
ChatGPT風の画面を表示できるChatbot UIをFastAPIで作成した自作LangChainサーバに接続させる方法

ChatGPT風の画面を表示するOSSがいくつか出てきている中で、コードの読みやすさと操作性を比較した上でオススメしたいのが、Next.jsで書かれているChatbot UIというOSSだ。
ローカルでサクッと起動ができ、立ち上がるとこんな画面が表示される。
OpenAIのAPI Keyを入力すれば簡単にOpenAIのチャットモデルと接続される。API接続のChatGPTなので、本家のChatGPTよりはやりとりできる文字量が制限されるものの、本家のChatGPTではセンシティブな情報を扱うことができないため、API接続のUIにも価値はある。
ところでこのChatbot UI、ソースコードを読んでみると環境変数でAPI接続先を差し替えることができるようになっている。process.env.OPENAI_API_HOSTの部分だ。
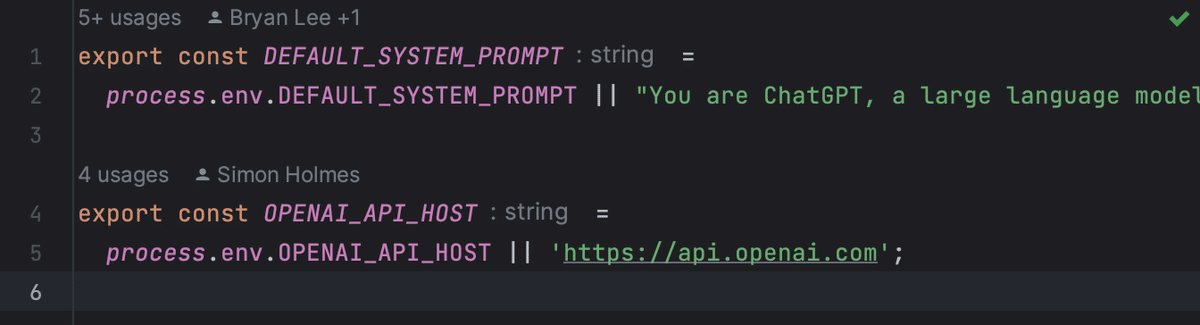
つまりOpenAIのAPIっぽいレスポンスを返すサーバーを作ってしまえば、好きなチャットボット実装をこのUIで試すことができるようになるのではないか、というのが今回の試みである。
これまでに書いていた以下の記事はこの試みの下準備なのであった。
サーバーのセットアップ
そんな訳で作成してみたのが以下の実装だ。
起動方法
以下の手順でサーバーを起動することができる。
$ git clone git@github.com:mahm/custom_chatbot_server.git
$ cd custom_chatbot_server
$ poetry install
$ poetry run python app/main.py起動すると以下のようなログが表示されるので、

以下のcurlコマンドを打って疎通確認をしておく。最終的に何もエラーが出なければOKだ。
$ curl -X POST "http://127.0.0.1:8000/v1/chat/completions" -H "accept: text/event-stream" -H "Content-Type: application/json" --data '{"model": "simple-conversation-chat", "messages": [{"role": "system", "content": "You are a poetic assistant"}, {"role": "user", "content": "Write a poem about the ocean"}], "max_tokens": 1000, "temperature": 1, "stream": true}'コードの解説
ディレクトリ構成は以下のようになっており、app/models以下にチャットモデルを増やしていくイメージで構成している。
.
├── app
│ ├── callbacks
│ │ ├── __init__.py
│ │ └── streaming.py
│ ├── models
│ │ ├── __init__.py
│ │ ├── simple_conversation_chat.py
│ │ └── summary_conversation_chat.py
│ ├── server
│ │ ├── __init__.py
│ │ └── app.py
│ ├── __init__.py
│ └── main.py
├── README.md
├── poetry.lock
├── pyproject.toml
└── railway.json以前のFastAPIサーバの実装ではシンプルに文字列をストリーミングで返せば良かったが、OpenAIのAPIはJSONで返されるため、もう少し実装に工夫が必要である。
動作を観察してみると、
テキストの差分はchoices.[].delta.contentに設定して送信する
送信が完了したら [DONE] という文字列を送信する
ということのようなので、以下のようなジェネレータを作成し、LangChainでの生成結果をストリーミングで受け取るジェネレータ(chat_generator)をラップして同じような動作を実現した。
async def streaming_response(json_data, chat_generator):
json_without_choices = json_data.copy()
json_without_choices["choices"] = [{
"text": '',
"index": 0,
"logprobs": None,
"finish_reason": 'length',
"delta": {"content": ''}
}]
yield f"data: {json.dumps(json_without_choices)}\n\n" # NOTE: EventSource
text = ""
for chunk in chat_generator:
text += chunk
json_data["choices"][0]["delta"] = {"content": chunk}
yield f"data: {json.dumps(json_data)}\n\n" # NOTE: EventSource
json_data["choices"][0]["text"] = text
yield f"data: {json.dumps(json_data)}\n\n" # NOTE: EventSource
yield f"data: [DONE]\n\n" # NOTE: EventSourceまた、Chatbot UIでは /v1/models をコールすることでモデルの一覧を取得しているので、このサーバーで扱えるモデルを返すようにしておく。
@app.get("/v1/models")
async def models():
return {
"data": [
{
"id": "simple-conversation-chat",
"object": "model",
"owned_by": "organization-owner"
},
{
"id": "summary-conversation-chat",
"object": "model",
"owned_by": "organization-owner"
},
],
"object": "list",
}idの値は適当で良い。このidの値をあとでモデル切り替えのために、以下のように利用する。if文でチャットクラスの実装を切り替えている。
@app.post("/v1/chat/completions")
async def chat_completions(completion_request: CompletionRequest):
logging.info(f"Received request: {completion_request}")
history_messages = completion_request.messages[:-1]
user_message = completion_request.messages[-1]
if completion_request.model == "simple-conversation-chat":
chat = SimpleConversationChat(history_messages)
elif completion_request.model == "summary-conversation-chat":
chat = SummaryConversationChat(history_messages)
else:
raise ValueError(f"Unknown model: {completion_request.model}")
# ...更にコードが続く...チャットモデルは最終的にはジェネレータを返せば良いという設計にしている。まだあんまり凝ったことをしていないので実装がシンプルになっているだけだとは思うので、後から変えるかも知れない。
import threading
from langchain import ConversationChain
from langchain.callbacks import CallbackManager
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from app.callbacks.streaming import ThreadedGenerator, ChainStreamHandler
class SimpleConversationChat:
def __init__(self, history):
self.memory = ConversationBufferMemory(return_messages=True)
self.set_memory(history)
def set_memory(self, history):
for message in history:
if message.role == 'assistant':
self.memory.chat_memory.add_user_message(message.content)
else:
self.memory.chat_memory.add_ai_message(message.content)
def generator(self, user_message):
g = ThreadedGenerator()
threading.Thread(target=self.llm_thread, args=(g, user_message)).start()
return g
def llm_thread(self, g, user_message):
try:
llm = ChatOpenAI(
verbose=True,
streaming=True,
callback_manager=CallbackManager([ChainStreamHandler(g)]),
temperature=0.7,
)
conv = ConversationChain(
llm=llm,
memory=self.memory,
)
conv.predict(input=user_message)
finally:
g.close()これはConversationBufferMemoryに会話の履歴を保存した状態でチャット文章を生成するクラスの例である。実装の本体はllm_threadで、FastAPI側にはThreadedGeneratorで生成したジェネレータを返す仕組みだ。
こんな具合のクラスをいくつか用意することで、Chatbot UI側でモデルを切り替えて遊ぶことが出来る。
UIのセットアップ
さてUI側にも少し手を入れる必要がある。さしあたってやる必要があることは以下の2点だ。
環境変数の設定
モデル定数の書き換え
まずは動作確認
まずは素の状態で起動することを確認しておこう。
以下の手順で画面が起動することを確認する。
$ git clone git@github.com:mckaywrigley/chatbot-ui.git
$ cd chatbot-ui
$ npm install
$ echo OPENAI_API_KEY=$OPENAI_API_KEY > .env.local
$ npm run devOPENAI_API_KEY環境変数を設定していない場合は、.env.localを直接編集してOpenAIのAPIキーを設定するようにして欲しい。
問題がなければ http://0.0.0.0:3000/ にアクセスすることで、以下の画面が立ち上がるはずだ。
環境変数の設定
起動を確認したら少しばかりのコード変更作業に戻る。
先ほどの.env.localファイルを編集して以下のようにしておこう。OpenAI本家に接続しない場合はOPENAI_API_KEYの設定は必要ない。
OPENAI_API_HOST=http://0.0.0.0:8000これで先ほど立ち上げたサーバに接続が向かうようになる。
モデル定数の書き換え
元のコードではチャットで扱えるモデルの値がなぜかハードコードされているため、ここにカスタムで扱うモデルの値を追記する。
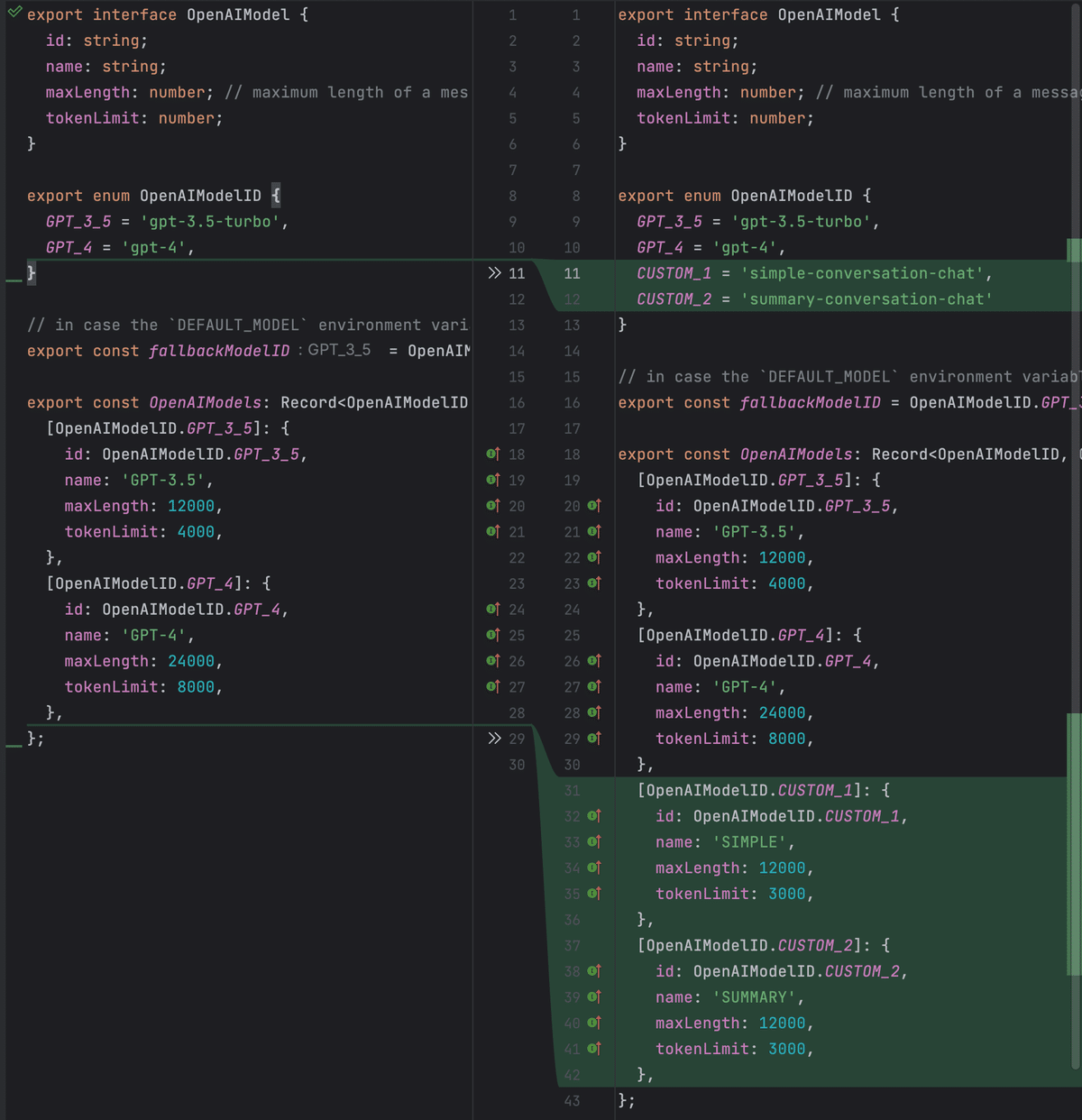
GitHub上でも差分を確認できるようにしているので参考にされたい。
ここまで設定を完了してUIのサーバを再起動すると、以下のようにカスタムモデルを扱えるようになる。
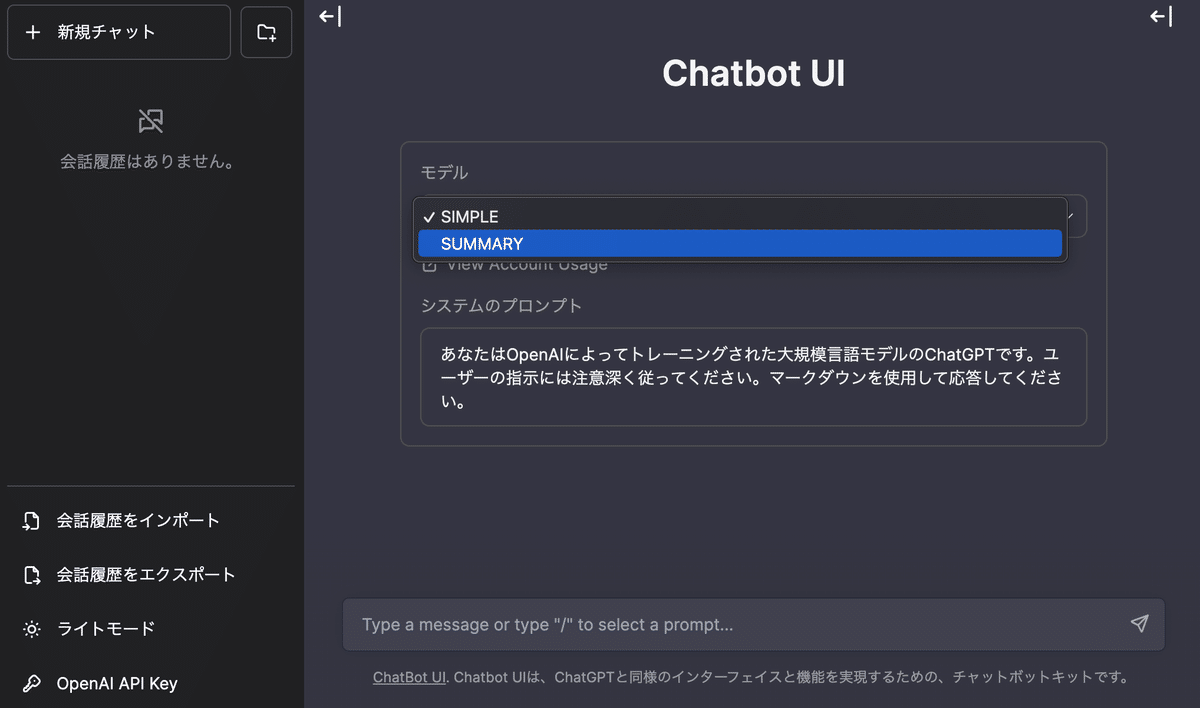
今後の展開
Chatbot UIはVercelへ簡単にデプロイできるようになっているのと、今回用意したcustom_chatbot_serverのコードベースはRailwayへ簡単にデプロイできるようにしているため、LangChainで作成した凝ったエージェントのデモもこれで比較的容易に行えるようになる。
デモだけでなく、自分用の凝ったエージェントを走らせても面白いだろう。セキュアな情報を扱う場合は、サーバ公開時に十分に注意されたい。
現場からは以上です。