
Llama 2, ChatGPT性能悪化論文, etc - Generative AI 情報共有会 #1

こんにちは、ZENKIGENデータサイエンスチームの栗原です。現在は主に『harutaka EF(エントリーファインダー)』の自然言語処理周りの研究開発に携わっています。
今日からZENKIGEN Data Science Teamのマガジンで「Generative AI 情報共有会」として、直近1週間で出た生成AI関連の情報を毎週共有していきます。
背景
第一回なので、背景を記載しておきます。
現在ZENKIGENでは、「Generative AI最新情報共有会」という会を毎週行っています。
主にZENKIGENの経営層向けに、私が直近1週間で出た生成AI関連の情報の中からピックアップし、情報共有を行うものです。
今回、この内容を外部に公開すると良いのでは? という話になり、この連載を始めることになりました。
基本的に毎週水曜日に、その週に実施した社内共有会の内容を外部向けに多少修正した上で公開していく予定です。
内容は生成AI関連の情報となりますが、記事の方向性を記載しておきます(期待値調整の意味も込めて)。
技術の詳細には触れません
社内共有会は主に経営層向けに行っているもので、専門的な技術解説を行う場ではなく、生成AI関連の潮流を追う目的のものです。そのため、基本的に「その技術で何ができるようになったのか?」「何がこれまでと違うのか?」といった視点での内容になります。
日本での生成AI活用事例を取り上げます
社内共有会で経営層から期待されていることの一つとして、「生成AIが実際にビジネスの現場でどう活用されているのか」を把握するということもあるため、最新技術だけでなくビジネスシーンでの活用事例を取り上げます。
取り上げる事例はHR業界にいる身なのでHR業界が多少多くなったり、私のその時の"気分"などで非常に偏りがあったりすると思います。
網羅的ではありません
毎週30分で実施している共有会で、その範囲で紹介できるトピック数には限りがあるため、直近1週間の情報を網羅しているわけではありません。
私の興味がどちらかというとNLP(自然言語処理)寄りなので、ピックアップするトピックに偏りがある可能性があります。
それでは、今週社内共有会で共有した内容を紹介します。
今週のピックアップ
MetaからLlama 2が公開
世の中のLLM開発の中心的存在であったLLaMA(Large Language Model Meta AI)の後継モデルとして、商用利用可能な形でLlama 2が公開されお祭り騒ぎに。
【背景】
Metaは2023年2月に発表したLLaMAを専用のフォームへの申請を通してのダウンロードに制限していたが、2023年3月にリークされ、LLaMAをベースとした様々な派生モデルの研究開発が一気に広がる。

Googleはこの流れに危機感を示した(という内部文書と思われるもの流出)
しかし、LLaMAは商用利用不可だった → Llama 2は商用利用可能に 🎉
“商用利用可能”という触れ込みだが、一部制限あり。
月間アクティブユーザー数が7億人を超えるサービスを提供する企業はMetaに許可を得る必要あり(Llama2 Additional Commercial Terms)。 → 競合になり得るビッグテック企業を牽制する狙いか。
世の中のLLM開発、製品への組み込みが一気に進む可能性。
英語以外の言語でどうかは現状未知数か?
Llama 2の論文中では英語以外の言語での利用は “out of scope” とされている(Llama 2 論文 A.7 Model Cardより)。
ChatGPTの特定タスクにおける性能悪化の論文が公開され話題
GPT-3.5とGPT-4において、3月版と6月版で、数学の問題(素数判定問題)への回答能力、センシティブ(法を犯す方法など)な質問への回答傾向、コード生成能力、視覚的推論能力の変化を調査。
数学(素数判定)回答能力において、GPT-4は3月版は97.6%の回答精度だったのが、6月版では2.4%と大幅に悪化、コード生成タスクでも大幅な精度悪化という報告。
この内容が拡散され、話題に。

OpenAIからの上記性能悪化に対する声明と思われる更新。
gpt-3.5-turbo-0301、gpt-4-0314、gpt-4-32k-0314は2023年9月13日にサポートを終了する予定とアナウンスしたが、少なくとも2024年6月13日まで延長する。
新モデルをリリースするかの判断のために多くの評価指標を見ている。大半の指標で改善されていることを確認しているが、パフォーマンスが悪化するタスクもあるかもしれない。そのために特定のバージョンのモデルを指定できるようにしている。
新モデルの性能がある領域で芳しくなく改善を望む場合は、https://github.com/openai/evals に貢献して、モデルの欠点を報告してほしい。
論文の結果に対して疑問を投げかける記事が投稿される。
素数判定タスクでは、論文内で使用されたデータはすべて素数のデータ。
素数でないデータも含めて検証を行うと、GPT-4の3月版はほとんどのデータで素数と判定し、6月版はほとんどのデータで合成数と判定するモデルになっている結果。→ 素数のみのデータで精度を測ったらGPT-4 6月版めちゃくちゃ精度悪化!という認識に(実際はどちらのモデルも素数判定あまりできないということ)。
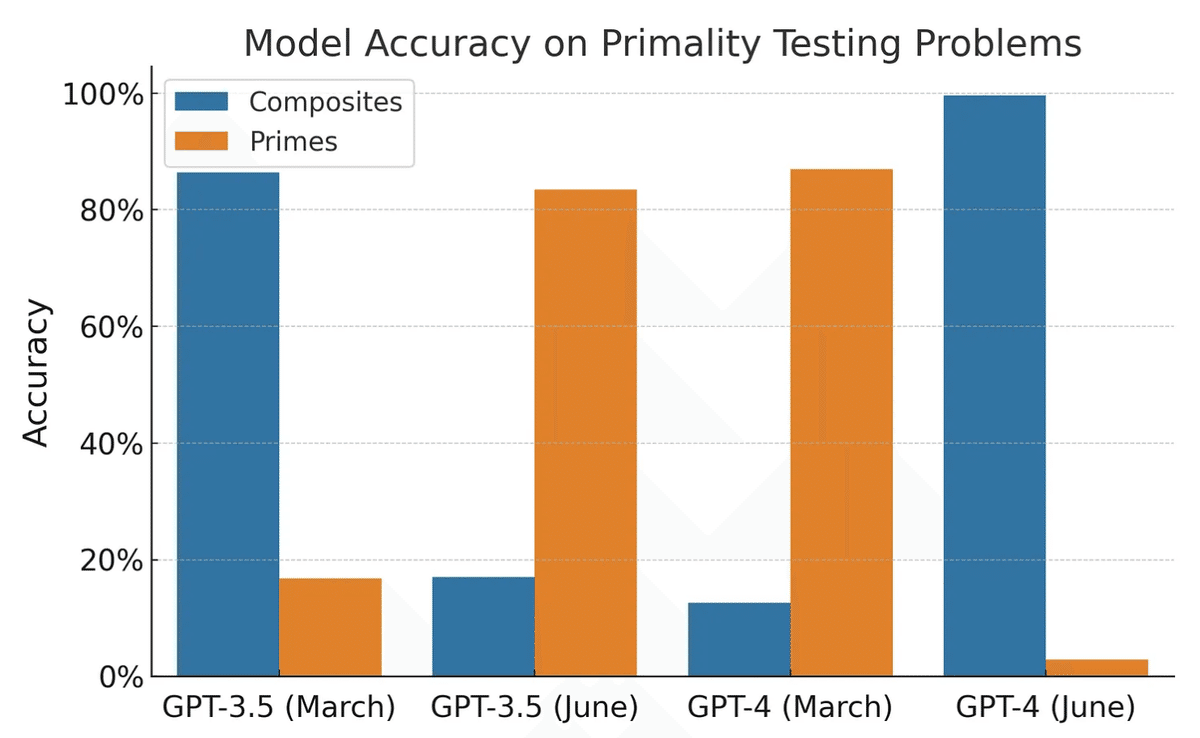
この結果から受け止めるべきは、モデルの挙動が大きく変わり得るということ。
生成AIを製品に組み込む上での評価の難しさを認識すること。
ChatGPTに「Custom instructions」機能が追加
ChatGPTがレスポンスを生成する際に考慮すべきユーザーの希望や要件を記憶しておくことが可能に。
(裏で行っていることは単純に、OpenAI側で、Custom instructionsの内容をシステムプロンプトに毎回与えてくれているというだけか?)
例(OpenAIの記事内の例を日本語で実行してみた)


Go言語で書いてくれはしたが、OpenAIの記事内の出力ほどシンプルにコードだけで最も効率的な解決策の提示はしてくれなかった(Custom instructionの指示日本語訳があまり良くなかったか)。

JASRAC、「生成AIと著作権の問題に関する基本的な考え方」を発表
3つの懸念を表明。
「生成AIの開発・利用は、創造のサイクルとの調和の取れたものであれば、クリエイターにとっても、文化の発展にとっても有益」だが、「著作物に代替し得るAI生成物が大量に流通することになれば、創造のサイクルが破壊され、文化芸術の持続的発展を阻害する」
「著作権法第30条の4の規定によって、営利目的の生成AI開発に伴う著作物利用についてまで(中略)AI開発事業者によるフリーライドが日本においては容認されるとする見解が散見されるため、大きな懸念を抱かざるを得ません。」
「生成AIの学習に伴う著作物の利用について、「著作物に表現された思想又は感情」の享受の目的がないという整理の下に著作権を制限する法的枠組みを持つ国はG7の中で日本だけであり、調和の観点から大きな懸念があります。」
(関連)バイデン大統領が、Amazon, Anthropic, Google, Inflection, Meta, Microsoft, OpenAIの7社をホワイトハウスに招集し、AI技術の安全、安心、透明な開発への移行を支援するために自発的な取り組みを行うことを要請。
電子透かしシステムなど、コンテンツがAIによって生成されたものであることをユーザーが確実に認識できる仕組みの開発などを約束。
(生成AIの発展を止めることは難しいと思うが、安全性や悪影響を受ける業界への対策、世界共通のルール整備などを進めることは必要だろう)
(生成AI活用事例) 生成AIを活用した「次世代型就職・キャリア支援サービス」を開発
大学キャリアセンター向けに生成AIを活用した「次世代型就職・キャリア支援サービス」を展開。
学生が入力した自身の経験や興味などに対して、「SelfAnalyzer(ChatGPT-4を活用予定)」が、学生の長所・適性などを分析。
「CareerNavigator(Azure OpenAI ServiceやChatGPT-4などを活用予定)」が、進路相談に対する簡易アドバイスからES(エントリーシート)・面接アドバイスまで幅広く行う。文章作成が苦手な学生に対しては、入力内容をもとに「学生時代に力を入れたこと」「自己PR」などの文章を生成することも可能。
(生成AI活用事例) 医療業界でのChatGPT利用 : 透析患者のコミュニケーションを円滑化するアプリ開発
透析患者や家族の透析に関する疑問点や愁訴に対し、AIが回答を生成し即座にバーチャル医療スタッフが音声&文字により回答をフィードバック。
社内で研究を重ねてきた画像・音声認識の技術を駆使して、実際に「人」が寄り添い、対応してくれているかのようなビジュアルを実装することにこだわる。
(医療という誤った情報を提供した場合の影響が大きい分野での利活用は難しい部分もあると思われるが、医療分野に今後どう生成AIが広がっていくか興味がある)
(生成AI活用事例) 法律分野でのChatGPT利用 : AI技術を駆使して法律的な問題解決や助言を提供するAI法律相談サービス
法令文や判例、論文などの膨大な情報を素早く解析し、ユーザーの法的問題について具体的な解答を出すことが可能。
現段階では人間の法律家・弁護士の補助的な位置づけであり、全ての法的問題を正確に解決するわけではない。AIはあくまで道具であり、最終的な判断は人間が行うべきという方針。
本物の弁護士や資格者や法律事務所が紐づき、相談者の法律相談に対応。AIだけでカバーしきれない問題や実際の問題解決には人間の資格者がサポート。
(法律分野も高い専門性が求められる分野で、どのように生成AIが広がっていくか興味がある。)
本プレスリリース内のFAQにもあるが、弁護士法第72条「非弁護士の法律事務の取扱い等の禁止」、弁護士法第74条「非弁護士の虚偽標示等の禁止」という法律がある中で、どこまでAI技術が法律分野に浸透していくか?
この記事が気に入ったらサポートをしてみませんか?