_1}$$の値を比較して、$${x_0 > x_1}$$であれば$${x_0}$$と$${x_1}$$の値を入れ替え、そうでなければそのままにしておきます。この結果、$${x_0 \leq x_1}$$となります。
③ 次に、$${x_1}$$と$${x_2}$$の値を比較して、$${x_1 > x_2}$$であれば$${x_1}$$と$${x_2}$$の値を入れ替え、そうでなければそのままにしておきます。この結果、$${x_1 \leq x_2}$$となります。
④ ②や③の処理を$${x_2}$$と$${x_3}$$の値の比較、$${x_3}$$と$${x_4}$$の値の比較、と順に繰り返していき、$${x_{n-2}}$$と$${x_{n-1}}$$の値の比較まで行うと、最終的に$${x_{n-1}}$$にデータの中で最も大きな値が入ることになります。
⑤ ②から④までの処理を$${n}$$回繰り返します。ただし、最初の処理を$${0}$$回目としたときの$${i}$$回目の処理では、④は$${x_{n-2-i}}$$と$${x_{n-1-i}}$$まで行い、その結果、$${x_{n-1-i}}$$に$${x_0, x_1, \cdots, x_{n-1-i}}$$のデータの中で最も大きな値が入ることになります。
⑥ 以上の処理により、$${n}$$個のデータの値は配列$${x_0, x_1, \cdots, x_{n-1}}$$に値が小さい順(昇順)に入ることになります。
では、バブルソートを用いてデータをソートする関数を作成します。
// バブルソート(昇順)
float[] bubblesort(
int data_num, // データ数
float[] data // データの配列
){
float[] bs = new float[data_num];
for(int i=0; i<data_num; i++){
bs[i] = data[i];
}
for(int i=0; i<data_num; i++){
for(int j=1; j<data_num-i; j++){
if(bs[j-1] > bs[j]){
float temp = bs[j];
bs[j] = bs[j-1];
bs[j-1] = temp;
}
}
}
return bs;
}ソースコード2 バブルソートを行う関数
なお、このbubblesort関数の引数は、データ数「data_num(int型)」とデータ「data(float型の配列)」としており、その返り値はデータを昇順にソートした配列(float型の配列)としています。
データをソートする関数のテストプログラム
ここでいったん、データをソートする関数をテストするためのプログラムを作成します。
// データをソートする(テスト)
void setup(){
// データ
int data_num = 20; // データ数
float[] data = {3,4,9,7,6,10,5,5,7,9,6,8,1,5,7,10,8,6,3,7}; // データ
// dataを昇順にソートする
float[] bs_data = bubblesort(data_num, data);
println(bs_data);
}
// バブルソート(昇順)
float[] bubblesort(
int data_num, // データ数
float[] data // データの配列
){
float[] bs = new float[data_num];
for(int i=0; i<data_num; i++){
bs[i] = data[i];
}
for(int i=0; i<data_num; i++){
for(int j=1; j<data_num-i; j++){
if(bs[j-1] > bs[j]){
float temp = bs[j];
bs[j] = bs[j-1];
bs[j-1] = temp;
}
}
}
return bs;
}ソースコード3 ソートする関数をテストするプログラム
このソースコード3を、Processingの開発環境ウィンドウを開いて(スケッチ名を「testSortFunction」としています)、テキストエディタ部分に書いて実行すると、図2のようにデータが昇順に並べ替えられてコンソールに出力されていることがわかります。

中央値を求めるプログラム
それでは、いよいよ中央値を求めるプログラムを作成します。アルゴリズムは、データをソートする関数は用意できたので、あとは中央値の定義通りに作成していきます。
// データの中央値を算出する
void setup(){
// データ
int data_num = 20; // データ数
float[] data = {3,4,9,7,6,10,5,5,7,9,6,8,1,5,7,10,8,6,3,7}; // データ
// 中央値
float median = calcmedian(data_num, data);
println(median);
}
// バブルソート(昇順)
float[] bubblesort(
int data_num, // データ数
float[] data // データの配列
){
float[] bs = new float[data_num];
for(int i=0; i<data_num; i++){
bs[i] = data[i];
}
for(int i=0; i<data_num; i++){
for(int j=1; j<data_num-i; j++){
if(bs[j-1] > bs[j]){
float temp = bs[j];
bs[j] = bs[j-1];
bs[j-1] = temp;
}
}
}
return bs;
}
// 中央値を求める関数
float calcmedian(
int data_num, // データ数
float[] data // データの配列
){
// データを昇順にソートする
float[] bs = new float[data_num];
bs = bubblesort(data_num, data);
float median = 0.0;
if( data_num % 2 == 0 ){ // データ数が偶数のとき
median = ( bs[data_num / 2 - 1] + bs[data_num / 2] ) / 2.0;
} else { // データ数が奇数のとき
median = bs[data_num / 2];
}
return median;
}ソースコード4 データの中央値を求めるプログラム
なお、中央値を求める部分は関数化(関数名「calcmedian」)しており、引数にデータ数「data_num(int型)」とデータ「data(float型の配列)」を渡すと、データをソートした後中央値を算出して返す関数となっています。
このソースコード4を、Processingの開発環境ウィンドウを開いて(スケッチ名を「calcMedian」としています)、テキストエディタ部分に書いて実行すると、図3のようにデータの中央値「6.5」がコンソールに出力されます。

最頻値を求める
最後に、最頻値を求めるプログラムを作成します。
最頻値を求めるプログラム
最頻値の定義では「データにおいて、最も個数の多い値」となっています。そのため、最頻値を求めるためにはデータを階級ごとに分けてそれぞれの階級の個数を求める必要があります。たとえば、今回利用しているデータを「小テストの点数」と考えると、階級としてテストの点数$${0}$$から$${10}$$までの11階級あることになり、階級の個数はその点数をとった人数ということになります。
アルゴリズムはデータの階級ごとの個数を求めて、そのうち最も個数が多い階級(ここでは点数)を算出すればいいわけです。
// データの最頻値を算出する
void setup(){
// データ
int data_num = 20; // データ数
float[] data = {3,4,9,7,6,10,5,5,7,9,6,8,1,5,7,10,8,6,3,7}; // データ
// 階級ごとの個数の計算
int data_kind_num = 11; // データの階級は0から10までの11種類
int[] hist = new int[data_kind_num]; // 階級ごとの個数を数えるための配列
for(int k=0; k<data_kind_num; k++){
hist[k] = 0;
}
for(int i=0; i<data_num; i++){
hist[(int)data[i]]++; // 階級の個数をカウント
}
// 最頻値を求める
int mode = 0;
int max_value = 0;
for(int k=0; k<data_kind_num; k++){
if( max_value < hist[k]){
max_value = hist[k];
mode = k;
}
}
println(mode);
}ソースコード5 データの最頻値を求めるプログラム
このソースコード5を、Processingの開発環境ウィンドウを開いて(スケッチ名を「calcMode」としています)、テキストエディタ部分に書いて実行すると、図4のようにデータの最頻値「7」がコンソールに出力されていることがわかります。

おまけ:ヒストグラムを描く
最頻値を求めるプログラムを作成する際に、データの階級ごとの個数を求めましたので、その結果を利用してヒストグラムを描いてみます。
ヒストグラムとは、横軸に階級、縦軸に度数をとった統計グラフのことです。今回の場合は、横軸が小テストの点数、縦軸がその点数を取った人数を表します。
// データのヒストグラムを描く
void setup(){
size(700, 700); // キャンバスの大きさを指定する
background(255,255,255); // 背景を白色にする
noLoop(); // 繰り返し処理をしない
// データ
int data_num = 20; // データ数
float[] data = {3,4,9,7,6,10,5,5,7,9,6,8,1,5,7,10,8,6,3,7}; // データ
// 階級ごとの個数の計算
int data_kind_num = 11; // データの階級は0から10までの11種類
int[] hist = new int[data_kind_num]; // 階級ごとの個数を数えるための配列
for(int k=0; k<data_kind_num; k++){
hist[k] = 0;
}
for(int i=0; i<data_num; i++){
hist[(int)data[i]]++; // 階級の個数をカウント
}
// 最頻値を求める
int mode = 0;
int max_value = 0;
for(int k=0; k<data_kind_num; k++){
if( max_value < hist[k]){
max_value = hist[k];
mode = k;
}
}
fill(0,0,0); // 文字の色を黒色にする
textSize(20); // 文字のサイズを調整
// 座標軸を準備
line(width/14.0, height*6.0/7.0, width/14.0+width*12.0/14.0, height*6.0/7.0); // 横軸
line(width/14.0, height*6.0/7.0-height*5.0/7.0, width/14.0, height*6.0/7.0); // 縦軸
// 横軸に階級を描く
textAlign(CENTER, TOP);
for(int k=0; k<data_kind_num; k++){
text(k, width*(k+1.0+0.5)/14.0, height*6.0/7.0+5.0);
}
// 縦軸に目盛り
textAlign(RIGHT, CENTER);
for(int i=max_value; i>=0; i--){
line(width/14.0-5.0, height*6.0/7.0-height*i/7.0, width/14.0+5.0, height*6.0/7.0-height*i/7.0);
text(i, width/14.0-5.0, height*6.0/7.0-height*i/7.0);
}
translate(width/14.0, height*6.0/7.0); // 座標の中心を移動する
scale(1,-1); // y軸正の向きを下向きから上向きに反転する
noFill(); // 図形の塗りつぶしなし
// ヒストグラムを描く
for(int k=0; k<data_kind_num; k++){
rect(width*k/14.0, 0.0, width/14.0, height/7.0 * hist[k]);
}
}ソースコード6 ヒストグラムを描くプログラム
このソースコード6を、Processingの開発環境ウィンドウを開いて(スケッチ名を「drawHistgram」としています)、テキストエディタ部分に書いて実行すると、図5のように、実行ウィンドウのキャンバスに今回のデータのヒストグラムが描かれます。

なお、今回のヒストグラムを描くプログラム(ソースコード6)は、今回利用したデータに特化した形で作成しています。余力のある人は、より汎用的なプログラムに書き換えてみてください。
まとめ
今回は、数学Iで学ぶ「データの整理、データの代表値」について、データの代表値として平均値、中央値、最頻値を求めるプログラムを作成しました。
それぞれの定義は簡単ですが、実際にそれを計算するプログラムを作成するためには処理に一手間必要でした。
中央値では、その値を求めるためにデータを小さい順に並べなおす必要があります。データを並べなおすことをソートと呼び、そのソートを行う関数を準備したうえで中央値を求める関数を作成しました。データをソートすることはデータを整理する上でよく利用されますので、ここで覚えておくとよいでしょう。
また、最頻値では、各階級の個数を求めてそのうち個数が多い階級が最頻値になりました。そのため、各階級の個数を求めるためのプログラムを作成しました。また、各階級の個数の結果を利用してヒストグラムも描いてみました。正直、プログラミング言語「Processing」は、ヒストグラムを描くにはあまり向いていないですが、工夫すれば描くことはできますので、勉強だと思ってチャレンジしてみてください。
参考文献
改訂版 教科書傍用 スタンダード 数学I(数研出版、ISBN9784410209178)
この記事が気に入ったらサポートをしてみませんか?