
どんな画像でもセグメンテーションできるモデル「SAM」の紹介

自然言語界隈では、GPTシリーズをはじめとした大規模言語モデルの登場によって、追加学習なしでいろいろなタスクをこなせるようになっています。このような汎用モデルは「基盤モデル(foundation models)」とよばれています。高性能な基盤モデルの公開によって自然言語モデル活用のハードルが大きく下がりました。
基盤モデルの開発は、自然言語以外でも行われています。本記事では、Metaから発表された画像セグメンテーションにおける基盤モデル、Segmentation Anything Model(SAM)を紹介します。
そもそも画像セグメンテーションとは?
まずは画像セグメンテーションについて簡単に紹介します。このタスクは、画像のどこに何があるかをピクセル単位で検出するというものです。以下の左の写真を右の図のように色分けするイメージです。
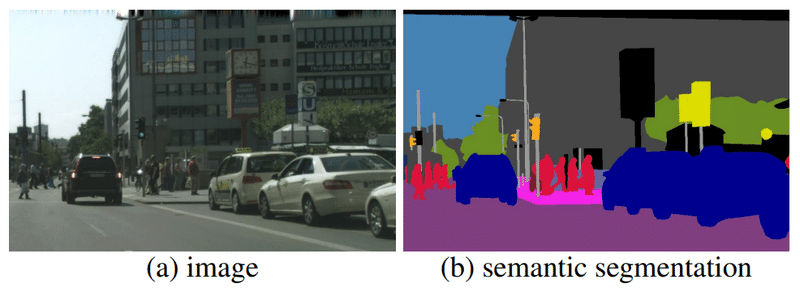
上図の画像セグメンテーション例では、各ピクセルをクラス分類するセマンティック・セグメンテーションを行っています。どれが背景でどれが車で人で…といった判断ができるため、自動運転や無人配送ロボットなどに応用できそうです。これ以外にも画像セグメンテーションには、次のような活用例があります。
医療画像(CT、MRIなど)から病変や疾患の検出
ドローンと組み合わせてインフラ設備や建物、製造プラントの外観検査
製造ラインにおける品質評価、食品への異物混入の検出
人工衛星の画像をもとに災害対策や農業に応用
Segmentation Anything Model (SAM)とは
SAMはMetaから発表された画像セグメンテーションの基盤モデルです。汎用性の高さが特徴で、学習データに含まれていた物体はもちろんのこと、学習データに含まれていない、モデルが初めて見る物体に対してもかなりイイ感じにセグメンテーションしてくれます。
従来の画像セグメンテーションモデルで高い精度を得るには、「自動運転用のモデルを作るために都市景観データセットで学習」など、用途に沿ったデータセットでの学習が必要でした。しかし汎用モデルのSAMによって、追加の学習なしでもあらゆるタスクで良い精度が得られるようになり、学習の手間が大きく省けると期待されます。
SAMのライブラリはApache License 2.0で公開されているため、商用利用も可能です。ライブラリの利用方法や実装例はgithubにて詳しく紹介されていますので、興味がある方はぜひのぞいてみて下さい。
デモページでSAMを触ってみよう!
さっそくSAMを動かしてみましょう!デモページが公開されているので、手軽にすぐ試すことができます。コチラのページにアクセスして利用規約を確認した後、用意された画像を選択したり、画像をアップロードしたりしてセグメンテーションができます。
今回はこちらの画像を使ってみました。

デモページでは、「座標指定」もしくは「矩形による領域の指定」でセグメンテーション対象を指示することができます。
座標指定によるセグメンテーション
マウスクリックで画像上の点を指定すると、その点にある物体を検出してセグメンテーションしてくれます。画像内の水色の点が指定した座標です。足先など惜しい所もありますが、指定したニワトリを検出できています。

矩形領域指定でのセグメンテーション
クリック&ドラッグで四角の範囲を決めると、その中にある物体をセグメンテーションしてくれます。以下のように特定のニワトリを囲むと、ピンポイントで抽出できました。

ここまではセグメンテーション対象の位置を指定しましたが、画像全体に対してセグメンテーションすることもできます。
画像全体セグメンテーション
コチラの機能は座標指定によるセグメンテーションを応用しているようです。画像全体に格子状に座標をプロットしてセグメンテーションを行い、確度の高いものを抽出しています。
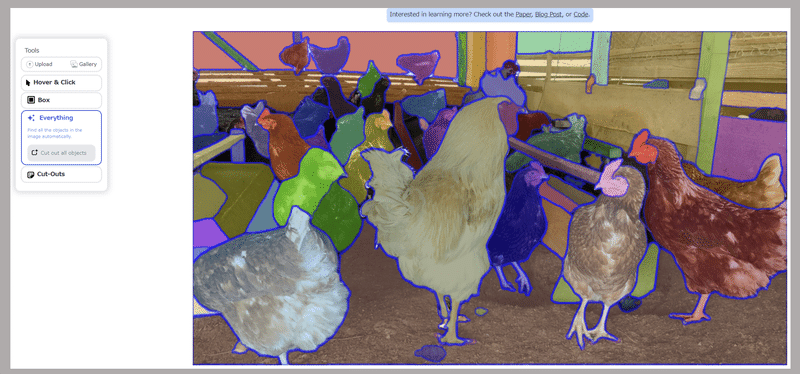
ちなみに、デモサイトには検出した領域を切り抜く機能もあったりします。

デモページの出力は規約上商用利用はできませんが、画像切り抜きツールとして快適に使えそうな仕上がりです。画像アップロードや画像全体処理には数秒の処理時間が必要ですが、検出箇所の指定や画像切り抜きなどはほとんど待ち時間なく、サクサクと動作します。
セグメンテーション例
他にもいろんな画像で、画像全体セグメンテーションを試してみました。「Segment Anything」の名の通り、様々な物体を認識してセグメンテーションしてくれます!

SAMの特長
上記のセグメンテーション例の通り、SAMはあらゆる画像に対応できる汎用モデルです。加えて、デモページでは座標指定に応じて素早くセグメンテーションが実行されます。SAMの論文によると、この汎用性とレスポンスの速さは、学習データとモデル構造の工夫によって実現されているようです。
膨大な画像枚数・マスク数のデータセットによる学習
SAM以前にもセグメンテーションデータセットはありましたが、SAMの研究チームは、基礎モデルを作るためにはもっと大量の、高品質かつ多様な学習データが必要と考えて、1100万枚の画像に10億ものマスク(物体の領域を示す情報)が含まれる大規模なデータセットを新たに作成しました。
下図は、セグメンテーションにおける定番データセットの一つである「COCOデータセット」に含まれる画像と、SAMのデータセット「SA-1B」に含まれる画像をならべたものです。

従来のデータセットでは車両はまるごと一つのマスクなのに対し、SAMのデータセットではフレームや窓といった部品単位まで細かくマスクを作成しています。これにより、単純な学習データ枚数だけでなく、一枚の画像に含まれる情報量も飛躍的に増加しています。こうしてあらゆる物体の形状や境界線を学んだことにより、初めて見る物体の境界も推測できる汎用性を手に入れたのだと思われます。
さて、このような精細なデータセットをどうやって作成したのでしょうか。これだけ細かなデータを人力で作成するのは非現実的です。そこでSAM開発チームは、モデルの予測結果を活用して、以下の3ステップでデータセット作成を行いました。
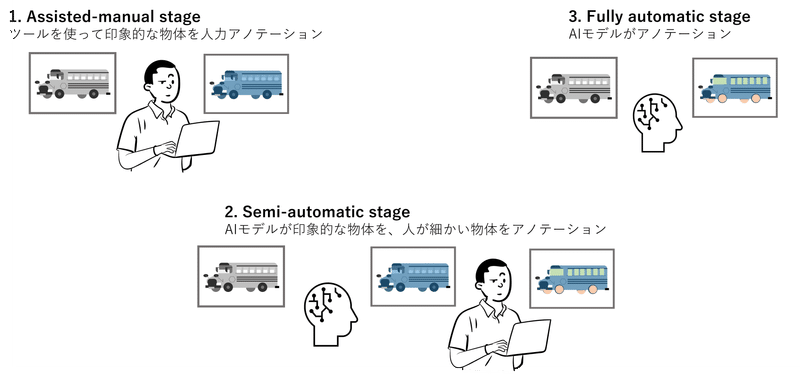
1 人によるアノテーション(Assisted-manual stage)
学習データ作成の第一段階として、学習途中のSAMを組み込んだアノテーションツール(画像の領域選択とラベル付けを効率よく行えるアプリケーション)を用いて、人がアノテーションします。物体の領域と、その物体が前景なのか背景なのかをラベル付けします。
この段階では容易に判断できる物体に注力しており、アノテーションに30秒以上時間がかかる場合は次の画像へ移るよう作業者に指示していたそうです。
2 モデルによるアノテーション + 人による追加アノテーション(Semi-automatic stage)
1 で作成したデータで学習したモデルが画像内の物体をセグメンテーションしたあとに、人がその結果を確認し、検出されていない細かい物体のアノテーションを行います。これにより、多様な物体のマスクデータを作成します。
3 全自動アノテーション(Fully automatic stage)
1, 2 のデータで学習を進めたモデルに加え、セグメンテーション結果が安定したものか判断する仕組みや、同じ物体を重複して検出したものを排除する仕組みを組み合わせ、モデル自身が学習データを作れるレベルまで精度を向上させています。
最初は人力ではじめ、そこからモデルの成長に伴い段階的にモデルに任せていくことで、データ作成を効率化しつつ品質を守って大量の学習用データを作成しています。
画像の処理とタスク指示の処理を分割したモデル構造
SAMのデモページでは、マウスカーソルを移動させるだけで次々と検出した物体の表示が切り替わっていきます。画像を入力としたセグメンテーション処理を毎回実行していたのでは、このような処理はとても実現できません。
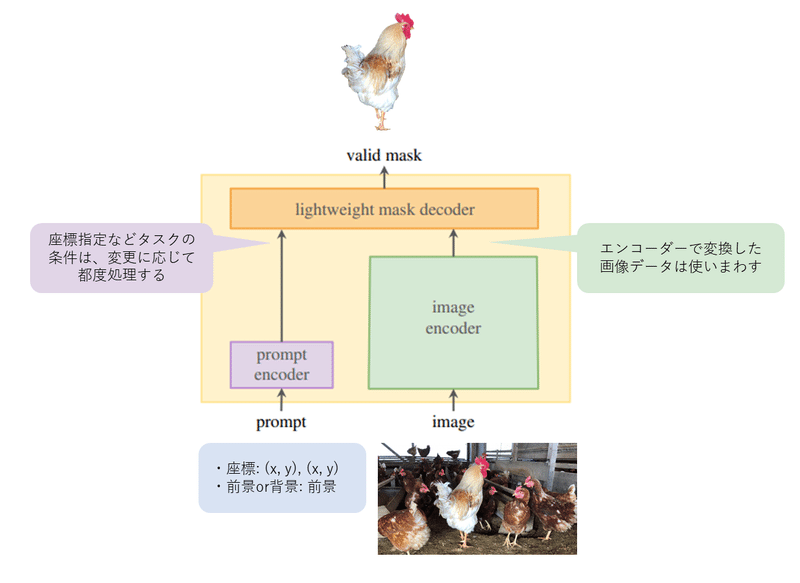
リアルタイム性の高い応答は、SAMのモデル構造によって実現されています。SAMは、下図のように画像とタスク指示を別々のエンコーダーで受け取って処理を行います。時間がかかる画像エンコード処理は初回だけで済むため、同じ画像に対するさまざまなセグメンテーション処理のすばやい気切り替えが可能になります。
SAMの改良や応用
どんな画像でもセグメンテーションできるSAMですが、とはいえうまくセグメンテーションできないこともままあります。
本記事の実行例で鳥の脚先のような細かい箇所は完全に検出できなかったように、「SAMは細かい形状のセグメンテーションが苦手」という報告があります。これに対して高品質のデータセットを追加で作成して学習させたり、画像細部の情報を失わないよう工夫した「Segmentation Anything High Quality(HQ-SAM)」なるモデルが発表されています。論文にある例を見ると、昆虫の脚や椅子の隙間から覗く背景といった、細かい構造についても正しく検出できています。

また、SAMと既存手法を組み合わせて物体の追跡を行うモデル、「Track Anything」も公開されています。githubでは、いくつかの実行例を見ることができます。こちらはデモページがあるので、好きな動画で試すことができます。
以上、追加学習なしであらゆる画像のセグメンテーションができるモデル、SAMの紹介でした。
SAMによって画像セグメンテーションの利用ハードルがグッと下がったという印象を受けました。自然言語の基礎モデルによって大規模言語モデル活用が一気に広まったように、今後画像セグメンテーションの利用やモデル開発も加速していくと期待されます。画像セグメンテーションは自然言語とくらべるととっつきにくいですが、むしろビジネスシーンでは、人が視覚や画像から何かしらの判断・意思決定を行うというシチュエーションは多いかも知れません。
また私生活においても、 Google Pixel の消しゴムマジックのようにスマホの写真加工の性能向上によって知らず知らずに恩恵を受けている…なんてことが増えていきそうです。
この記事が気に入ったらサポートをしてみませんか?