
サッカーゲームのAIを作るKaggleコンペに参加した

昨日まで開催されていた、サッカーゲームのAIを作るKaggle football コンペに参加した。イングランドの強豪であるマンチェスター・シティがGoogleとタッグを組み開催した、サッカー好きのエンジニアとしては心躍るコンペだ。初のKaggle、初の強化学習、様々な学びがあったので参加記を残しておく。

図1. 強化学習により効率的なビルドアップを学習した様子
事前準備
機械学習にはそれほど馴染みがなく、特に強化学習はCart Poleに触れたことがある程度。まずは一度まとまった知識を学んでおきたいと思い、Pythonで学ぶ強化学習という本を買った。Day4の途中までしか読めていないが、数式の説明も丁寧で分かりやすい。コードがたくさん載っているが、この部分はGitHubにあるコードをエディタで読んだ方が読みやすいかもしれない。
また、Google Research Football(GRF)に関してもいくつかの情報を調べてみた(ブログ、GitHub、論文)。GRFは2019年にGoogle AIがオープンソースで公開したサッカーゲームの強化学習環境だ。サッカーゲームは、報酬(=ゴール)が少ない、確率的な環境である(=同じ場面でも味方や敵の行動が変わる)、マルチエージェントである、などの理由から強化学習が難しい環境らしい。論文では、代表的な手法で学習したベンチマークが公開されているが、工夫しないと学習が上手くいかないことが分かっている(論文中Fig.4)。
ローカルでの学習
KaggleではNotebookというオンラインのJupyter環境があり、そこで基本的な開発ができる。公式のGetting StartedのNotebookにあったシンプルなルールベースのエージェントを、斜めにも走れるように改良したものを提出すると、大体真ん中あたりの順位になった。
ただ、Notebookの環境は統合開発環境と比べると開発効率が悪く、また長時間の学習を回す際に何かと不便そうだったので(GPUも使えるようだが)、学習環境をローカルに構築することにした。まずは自前のUbuntuデスクトップ(8CPU)にGRFの環境をDockerで入れてみた(マニュアル)。
GRFにはOpenAI BaselinesのPPO2という強化学習アルゴリズム実装を使って学習するスクリプト(examples.run_ppo2)が付いており、これを使えば簡単に強化学習を実行できる。学習中の様子も保存でき、replay.pyを使えば3Dのゲーム画面で再生することもできる。デフォルトの空のゴールにシュートを決める問題設定(academy_empty_goal_close)なら、CPUでも数分で学習が終わった。

図2. 強化学習によりシュートを学習した様子
ただ、11vs11の問題を学習するにはより複雑なネットワーク構造(論文中Fig.8)を使う必要があり、複雑なネットワークの効率的な学習にはGPUが必要となる。今回はGCPのDeep Learning VMでGPU環境を構築することにした。
GCPでの学習
GCPで11vs11を学習するあたり、非常に参考になったのがこちらのブログ: Reproducing Google Research Football RL Results。この記事にならい、Deep Learning VMを8CPU、8GB RAM、 GPUはTesla K80で構成した。初めは4CPUにしていたが、GPUでの誤差逆伝搬の計算よりもCPUでのサッカーゲームの実行がボトルネックとなることが分かり、8CPUに増やした。ちなみにCPUのパートとGPUのパートが交互に実行されているようなので、非同期に実行できるなら更なる速度向上が見込めるかもしれない。
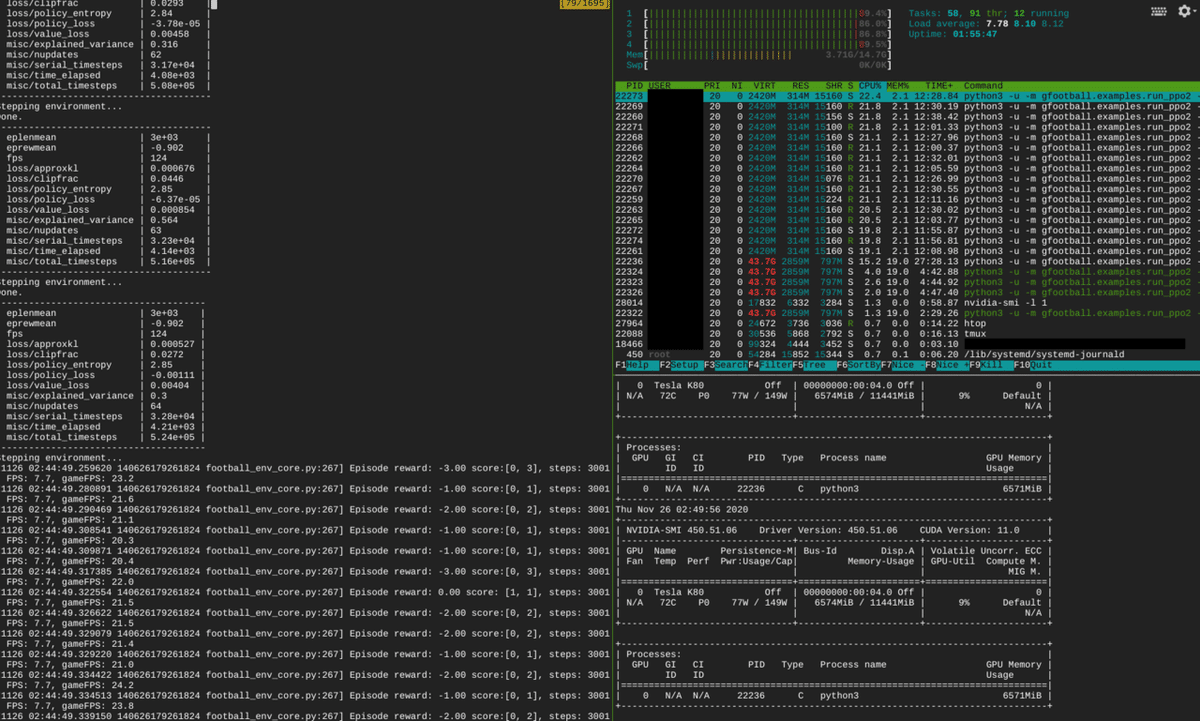
図3. CPUとGPUの使用率を睨みボトルネックを解消
学習に必要なスクリプトは先ほどと同じくexamples.run_ppo2だが、学習率などのパラメタを設定する必要がある。論文中のHyper-parameter searchによって見つかった最適なパラメタを指定するスクリプト(repro_checkpoint_easy.sh)があったのでそれをそのまま使用した。なお、ここではネットワーク構造はimpala_cnn([16,32,32]ch)を指定しているが、厳密に論文を再現するならばgfootball_impala_cnn([16,32,32,32]ch)を使うべきだろう。
設定したマシンではおよそ合計180FPSで学習することができ、およそ30時間かけて論文のFig.4にあるPPO@20Mに到達できた。なお、学習時のログに出るFPSは1つのプロセスあたりのFPSで全体でのFPSはそれに環境の数(num_envs)をかけたものであることに注意。エピソードあたりの報酬(得点 - 失点)は学習が進むにつれて上昇し、20M stepsを過ぎたあたりから1を超えてコンスタントに勝てるようになっていることが分かる。
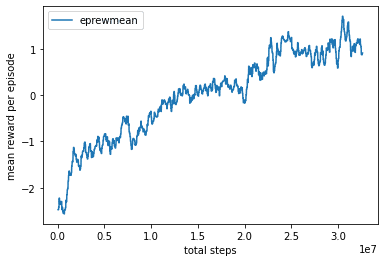
図4. ステップ数と平均報酬の関係

図5. ごっつぁんゴールを決めるエージェント
強化学習モデルの提出
残念ながらこのステップは断念してしまったが、途中までの取り組みを記す。
まずコンペに提出するスクリプトには観測を受け取ってアクションを返すagentという関数を実装する必要がある。上で学習したモデルの入力は論文中で言うところの"SMM stacked"(72 x 96 x 4のSuper Mini Mapを時間軸でさらに4つ重ねたもの)であり、これはagent関数に与えられる観測とは異なるので、自前で観測を変換する必要があった。この部分はSEED RLのNotebookで示されていた例をベースに実装できた。
コンペに学習済みモデルを提出するにはモデルとメインのスクリプトを組み合わせたsubmission.tar.gzを作る必要がある。提出先の実行環境でモデルをファイルから読み込む際のパスをどうすれば良いか明確ではなかったが、Discussionに/kaggle_simulations/agentにファイルが展開されると書いてあったのでそれにならった。
そうしてようやく提出したが、残念ながらValidation Errorとなってしまった。理由は単純で提出先の環境では外部ライブラリのbaselinesが存在しなかったため。Notebookの環境ではpipで好きなライブラリを入れられるため、提出先でも大丈夫だろうと高を括っていたが、当然ダメだった。調べてみると、stickytapeというライブラリを使いライブラリのコード自体をsubmission.pyに含めるという方法もあるようだったが(Notebook)、これ以上調べるのも面倒だったのでここで断念。おそらく正当なやり方としては、学習済みモデルをbaselinesを通して読み込むのではなく、TensorFlowで直接読めば良いのだと思うが、学習環境のTensorFlowが1.15を使っていたので実行環境とのバージョンの互換性が大丈夫かは自信が無い。
今後の展望
残念ながら強化学習モデルの提出までは至らなかったが、Kaggleへの初参加、そしてGPUを用いたサッカーゲームの強化学習を始めることが出来て、満足している。ただ、今のところ用意されたスクリプトで学習をしただけなので、ここから色々と試していきたい。いくつかの方針として
- ボール奪取にも報酬を与えることで、ディフェンスの学習効率をあげる
- 学習の進度に応じてゲームの難易度を上げていくカリキュラムラーニング
- SEED RLを試してみる
などなど。また、理論面もまだまだで、例えば今回使用したPPOについてもよく理解していないので、Pythonで学ぶ強化学習を読み切り、力をつけておきたいと思う。
この記事が気に入ったらサポートをしてみませんか?