G検定 / 統計検定 データの集計 #4

株式会社リュディアです。前回に引き続きデータの集計についてまとめていきます。
前回までのG検定 / 統計検定 データの集計のまとめへのリンクは以下を参考にしてください。
今回もデータのばらつきを扱う指標である分散と標準偏差についてまとめてみます。前回のまとめで平均絶対偏差についてまとめてみました。各データと平均の差のことを偏差と呼びます。偏差は正負の値を取りうるため、偏差の平均をとるとゼロになってしまい何の情報も得られません。
そこで平均絶対偏差では偏差の絶対値をとった後で平均をとりました。要は偏差に負の数があるので絶対値を使って正の数にしたわけです。絶対値を使う代わりに2乗することで正の数のみにできます。これが分散の考え方です。では順に見いていきましょう。前回と同じデータを使いますので、まず前回使った平均絶対偏差を含むデータを以下につけておきます。

では分散の説明に入っていきます。目的は偏差の負の数を無くすこと、そのために偏差を2乗して平均をとるのが分散の考え方です。偏差の2乗を計算してその平均を計算してみます。以下の表を見てください。
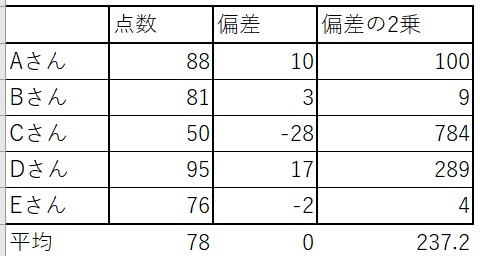
偏差の2乗は当然すべて正の数となりその平均 237.2 が分散となります。これで目標は達成したわけですが分散の欠点として2乗したことで数字が大きくなりすぎて何を表しているのかわかりづらくなることがあげられます。そこで分散のルートを取った値を標準偏差と定義します。この場合であれば 237.2 のルートをとるので標準偏差は 15.4 になります。標準偏差を表す記号は一般にσ(小文字のシグマ)を使います。
標準偏差が分散に比べて優れているのは以下の点です。
1. 元データと同じ次元を持つ。分散は元データの2乗の次元を持つことに注意。
2. 元データと同じ次元なので「ばらつきを表現している」と言われた場合に直感的に理解しやすい。
標準偏差自体の詳細な意味は正規分布についてまとめてから行いますので今回はここまでとします。
G検定 / 統計検定 データの集計に関するまとめの続きは以下からどうぞ。
では、ごきげんよう。
この記事が気に入ったらサポートをしてみませんか?