
Turingのマルチモーダル学習ライブラリ「Heron」, Falcon 180B LLM, etc - Generative AI 情報共有会 #7

今週、9月12日(火)にZENKIGEN社内で実施の「Generative AI最新情報共有会」でピックアップした生成AI関連の情報を共有します。
この連載の背景や方向性に関しては 第一回の記事 をご覧ください。
Turing、日英対応のマルチモーダル学習ライブラリ「Heron」と最大70Bパラメータの大規模モデル群公開
完全自動運転車両の開発・販売に取り組むTuring株式会社、日本語を含む複数言語対応の大規模マルチモーダル学習ライブラリ「Heron(ヘロン)」と、それにより学習した最大70Bパラメータのモデル群を公開。
公開されたマルチモーダルモデルの特徴
学習に対話を含むデータセットを用いることで、自然かつ適切な対話が可能。
これまでのマルチモーダルモデルでは単純な回答しかできなかった複合的な画像-言語タスクにおいて、より詳細で自然な文章生成が可能となり、前の質問を含む文脈を理解して応答することが可能。

モデルに画像を入力して試すことができるデモサイト。

これまでいくつかの日本語マルチモーダルモデルで試してきたが、初めて良い線(動物を認識できているっぽい)出力が得られた…!
学習用ライブラリ「Heron」
学習する大規模言語モデルを自由に変換可能であり、既存の言語モデルの性能を活かしつつ、今後開発・公開される新たな大規模言語モデルに対しても容易に対応できる柔軟性を有する。
本格的にマルチモーダルモデルを学習するために系統的に学習できるように工夫されている。
ソースコード部分については研究・商用利用が可能なApache License 2.0。
大規模な日本語の画像/テキスト情報のデータセット
大規模な日本語の画像/テキスト情報のデータセット(注釈テキストやQ&Aからなる約15万枚の画像/テキストの英文データセット LLaVA Visual Instruct 150K をDeepL翻訳したデータセット)を作成・公開。
このような対話形式のマルチモーダル学習向けの大規模な日本語データセットの公開は、世界初。
ライセンスは元のデータセットと同様、CC BY-NC-4.0(商用利用不可)。
開発者の方のX(Twitter)上でのQA
Q:
完全自動運転の場合、人間とのコミュニケーションが不要なはずで、日本語ではなく英語で十分だと想像するのですが、日本語対応した理由は何でしょうか?
A:
日本で走らせるために、日本の標識とかを認識する必要があるかなと思って日本語にも取り組んでいます!最終的にLlama2みたいな「ニホンゴチョットワカル」の最強英語モデルで十分な可能性、なんなら論理思考能力的にはもっと良い可能性もあるかなと思っています!
Q:
DeepLで翻訳したものだと日本特有の文化や交通ルールのようなものをなかなか学習しづらいと思います。そこが原因でハルシネーションって結構起きると思うのですが、そこは今後どう工夫していきたいですか?
A:
めちゃくちゃ重要な点で現状のデータセットの課題だと思っています!この点に関しては人間の介入が避けられないと今は思っています...。V&LモデルでもHFRLを使うことで一気にブレイクスルーが起きる可能性もあると思っています!
Q:
自動運転用としてLLMを使うのはスピード面ではどうなのでしょうか? 推論速度をカバーする工夫などもありますか?
A:
エッジデバイスの計算能力の向上と高速Transformerの研究の両方の進歩に期待している部分はあります!
モデル開発としては、推論時は言葉をしゃべるのではなくベクトルでやり取りしたりと設計上で工夫できる点も多いと思ってます!
さらにTuringではNavigator/Driverモデルというアーキテクチャもあり得ると考えていています。LLMのような少し時間がかかるけどコンテキストを理解できる知能を持ったNavigatorモデルは1Hzとかの単位で動いて、運転に最低限必要な能力を持ったDriverモデルは20~30Hzで動かす、そういった仕組みも検討していこうと思っています!
参考情報: https://prtimes.jp/main/html/rd/p/000000028.000098132.html
アラブ首長国連邦のTII、Falcon 180B LLM公開
アラブ首長国連邦のTII(Technology Innovation Institute)から、パラメータ数がGPT-3(175B)より大きい180Bモデルが公開。現在公開されているモデルとしては最大。
パフォーマンス
MMLU(Multi-task Language Understanding、LLMのマルチタスク性能を測定するためのベンチマーク)では、GoogleのPaLM2-Large(非公開モデル)に迫る性能。
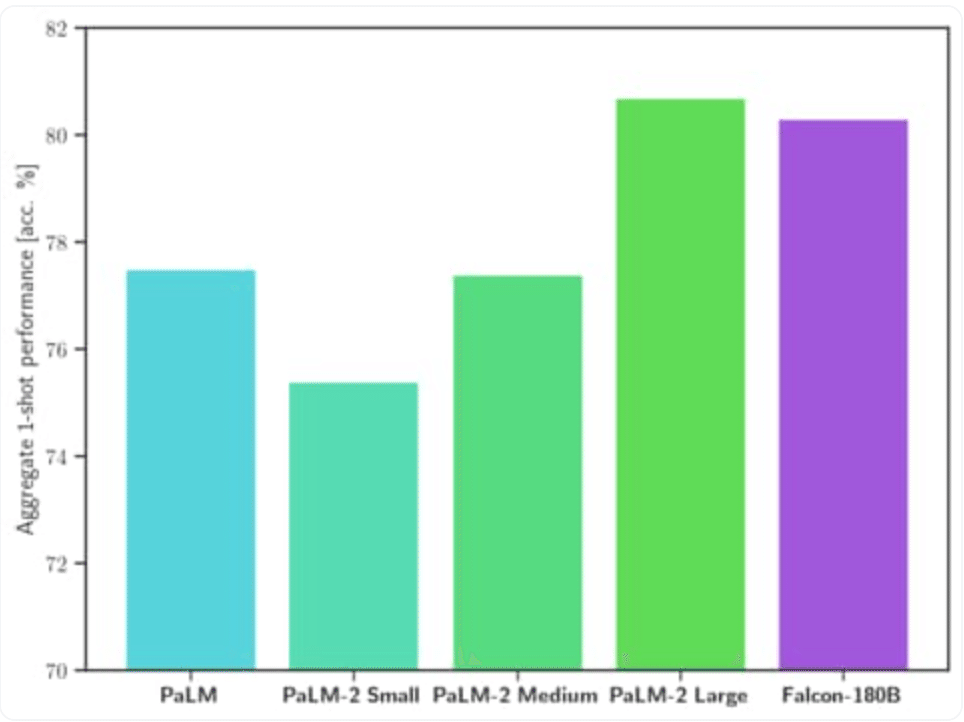
Hugging Face Leaderboardで、公開されているLLMの中で最高性能。

こちら からデモを動かせる。
ライセンスはApache 2.0をベースに修正を加えた独自ライセンス
商用利用は可能だが、”hosting use”を除き非常に制限された条件下での利用。
詳しくは、ライセンス を参照。
Zoom、Zoomプラットフォームの生成AIアシスタント、AI Companion発表
AI Companionの機能
Zoom Team Chatでのメッセージ作成支援

ミーティングに遅れた際のそれまでの内容要約や内容への質問

ミーティングを自動的にチャプター分け

リアルタイム文字起こし

ミーティングで出たアイデアをデジタルホワイトボードにピックアップ、自動カテゴライズ

自動サマリー作成、発言者と発言内容、重要トピックの強調表示、next stepの概説

チャットでのやり取りから、ミーティングの目的を自動検出。スケジュールボタンによるスケジュールの自動調整も。
これらは、Meta Llama 2、OpenAI、AnthropicとZoom独自LLMを動的に組み込み実現。
Zoomの音声データ、ビデオデータ、チャットなどのデータをモデル学習には使用しない。
ChatGPT plugin紹介
AskTheCode

GitHubリポジトリのURLを与え質問すると、そのリポジトリのコードの説明をしてくれる。
実行例 とりあえず触ってみた感じはあまり期待した回答は返ってこなかった。 LangChainの OpenAIChat クラスの解説をしてもらおうとしたら、自前でOpenAIChatクラスを記述して説明し出したりした(聞き方が悪かったかもだが)
GitHub Copilot Labsを使えた方が色々よさそう
Ai PDF

PDFのリンクを渡すと内容について解説してくれる。
実行例
「全文を処理しました。」と書いているが全文は処理していない。
Ai PDFのログを見る感じ6ページ目まで見ているっぽい(コンテキストサイズ超過と思われる。"self-attenti" で終わっている)。
[
"[Pages 1:\nProvided proper attribution is provided, ...
...
"[Pages 6:\nTable 1: Maximum path lengths, ...
...As noted in Table 1, a self-attenti]"
]diagr.am

チャートやグラフなどの作成をしてくれる。
実行例
daigr.am上でのグラフへのリンクも提示してくれる
データを渡せばそれに基づいてグラフを作成してくれる。
(ビジネス事例)人的資本経営を生成AIなどで支援するサービス 「HR Innovation for DX」
生成AIを活用したコーチングで日常の対話による人事フィードバックや情報提供を行うなど、迅速な人事施策の展開を支援。
アセスメント(仮説検証)、全体構想の策定と施策検討、実行と効果測定の3フェーズ
アセスメントフェーズ
部門人事戦略を実現させるうえで障壁となっている人事業務の課題を洗い出し、人事部目線ではなく部門や従業員目線で従業員ライフサイクルに応じた課題とテクノロジーを活用した解決策を仮説立て。

全体構想の策定と施策検討
仮説検証結果をもとに、俯瞰的な視点で人事業務とテクノロジーを一体化したあるべき姿を検討。
全体像を構想後、課題解決に向けた施策を実現するためのスコープの優先順位付けを行い、実践スケジュールを策定。
AIチャットボットによる自律的なキャリア形成を促す従業員への問いかけ(コーチング)
AIを活用した、保有スキルやキャリア志向を考慮した適切なアサインマッチング
部門人事戦略実現に向けた現状と実績値のギャップ(部門の人員数やスキルセットなど)の可視化
実行と効果測定
アジャイルアプローチでMVP作成と効果測定を繰り返し、改革後の部門人事業務を確立。
ユースケース
課題:従業員に自発的なキャリア形成やスキルアップを促したいが、定期的に個別のキャリア形成を促す施策を実施することは、人事部門のリソース制限もあり困難。
HR Innovation for DXでの解決策
生成AIが人事関連データを参照して従業員別に作成したキャリア形成を促す質問を自動問いかけ。
AIチャットボットが従業員と過去にやり取りした内容を踏まえて、有益な研修情報や人事関連情報などに関して問いかけることで、従業員の興味に沿ったスムーズな対話を展開し業務推進を支援。
AIチャットボットとの対話を通じたコーチングにより、従業員の自律的なキャリア形成を実現。

お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。
この記事が気に入ったらサポートをしてみませんか?