
AI 実装検定への道(8)

AI 実装検定 A級合格へ向けて学習を進めています。
前回投稿が7回目で、引き続きGoogle Colaboratoryを利用してプログラミングの章を進めて書いていて、227ページの途中まで進みました。
(10ページしか進めなかったので、今回はもう少し進みたい・・・)
第7回目では、多次元の配列(行列)について合計(sum)、最大(max)、最小(min)を求めたり、それを「axis」を使って列ごと(縦方向)であったり、行ごと(横方向)に抜き出してみたり。「mask」を使って条件に合致した判別と「mean」による平均値算出。最後に「NumPy」のような拡張ライブラリのひとつである「pandas」を使って表形式に文字を並べ、そこからデータを選択するというところまで進めました。
今回も引き続き、「Series」についてアレンジを勉強していきます。
またいつものように、NumPyとpandasを呼び出しておきます。
(コード記述)
import numpy as np
import pandas as pd
[2,5,1,3,0,7]のような要素を持つ配列(行列)をpandasのSeriesに渡すと、番号が追加 Indexとペアで値を出力します。
(コード記述)
pd.Series ([2,5,1,3,0,7])
(結果)
0 2 1 5 2 1 3 3 4 0 5 7 dtype: int64
次の例は、Indexに対して任意の複数候補を記述し、それぞれに同じ7という値を割り当てた例を記述します。
(コード記述)
pd.Series(7, index=[125,138,269])
(結果)
125 7 138 7 269 7 dtype: int64
公式テキストにわかりやすく説明されています。
『辞書機能』
上記のようにIndexに割り当てたのを名前(key)と配列(行列)の値(value)をペアにしてデータを格納する方法。確かに、こう説明されると理解しやすいです。私たちが、パソコンなので短縮入力したい時、例えば・・・私の名前「前田雅之」を全部入力するのではなく「ま」と入力したら「前田雅之」と入力させる独自辞書・・・ちょうど「ま」が名前(key)であり、「前田雅之」が配列(行列)の値(value)というペアになっています。
次に簡単に3つのワードで辞書を作ってみます。
3、4、2をIndexに割り当てたのを名前(key)とし、それに対する配列(行列)の値(value)を愛知、名古屋、熱田としてみます。
(コード記述)
pd.Series({3:"愛知",4:"名古屋",2:"熱田"})
(結果)
3 愛知 4 名古屋 2 熱田 dtype: object
これに対して、Indexに指定していない1を加えて、1、2、3と指定してみます。
(コード記述)
pd.Series({3:"愛知",4:"名古屋",2:"熱田"},index=[1,2,3])
(結果)
1 NaN 2 熱田 3 愛知 dtype: object
Indexに指定していない1の部分には『NaN』と表示されました。
NaN(Not a Number)という意味だそうで、非数として欠損していること欠損値を表すとのことです。
これまでのSeriesは、pandasの中で一次元データで1列を表す機能でしたが、次にDataFrameを使って2次元のデータを扱っていきます。また、Seriesのデータとして中間考査(midscore)、期末考査(endscore)を準備して次に進みます。
(コード記述)
midscore=pd.Series({"国語":85,"算数":95,"理科":90,"社会":75,"英語":65})
midscore
(結果)
国語 85 算数 95 理科 90 社会 75 英語 65 dtype: int64
これは、前回勉強した「score」と似ています。
(同じ点数を設定しています。)
(コード記述)
score=pd.Series({"国語":85,"算数":95,"理科":90,"社会":75,"英語":65})
score
(結果)
国語 85 算数 95 理科 90 社会 75 英語 65 dtype: int64
結果は同じに見えますが、どのように変わっていくでしょうか?
期末考査(endscore)には、少しいい点数を設定しておきます。(笑)
(コード記述)
endscore=pd.Series({"国語":87,"算数":98,"理科":95,"社会":85,"英語":82})
endscore
(結果)
国語 87 算数 98 理科 95 社会 85 英語 82 dtype: int64
これで、中間考査(midscore)、期末考査(endscore)を準備ができました。これを2次元の1つのDataFrameに格納するわけですが・・・
(コード記述)
score=pd.DataFrame({"中間":midscore,"期末":endoscore})
score
おっと、ここで、下記のようなエラーが表示されました。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
NameError Traceback (most recent call last)
<ipython-input-10-922a9e0caff0> in <module>
----> 1 score=pd.DataFrame({"中間":midscore,"期末":endoscore})
2 score
NameError: name 'endoscore' is not defined
『endoscore』なんて、ありませんよ!的なアラートです。
endscore・・・「o」が一つ余分でした。
(コード記述)
score=pd.DataFrame({"中間":midscore,"期末":endscore})
score
(結果)
中間 期末
国語 85 87
算数 95 98
理科 90 95
社会 75 85
英語 65 82
おっと、なんだかちゃんとした表のように表されました。
これは、DataFrameについては、今利用している「Google Colaboratory」の機能において、表形式にまとめて見易いようにしてくれるんだそうです。
これだけでも十分見易いのですが、「Google Colaboratory」において下記の鉛筆(あるいはチョーク?)のようなマークをクリックすると・・・


ま、数値が2列しかないので、こんな感じですが、もっとたくさんになるとExcelで見るような表になりそうです。で、さらに右上の「Filter」をクリックすると下記のように、下記のように詳細条件でデータ抽出されるんだそう。これは便利ですね。
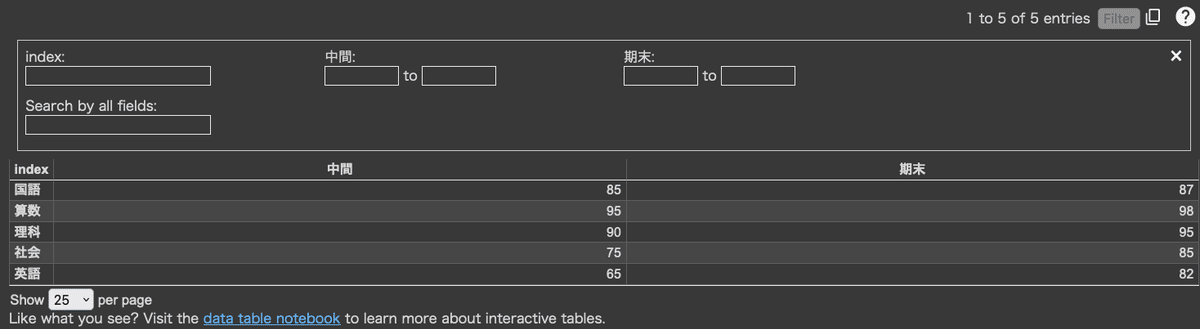
学級の中で、生徒の指名付きで分類して、次の指導に役立てるとか出来そうですね。では、もう一つデータを追加しておきましょう。endscore2 として再試験後のデータ・・・(嫌な響きだけど)を加えます。
(コード記述)
endscore2=pd.Series({"国語":92,"算数":98,"理科":97,"社会":90,"英語":92})
endscore2
(結果)
国語 92 算数 98 理科 97 社会 90 英語 92 dtype: int64
これも含めてDataFrameにまとめます。
(コード記述)
score=pd.DataFrame({"中間":midscore,"期末":endscore},"再試":endscore2})
score
(結果)
中間 期末 再試
国語 85 87 92
算数 95 98 98
理科 90 95 97
社会 75 85 90
英語 65 82 92
鉛筆マークをクリックすると・・・

こんなふうに、pandasのDataFrameを利用して、Excelのようにデータを扱えることがわかってきました。一方、pandasではSeriesのIndexが各データの値(value)にアクセスするための手段(紐付けというか・・・)として用意されましたが、DataFrameにもIndexが準備されています。
ま、表形式に表すと、国語の上に「Index」と表示されているので、わかるようなものですが、ここで「Index」を読み込んでみましょう。
(コード記述)
score.index
(結果)
Index(['国語', '算数', '理科', '社会', '英語'], dtype='object')
次に列のタイトル(columns)を読み込んでみます。
(コード記述)
score.columns
(結果)
Index(['中間', '期末', '再試'], dtype='object')
自身が指定した通りにちゃんと返してくれます。
このDataFrameには、中間考査(midscore)、期末考査(endscore)ならびに期末後の再試験のデータがまとめて保持されています。DataFrameは2次元のデータであり列のタイトル(columns)には考査(中間、期末、再試)と、行のタイトル(Index) には国語, 算数, 理科, 社会, 英語の教科が格納されていました。
また、別の見方をすると、中間、期末、再試の3つのSeriesで構成されているとも言え、それぞれのSeriesを呼び出すことも可能です。
(コード記述)
score["再試"]
(結果)
国語 92 算数 98 理科 97 社会 90 英語 92 Name: 再試, dtype: int64
今回は短いですが、ここまでにします。
前回から引き続き「NumPy」のような拡張ライブラリのひとつである「pandas」を使って表形式に並べていくことを勉強しました。「Series」を使って各格納データを整理し、「score」を使って「Series」を定義づけるのだが、同時に「midscore」「endscore」なるものを生成しておいて「DataFrame」でExcelのような表形式に表現できました。「Google Colaboratory」の機能において、DataFrameについては表形式にまとめて見易いようにしてくれるそうです。
(今回は、間違い2回含めて15本)
次回は、234ページから進めていきます。